أبحاث رؤى Gate Ventures: الحرب الثالثة للمتصفحات: معركة الدخول في عصر الوكيل الذكي
TL;DR
تت unfold الحرب الثالثة على المتصفح بهدوء. عند النظر إلى التاريخ، من Netscape و Internet Explorer التابع لشركة Microsoft في التسعينيات إلى Firefox مفتوح المصدر و Chrome من Google، كانت الحرب على المتصفح دائمًا تجسيدًا مركّزًا للتحكم في المنصات والتحولات التكنولوجية. لقد ضمنت Chrome موقعها المهيمن بفضل سرعة تحديثها السريعة ونظامها البيئي المتكامل، بينما شكلت Google، من خلال احتكارها للبحث والمتصفح، حلقة مغلقة من الوصول إلى المعلومات.
لكن اليوم، هذا المشهد يهتز. إن صعود نماذج اللغة الكبيرة (LLMs) يمكّن المزيد والمزيد من المستخدمين من إكمال المهام دون النقر على صفحة نتائج البحث، بينما تتناقص النقرات على صفحات الويب التقليدية. في الوقت نفسه، فإن الشائعات التي تفيد بأن Apple تعتزم استبدال محرك البحث الافتراضي في Safari تهدد بشكل أكبر قاعدة أرباح Alphabet (الشركة الأم لجوجل)، والسوق بدأ يعبر عن عدم ارتياحه بشأن "أرثوذكسية البحث."
يواجه المتصفح نفسه أيضًا إعادة تشكيل لدوره. لم يعد مجرد أداة لعرض صفحات الويب، بل أصبح أيضًا حاوية للعديد من القدرات، بما في ذلك إدخال البيانات، وسلوك المستخدم، والهوية الخاصة. في حين أن وكلاء الذكاء الاصطناعي قويون، إلا أنهم لا يزالون يعتمدون على حدود ثقة المتصفح وصندوقه الوظيفي لإكمال التفاعلات المعقدة مع الصفحات، والوصول إلى بيانات الهوية المحلية، والتحكم في عناصر صفحة الويب. المتصفحات تتطور من واجهات بشرية إلى منصات استدعاء نظام للوكلاء.
في هذه المقالة، نستكشف ما إذا كانت المتصفحات لا تزال ضرورية. نحن نعتقد أن ما يمكن أن ي disrupt حقاً مشهد سوق المتصفحات الحالي ليس "كروم" أفضل، ولكن هيكل تفاعل جديد: ليس مجرد عرض المعلومات، ولكن استدعاء المهام. يجب تصميم المتصفحات المستقبلية لوكلاء الذكاء الاصطناعي - القادرين ليس فقط على القراءة، ولكن أيضاً على الكتابة والتنفيذ. تحاول مشاريع مثل استخدام المتصفح تحويل بنية الصفحة إلى دلالات، وتحويل الواجهات المرئية إلى نصوص منظمة قابلة للاستدعاء بواسطة LLM، ورسم الصفحات إلى أوامر وتقليل تكاليف التفاعل بشكل كبير.
تقوم المشاريع الكبرى بالفعل باختبار المياه: تقوم Perplexity ببناء متصفح أصلي، Comet، الذي يستبدل نتائج البحث التقليدية بالذكاء الاصطناعي؛ وBrave تجمع بين حماية الخصوصية والتفكير المحلي، باستخدام LLM لتعزيز قدرات البحث والحظر؛ والمشاريع الأصلية في مجال التشفير مثل Donut تستهدف نقاط دخول جديدة للذكاء الاصطناعي للتفاعل مع الأصول على السلسلة. سمة شائعة بين هذه المشاريع هي محاولتها إعادة تشكيل طبقة الإدخال في المتصفح، بدلاً من تحسين طبقة الإخراج.
بالنسبة لرجال الأعمال، تكمن الفرص ضمن مثلث المدخلات، الهيكل، والوصول إلى الوكلاء. باعتبارها الواجهة لعالم الوكلاء المستقبلي، يعني المتصفح أن من يمكنه توفير "قدرات" منظمة، قابلة للاستدعاء، وموثوقة سيصبح جزءًا من المنصة القادمة من الجيل الجديد. من تحسين محركات البحث إلى تحسين محرك الوكلاء (AEO)، ومن حركة مرور الصفحات إلى استدعاء سلاسل المهام، يتم إعادة تشكيل شكل المنتج والتفكير التصميمي. تدور الحرب الثالثة للمتصفحات حول "المدخلات" بدلاً من "العرض". لم يعد النصر يتحدد من يلتقط انتباه المستخدم، ولكن من يكسب ثقة الوكيل ويكتسب الوصول.
تاريخ موجز لتطوير المتصفح
في أوائل التسعينيات، قبل أن تصبح الإنترنت جزءًا من الحياة اليومية، ظهرت متصفح نتسكيب نافيجيتور على الساحة، كقارب شراعي فتح الباب للعالم الرقمي لملايين المستخدمين. وعلى الرغم من أنه لم يكن أول متصفح، إلا أنه كان الأول الذي وصل حقًا إلى الجماهير وشكل تجربة الإنترنت. للمرة الأولى، كان بإمكان الناس تصفح الويب بسهولة من خلال واجهة رسومية، كما لو أن العالم بأسره قد أصبح فجأة في متناول اليد.
ومع ذلك، فإن المجد غالبًا ما يكون قصير الأجل. أدركت مايكروسوفت بسرعة أهمية المتصفحات وقررت تضمين إنترنت إكسبلورر في نظام التشغيل ويندوز بشكل قسري، مما جعله المتصفح الافتراضي. كانت هذه الاستراتيجية، "قاتل المنصات" الحقيقي، تضعف مباشرة من هيمنة نتسكيب في السوق. لم يختر العديد من المستخدمين إنترنت إكسبلورر بنشاط؛ بل قبلوا ببساطة أنه المتصفح الافتراضي. من خلال الاستفادة من قدرات توزيع ويندوز، أصبح إنترنت إكسبلورر سريعًا رائد الصناعة، بينما تراجعت نتسكيب.

في خضم الشدائد، اختار مهندسو نيتسكيب مسارًا جذريًا ومثاليًا - حيث فتحوا شفرة المصدر للمتصفح واستدعوا مجتمع المصدر المفتوح. كانت هذه القرار بمثابة "تنازل مقدوني" في عالم التكنولوجيا، مما أشعل نهاية عهد قديم وظهور قوى جديدة. أصبحت تلك الشفرة في وقت لاحق أساس مشروع متصفح موزيلا، الذي سمي في البداية فينيكس (رمزًا للولادة من جديد)، ولكن بعد عدة نزاعات حول العلامات التجارية، تم إعادة تسميته أخيرًا إلى فايرفوكس.
لم يكن فايرفوكس مجرد نسخة من نتسكيب. بل حقق إنجازات في تجربة المستخدم، ونظم الإضافات، والأمان. ولدت هذه المتصفح لتكون انتصارا لروح المصدر المفتوح وأدخلت حيوية جديدة في الصناعة بأكملها. وصفه البعض بأنه "الخليفة الروحي" لنتسكيب، على غرار كيفية وراثة الإمبراطورية العثمانية لمجد بيزنطة المتلاشي. على الرغم من أنه مبالغ فيه، إلا أن المقارنة تحمل معنى.
ومع ذلك، قبل أن يتم إصدار فايرفوكس رسميًا، كانت مايكروسوفت قد أطلقت بالفعل ست نسخ من إنترنت إكسبلورر. من خلال الاستفادة من توقيتها المبكر واستراتيجيتها في تجميع النظام، وُضعت فايرفوكس في موقف متأخر منذ البداية، مما ضمن أن هذه المنافسة لم تكن أبدًا منافسة متكافئة تبدأ من نفس الخط.
في نفس الوقت، دخل لاعب مبكر آخر إلى الساحة بهدوء. في عام 1994، وُلِد متصفح أوبرا في النرويج، وكان في البداية مجرد مشروع تجريبي. ولكن بدءًا من الإصدار 7.0 في عام 2003، قدم محركه المطور ذاتيًا "بريستو"، رائدًا الدعم لـ CSS، والتخطيطات التكيفية، والتحكم الصوتي، والترميز اليونيكود. على الرغم من أن قاعدة مستخدميه كانت محدودة، إلا أنه قاد الصناعة تقنيًا باستمرار، ليصبح "المفضل لدى المهووسين."
في نفس العام، أطلقت Apple متصفح Safari - وهو نقطة تحول ذات مغزى. في ذلك الوقت، كانت مايكروسوفت قد استثمرت 150 مليون دولار في Apple التي كانت تعاني من صعوبات للحفاظ على مظهر من المنافسة وتجنب التدقيق في قضايا مكافحة الاحتكار. على الرغم من أن محرك البحث الافتراضي لـ Safari كان Google منذ البداية، إلا أن هذه العلاقات المعقدة والدقيقة مع مايكروسوفت رمَزت إلى العلاقات المعقدة والدقيقة بين عمالقة الإنترنت: التعاون والمنافسة، دائمًا ما تكون متشابكة.
في عام 2007، تم إصدار IE7 جنبًا إلى جنب مع نظام التشغيل ويندوز فيستا، لكن ردود فعل السوق كانت فاترة. من ناحية أخرى، زادت حصة فايرفوكس في السوق بشكل مطرد لتصل إلى حوالي 20%، بفضل دورات التحديث الأسرع، وآلية الإضافات الأكثر سهولة في الاستخدام، والجاذبية الطبيعية للمطورين. بدأت هيمنة IE في التراجع، وبدأت الرياح تتغير.
ومع ذلك، اتخذت جوجل نهجًا مختلفًا. على الرغم من أنها كانت تخطط لمتصفحها الخاص منذ عام 2001، استغرق الأمر ست سنوات لإقناع الرئيس التنفيذي إريك شميدت بالموافقة على المشروع. ظهر كروم في عام 2008، مبنيًا على مشروع كروميوم مفتوح المصدر ومحرك ويب كيت المستخدم في سفاري. تم السخرية منه كمتصفح "ممتلئ"، ولكن مع خبرة جوجل العميقة في الإعلانات وبناء العلامات التجارية، ارتفع بسرعة.
كانت السلاح الرئيسي لـ Chrome ليس ميزاته، ولكن دورة التحديث المتكررة له (كل ستة أسابيع) وتجربة موحدة عبر المنصات. في نوفمبر 2011، تجاوز Chrome Firefox للمرة الأولى، حيث وصل إلى حصة سوقية تبلغ 27٪؛ وبعد ستة أشهر، تجاوز IE، مكتملًا تحوله من منافس إلى قائد مهيمن.
في الوقت نفسه، كانت الإنترنت المحمولة في الصين تشكل نظامها البيئي الخاص. ارتفعت شعبية متصفح UC الخاص بشركة علي بابا في أوائل العقد الأول من القرن الحادي والعشرين، خاصة في الأسواق الناشئة مثل الهند وإندونيسيا والصين. بفضل تصميمه الخفيف وميزاته لضغط البيانات التي توفر عرض النطاق الترددي، تمكن من كسب المستخدمين على الأجهزة ذات المواصفات المنخفضة. بحلول عام 2015، تجاوزت حصته في سوق المتصفحات المحمولة العالمية 17%، وفي الهند وصلت في مرحلة ما إلى 46%. لكن هذا الانتصار لم يكن طويل الأمد. مع تشديد الحكومة الهندية لمراجعات الأمن على التطبيقات الصينية، تم إجبار متصفح UC على الخروج من الأسواق الرئيسية، مما أدى إلى فقدانه تدريجياً لمجده السابق.
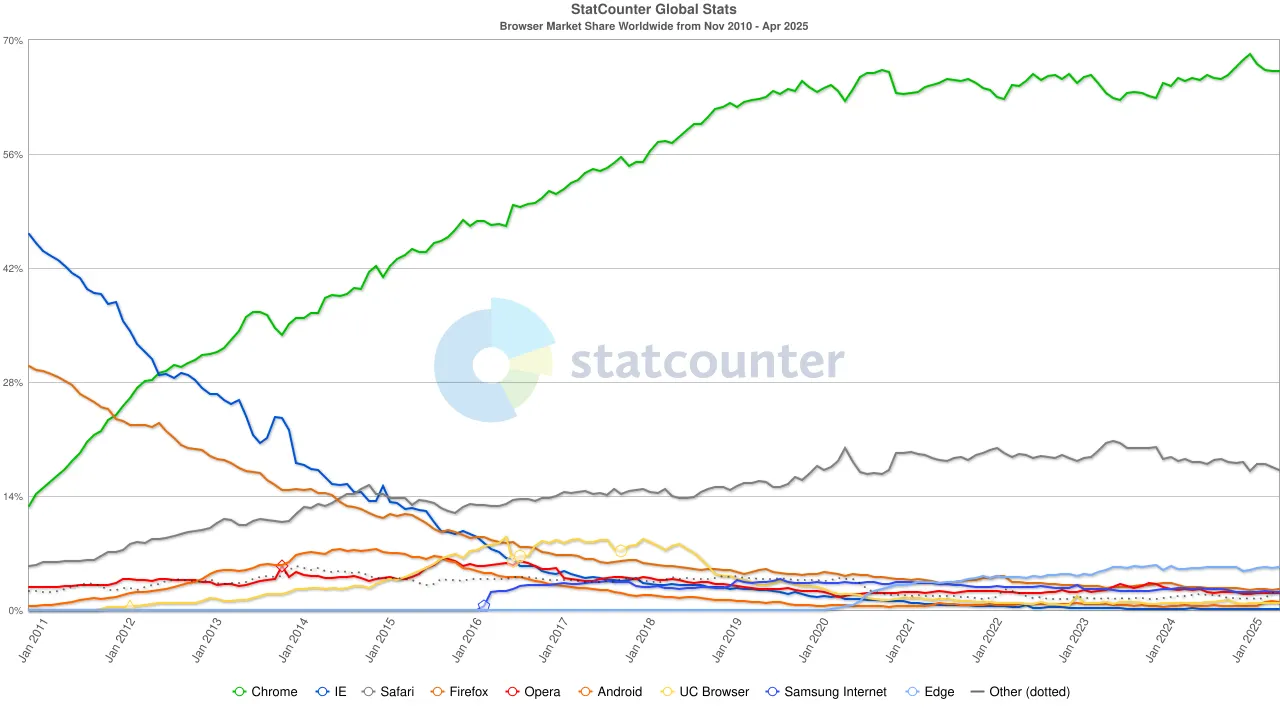
بحلول عقد 2020، كانت هيمنة كروم قد تم ترسيخها، حيث استقر حصتها في السوق العالمية عند حوالي 65%. من الجدير بالذكر أنه على الرغم من أن محرك بحث جوجل ومتصفح كروم كلاهما ينتميان إلى ألفابت، إلا أنهما من منظور السوق يمثلان هيمنتين مستقلتين - حيث يتحكم الأول في حوالي 90% من حركة البحث العالمية، بينما يعمل الثاني ك"النافذة الأولى" التي من خلالها يصل معظم المستخدمين إلى الإنترنت.
للحفاظ على هذه الهيكلية المزدوجة، لم تدخر جوجل أي نفقات. في عام 2022، دفعت ألفابت لشركة آبل حوالي 20 مليار دولار فقط للحفاظ على جوجل كأداة البحث الافتراضية في سفاري. وقد أشار المحللون إلى أن هذه النفقات كانت تمثل حوالي 36% من إيرادات الإعلانات البحثية التي حققتها جوجل من حركة المرور على سفاري. بعبارة أخرى، كانت جوجل تدفع فعليًا "رسوم حماية" للدفاع عن خندقها.
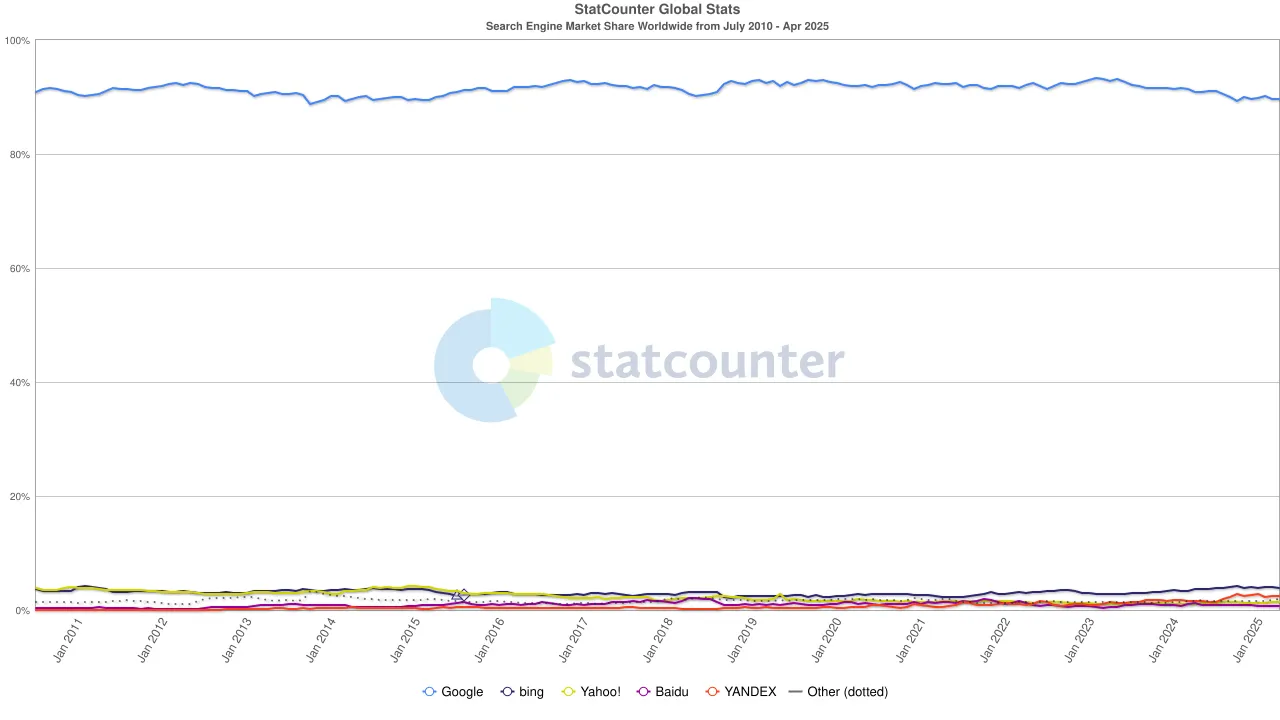
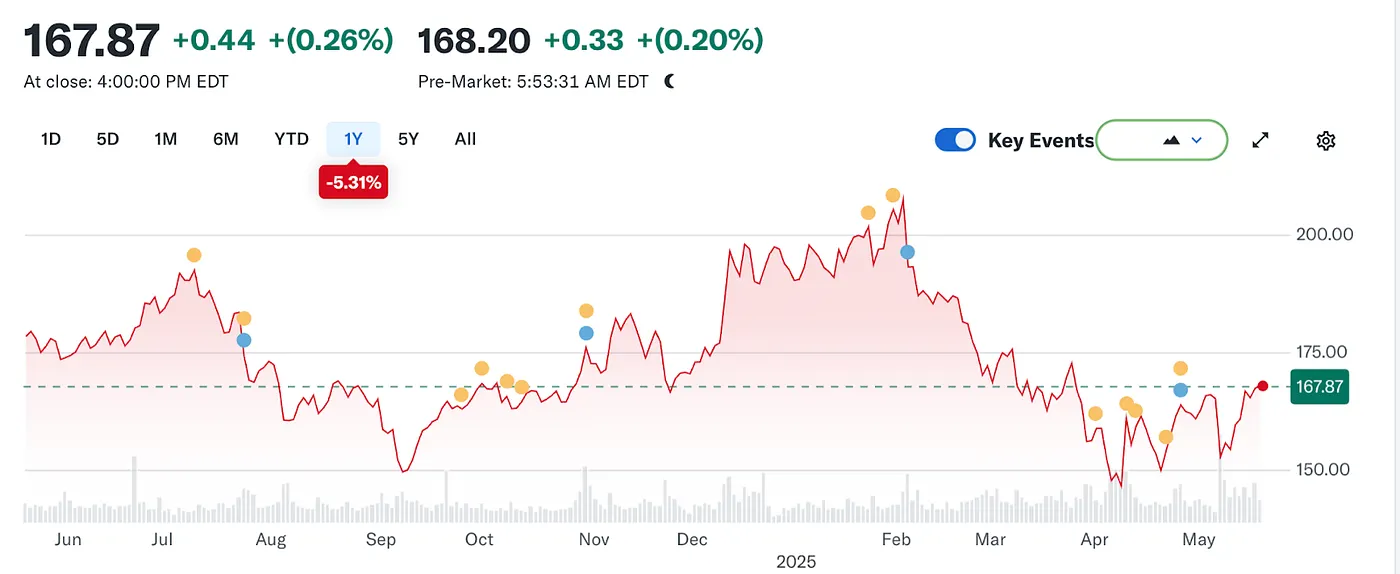
لكن المد قد تغير مرة أخرى. مع ارتفاع نماذج اللغة الكبيرة (LLMs)، بدأت عمليات البحث التقليدية تشعر بالتأثير. في عام 2024، انخفضت حصة Google في سوق البحث من 93% إلى 89%. على الرغم من أنها لا تزال تهيمن، كانت الشقوق تبدأ في الظهور. وما كان أكثر إزعاجًا هي الشائعات بأن Apple قد تطلق محرك بحث مدعوم بالذكاء الاصطناعي خاص بها. إذا كانت عمليات البحث الافتراضية في Safari ستتحول إلى النظام البيئي الخاص بـ Apple، فلن تعيد تشكيل المشهد التنافسي فحسب، بل قد تهز أيضًا الأساس الذي تعتمد عليه أرباح Alphabet. تفاعلت السوق بسرعة: انخفض سعر سهم Alphabet من 170 دولارًا إلى 140 دولارًا، مما يعكس ليس فقط ذعر المستثمرين ولكن أيضًا قلقًا عميقًا بشأن الاتجاه المستقبلي لعصر البحث.
من نافذة إلى كروم، من المثالية المصدر المفتوح إلى التجارة المدفوعة بالإعلانات، من المتصفحات الخفيفة إلى مساعدي البحث المدعومين بالذكاء الاصطناعي، كانت معركة المتصفحات دائمًا حربًا على التكنولوجيا، والأنظمة الأساسية، والمحتوى، والسيطرة. ساحة المعركة تستمر في التحول، ولكن الجوهر لم يتغير أبدًا: من يتحكم في Gate يحدد المستقبل.
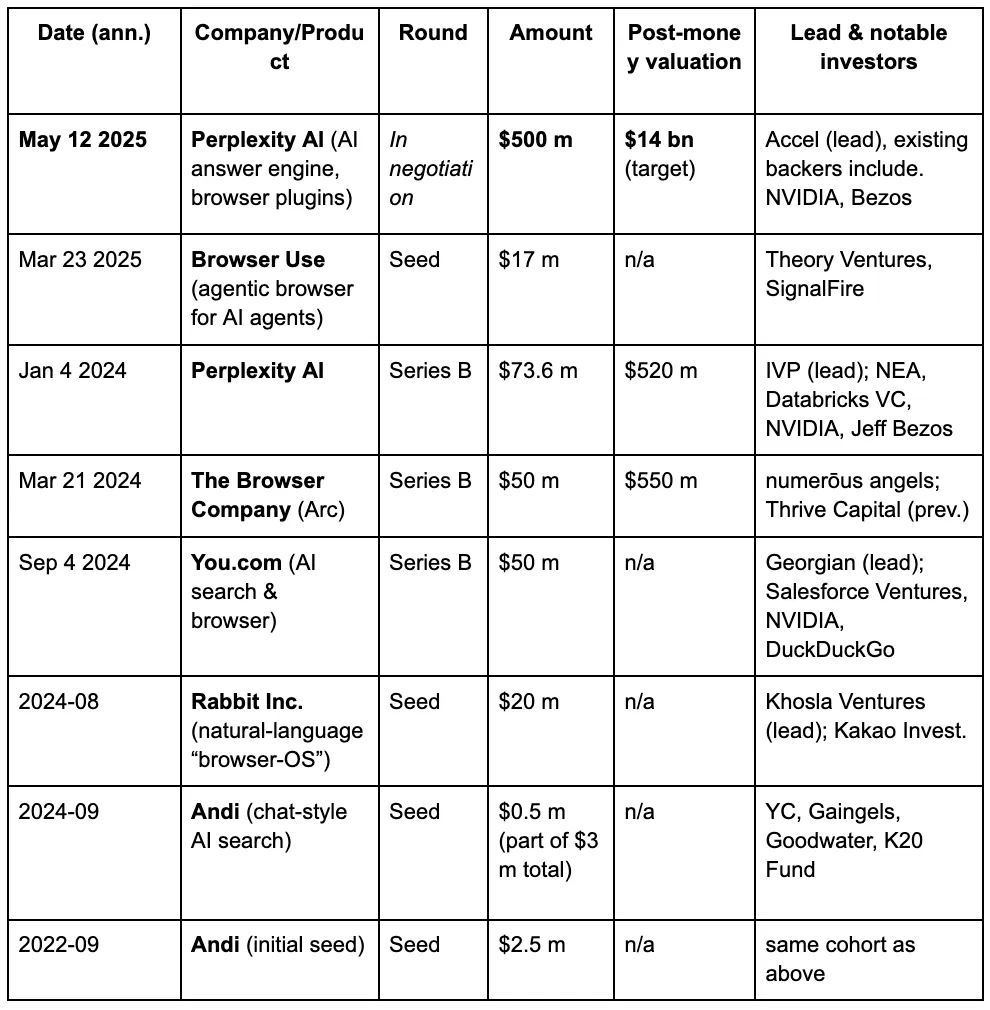
في عيون المستثمرين في رأس المال المغامر، تتكشف حرب المتصفحات الثالثة تدريجياً، مدفوعة بالمطالب الجديدة التي يضعها الناس على محركات البحث في عصر LLMs و AI. فيما يلي تفاصيل التمويل لبعض المشاريع المعروفة في مسار متصفح AI.
الهندسة المعمارية القديمة لمتصفحات الويب الحديثة
عندما يتعلق الأمر بهندسة المتصفح، فإن الهيكل التقليدي الكلاسيكي موضح في الرسم البياني أدناه:
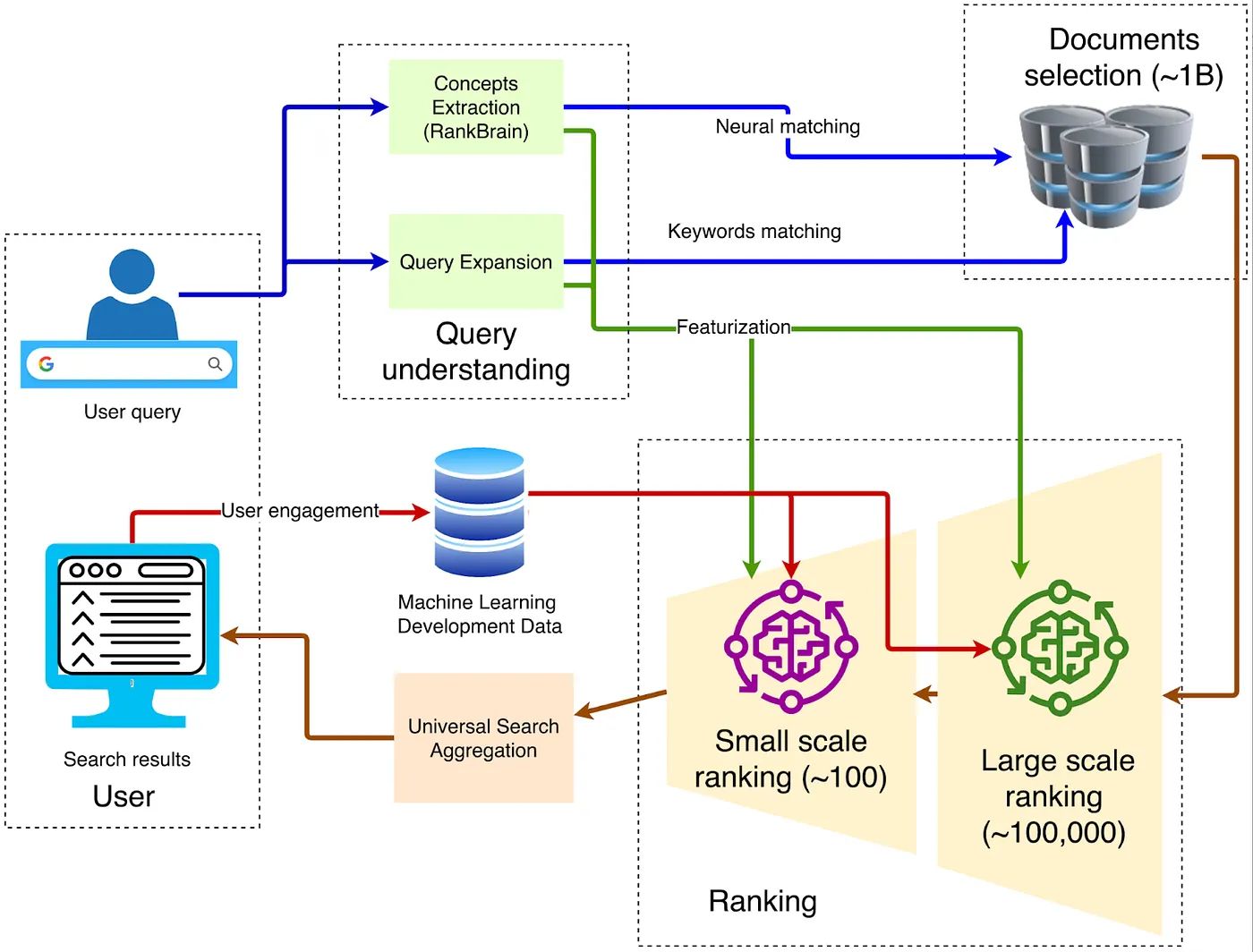
1. العميل - واجهة الإدخال الأمامية
يتم إرسال الاستعلام عبر HTTPS إلى أقرب واجهة أمامية من Google، حيث يتم إجراء فك تشفير TLS، وعينات جودة الخدمة، والتوجيه الجغرافي. إذا تم اكتشاف حركة مرور غير طبيعية (مثل هجمات DDoS أو التجريف الآلي)، يمكن تطبيق قيود على المعدل أو تحديات في هذه الطبقة.
2. فهم الاستعلام
يجب أن يفهم الواجهة الأمامية معنى الكلمات التي كتبها المستخدم. يتضمن ذلك ثلاث خطوات:
تصحيح الإملاء العصبي، مثل تحويل "recpie" إلى "recipe".
توسيع المرادفات، على سبيل المثال توسيع "كيفية إصلاح الدراجة" لتشمل "إصلاح الدراجة الهوائية".
تحليل النية، الذي يحدد ما إذا كانت الاستعلامات معلوماتية أو تنقلية أو تجارية، ثم يخصص الطلب العمودي المناسب.
3. استرجاع المرشحين
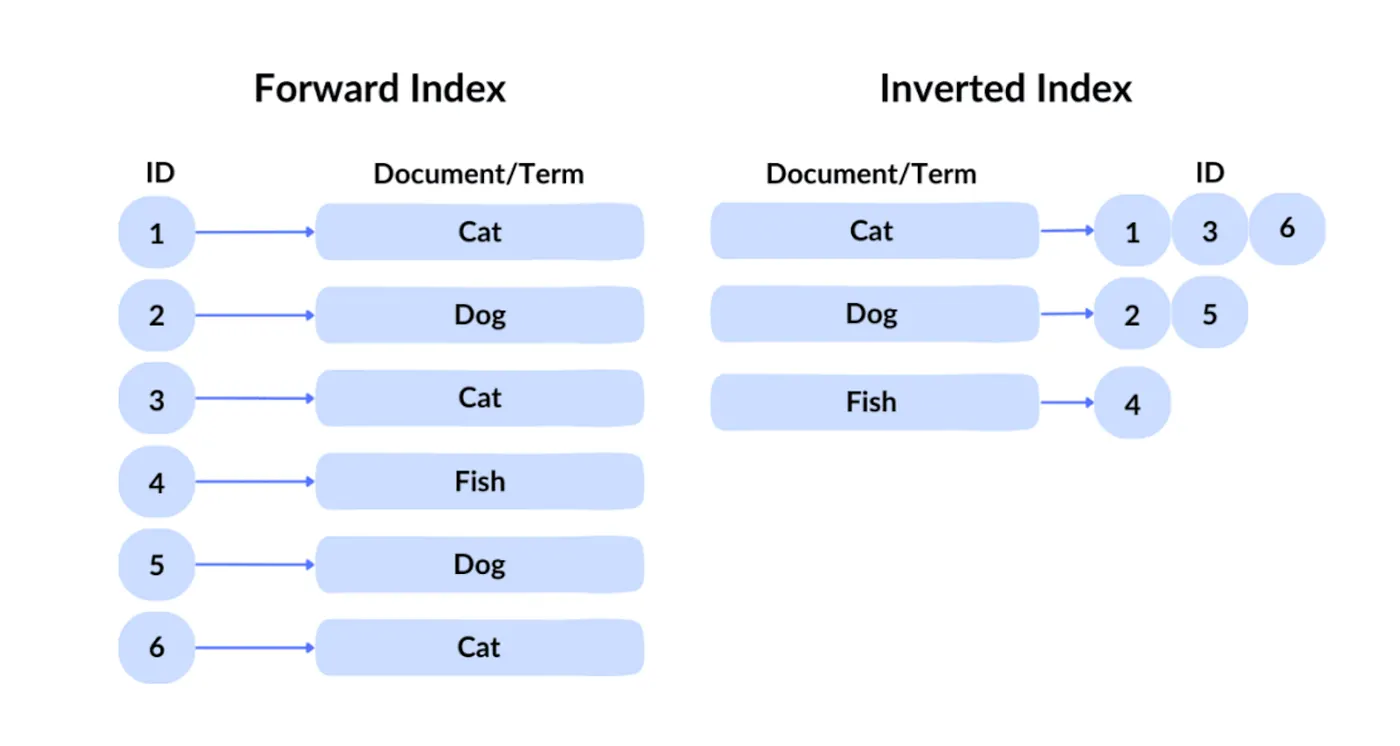
تُعرف تقنية استعلام جوجل بفهرس معكوس. في الفهرس الأمامي، تسترجع ملفًا بناءً على معرّفه. ولكن نظرًا لأن المستخدمين لا يمكنهم معرفة معرّفات المحتوى المرغوب فيه عبر مئات المليارات من الملفات، تستخدم جوجل الفهرس المعكوس التقليدي، الذي يستعلم عن المحتوى لتحديد الملفات التي تحتوي على الكلمات الرئيسية المقابلة.
بعد ذلك، تستخدم Google فهرسة المتجهات للتعامل مع البحث الدلالي - أي، العثور على محتوى مشابه في المعنى للاستعلام. تقوم بتحويل النصوص والصور والمحتويات الأخرى إلى متجهات عالية الأبعاد (تمثيلات)، ثم تبحث بناءً على التشابه بين تلك المتجهات. على سبيل المثال، إذا بحث المستخدم عن "كيفية صنع عجينة البيتزا"، يمكن لمحرك البحث أن يُرجع نتائج تتعلق بـ "دليل تحضير عجينة البيتزا"، لأن الاثنين متشابهان دلالياً.
من خلال الفهرسة المعكوسة وفهرسة المتجهات، يتم تصفية حوالي مئات الآلاف من صفحات الويب في مرحلة الفرز الأولية.
4. التصنيف متعدد المراحل
عادةً ما يستخدم النظام آلاف الميزات الخفيفة مثل BM25 و TF-IDF ودرجات جودة الصفحة لتقليل مئات الآلاف من صفحات المرشحين إلى حوالي 1,000، مشكلاً مجموعة أولية من المرشحين. تُعرف هذه الأنظمة مجتمعة باسم محركات التوصية. تعتمد على ميزات ضخمة تم إنشاؤها من كيانات مختلفة، بما في ذلك سلوك المستخدم وسمات الصفحة ونية الاستعلام والإشارات السياقية. على سبيل المثال، تجمع Google بين تاريخ المستخدم، والتعليقات من مستخدمين آخرين، ودلالات الصفحة، ومعنى الاستعلام، مع الأخذ في الاعتبار أيضًا العناصر السياقية مثل الوقت (وقت اليوم، يوم الأسبوع) والأحداث الخارجية مثل الأخبار العاجلة.
5. التعلم العميق للتصنيف الأولي
في مرحلة الاسترجاع الأولية، تستخدم Google تقنيات مثل RankBrain و Neural Matching لفهم دلالات الاستفسارات وتصنيف أكثر النتائج صلة من مجموعات الوثائق الضخمة.
رانك برين، الذي قدمته جوجل في عام 2015، هو نظام تعلم آلي مصمم لفهم معنى استفسارات المستخدمين بشكل أفضل، وخاصة الاستفسارات التي لم تُرَ من قبل. يقوم بتحويل الاستفسارات والمستندات إلى تمثيلات متجهية ويحسب تشابهها للعثور على النتائج الأكثر صلة. على سبيل المثال، للاستفسار "كيفية صنع عجينة البيتزا"، حتى لو لم يحتوي أي مستند على تطابق دقيق للكلمات الرئيسية، يمكن لرانك برين تحديد المحتوى المتعلق بـ "أساسيات البيتزا" أو "تحضير العجين."
تم تصميم Neural Matching، الذي أطلق في عام 2018، لالتقاط العلاقة الدلالية بين الاستفسارات والمستندات بشكل أفضل. باستخدام نماذج الشبكات العصبية، يحدد العلاقات الضبابية بين الكلمات لمطابقة الاستفسارات بمحتوى الويب بشكل أفضل. على سبيل المثال، بالنسبة للاستفسار "لماذا يكون مروحة جهازي المحمول مرتفعة الصوت"، يمكن لـ Neural Matching أن يفهم أن المستخدم قد يبحث عن معلومات استكشاف الأخطاء وإصلاحها حول ارتفاع درجة الحرارة أو تراكم الغبار أو ارتفاع استخدام وحدة المعالجة المركزية - حتى لو لم تظهر هذه المصطلحات بشكل صريح في الاستفسار.
6. إعادة ترتيب عميق: تطبيق BERT
بعد التصفية الأولية للمستندات ذات الصلة، تقوم Google بتطبيق BERT (تمثيلات الترميز ثنائية الاتجاه من المحولات) لتحسين الترتيب وضمان ظهور النتائج الأكثر صلة في الأعلى. BERT هو نموذج لغوي مدرب مسبقًا يعتمد على المحولات يمكنه فهم العلاقات السياقية للكلمات داخل الجمل.
في البحث، يتم استخدام BERT لإعادة ترتيب الوثائق المسترجعة في المراحل السابقة. إنه يقوم بتشفير الاستعلامات والوثائق بشكل مشترك، ويحسب درجات ملاءمتها، ثم يعيد ترتيب الوثائق. على سبيل المثال، للاستعلام "ركن السيارة على تل بدون رصيف"، يمكن لـ BERT أن يفسر بشكل صحيح معنى "بدون رصيف" ويعيد النتائج التي تنصح السائقين بتوجيه عجلاتهم نحو جانب الطريق، بدلاً من تفسيرها بشكل خاطئ كحالة بها رصيف.
بالنسبة لمهندسي تحسين محركات البحث، فهذا يعني أنهم يجب أن يدرسوا بعناية خوارزميات التصنيف الخاصة بجوجل وخوارزميات التوصية المعتمدة على التعلم الآلي من أجل تحسين محتوى الويب بطريقة مستهدفة، وبالتالي تحقيق رؤية أعلى في تصنيفات البحث.
لماذا ستعيد الذكاء الاصطناعي تشكيل المتصفحات
أولاً، نحتاج إلى توضيح: لماذا لا يزال شكل المتصفح بحاجة إلى الوجود؟ هل هناك نموذج ثالث يتجاوز وكلاء الذكاء الاصطناعي والمتصفحات؟
نعتقد أن الوجود يعني عدم القابلية للاستبدال. لماذا يمكن للذكاء الاصطناعي استخدام المتصفحات ولكن لا يمكنه استبدالها بالكامل؟ لأن المتصفح هو منصة شاملة. إنه ليس فقط نقطة دخول لقراءة البيانات ولكنه أيضًا نقطة دخول عامة لإدخال البيانات. لا يمكن للعالم أن يستهلك المعلومات فقط - بل يجب أيضًا أن ينتج البيانات ويتفاعل مع المواقع. لذلك، ستستمر المتصفحات التي تدمج معلومات المستخدمين الشخصية في الوجود على نطاق واسع.
إليك النقطة الرئيسية: كمدخل عالمي، المتصفح ليس فقط لقراءة البيانات؛ غالبًا ما يحتاج المستخدمون إلى التفاعل مع البيانات. المتصفح نفسه هو مستودع ممتاز لتخزين بصمات أصابع المستخدم. يجب أن تتم السلوكيات الأكثر تعقيدًا للمستخدم والإجراءات الآلية من خلال المتصفح. يمكن للمتصفح تخزين جميع بصمات السلوكيات الخاصة بالمستخدم، ومعلومات الاعتماد، وغيرها من المعلومات الخاصة، مما يمكّن من الاستدعاء بدون ثقة أثناء الأتمتة. قد يتطور التفاعل مع البيانات إلى هذا النمط:
المستخدم → يتصل بوكيل الذكاء الاصطناعي → المتصفح.
بعبارة أخرى، الجزء الوحيد الذي يمكن استبداله يكمن في الاتجاه الطبيعي للعالم - نحو مزيد من الذكاء، والتخصيص، والأتمتة. يجب أن نكون متأكدين من أن هذا الجزء يمكن أن تتعامل معه وكلاء الذكاء الاصطناعي. لكن وكلاء الذكاء الاصطناعي أنفسهم ليسوا مؤهلين بشكل جيد لحمل محتوى المستخدم المخصص، لأنهم يواجهون تحديات متعددة تتعلق بأمان البيانات وقابلية الاستخدام. بشكل محدد:
المتصفح هو مستودع للمحتوى المخصص:
تستضيف معظم النماذج الكبيرة في السحابة، مع اعتماد سياقات الجلسة على تخزين الخادم، مما يجعل من الصعب الوصول مباشرة إلى كلمات المرور المحلية، والمحافظ، وملفات تعريف الارتباط، والبيانات الحساسة الأخرى.
يتطلب إرسال جميع بيانات التصفح والدفع إلى نماذج الطرف الثالث تجديد تفويض المستخدم؛ حيث تطالب كل من لائحة DMA في الاتحاد الأوروبي وقوانين الخصوصية على مستوى الولايات المتحدة بتقليل البيانات عبر الحدود.
يجب أن تتم جميع عمليات ملء رموز المصادقة الثنائية تلقائيًا، واستدعاء الكاميرات، أو استخدام وحدات معالجة الرسومات لتفسير WebGPU داخل صندوق متصفح.
سياق البيانات يعتمد بشكل كبير على المتصفح. يتم تخزين علامات التبويب، والكوكيز، وIndexedDB، وService Worker Cache، وبيانات اعتماد المفتاح، وبيانات الإضافات جميعها داخل المتصفح.
تغييرات عميقة في أشكال التفاعل
بالعودة إلى الموضوع من البداية، يمكن عمومًا تقسيم سلوكنا عند استخدام المتصفحات إلى ثلاث فئات: قراءة البيانات، إدخال البيانات، والتفاعل مع البيانات. لقد غيرت النماذج اللغوية الكبيرة (LLMs) بالفعل بشكل عميق الكفاءة والأساليب التي نقرأ بها البيانات. يبدو أن الممارسة القديمة للمستخدمين في البحث عن صفحات الويب من خلال الكلمات الرئيسية أصبحت الآن قديمة وغير فعالة.
عندما يتعلق الأمر بتطور سلوك البحث لدى المستخدمين - سواء كان الهدف هو الحصول على إجابات ملخصة أو النقر على صفحات الويب - فقد قامت العديد من الدراسات بالفعل بتحليل هذا التحول.
فيما يتعلق بأنماط سلوك المستخدمين، أظهرت دراسة في عام 2024 أنه في الولايات المتحدة، من بين كل 1,000 استعلام على جوجل، انتهى 374 فقط بنقرة على صفحة ويب مفتوحة. بعبارة أخرى، كان ما يقرب من 63% من التصرفات "بدون نقر". لقد اعتاد المستخدمون على الحصول على معلومات مثل الطقس، وأسعار الصرف، وبطاقات المعرفة مباشرة من صفحة نتائج البحث.
ما يمكن أن يتسبب حقًا في تحويل ضخم للمتصفحات هو طبقة التفاعل مع البيانات. في الماضي، كان الناس يتفاعلون مع المتصفحات بشكل أساسي من خلال إدخال الكلمات الرئيسية - أعلى مستوى من الفهم الذي يمكن أن تتعامل معه المتصفح نفسه. الآن، يفضل المستخدمون بشكل متزايد استخدام اللغة الطبيعية الكاملة لوصف المهام المعقدة، مثل:
"ابحث لي عن رحلات مباشرة من نيويورك إلى لوس أنجلوس خلال فترة معينة."
"ابحث لي عن رحلة من نيويورك إلى شنغهاي ثم إلى لوس أنجلوس."
حتى بالنسبة للبشر، تتطلب مثل هذه المهام الكثير من الوقت لزيارة مواقع متعددة، وجمع المعلومات، ومقارنة النتائج. لكن هذه المهام الوكيلة تُستولى عليها تدريجيًا من قبل وكلاء الذكاء الاصطناعي.
هذا يتماشى أيضًا مع مسار التاريخ: الأتمتة والذكاء. يرغب الناس في تحرير أيديهم، وسيتم دمج وكلاء الذكاء الاصطناعي بشكل عميق في المتصفحات. يجب تصميم المتصفحات المستقبلية مع وضع الأتمتة الكاملة في الاعتبار، خاصة بالنظر إلى:
كيف نوازن تجربة القراءة للبشر مع قابلية الفهم الآلي لوكلاء الذكاء الاصطناعي.
كيف تضمن أن صفحة ويب واحدة تخدم كل من المستخدم النهائي ونموذج الوكيل.
فقط من خلال تلبية كلا هذين الشرطين التصميميين يمكن للمتصفحات أن تصبح حقًا وسائط مستقرة لوكالات الذكاء الاصطناعي لتنفيذ المهام.
بعد ذلك، سنركز على خمسة مشاريع بارزة—استخدام المتصفح، آرك (شركة المتصفح)، بيربلكستي، برايف، ودونات. تمثل هذه المشاريع الاتجاهات المستقبلية لتطور متصفح الذكاء الاصطناعي، فضلاً عن إمكانياتها للتكامل الأصلي ضمن سياقات Web3 والعملات الرقمية.
من منظور نفسية المستخدم، أظهر استطلاع في عام 2023 أن 44% من المستجيبين اعتبروا النتائج العضوية العادية أكثر موثوقية من المقتطفات المميزة. كما وجدت الأبحاث الأكاديمية أنه في حالات الجدل أو نقص الحقيقة الواحدة الموثوقة، يفضل المستخدمون صفحات النتائج التي تحتوي على روابط من مصادر متعددة.
بعبارة أخرى، بينما لا يثق جزء من المستخدمين تمامًا في الملخصات التي تم إنشاؤها بواسطة الذكاء الاصطناعي، فقد تحول نسبة كبيرة من السلوك بالفعل إلى "نقرة صفرية". لذلك، لا تزال متصفحات الذكاء الاصطناعي بحاجة إلى استكشاف نموذج التفاعل الصحيح—خاصة في مجال قراءة البيانات. نظرًا لأن مشكلة الهلوسة في النماذج الكبيرة لم يتم حلها بالكامل بعد، لا يزال العديد من المستخدمين يكافحون للثقة تمامًا في الملخصات التي تم إنشاؤها تلقائيًا. في هذا الصدد، فإن تضمين النماذج الكبيرة في المتصفحات لا يتطلب بالضرورة تحويلًا جذريًا. بدلاً من ذلك، يتطلب تحسينات تدريجية في الدقة والقابلية للتحكم—وهي عملية جارية بالفعل.
استخدام المتصفح
هذه هي بالضبط المنطق الأساسي وراء التمويل الضخم الذي حصلت عليه Perplexity وBrowser Use. على وجه الخصوص، ظهرت Browser Use كفرصة الابتكار الثانية الأكثر وعداً في أوائل عام 2025، مع وجود يقين وإمكانية نمو قوية.

لقد أنشأ استخدام المتصفح طبقة دلالية حقيقية، مع التركيز الأساسي على إنشاء بنية التعرف الدلالي للجيل القادم من المتصفحات.
إعادة تفسير استخدام المتصفح التقليدي "DOM = شجرة العقد التي يراها البشر" إلى "DOM دلالي = شجرة تعليمات تقرأها LLMs". هذا يسمح للوكلاء بالنقر بدقة، وملء المعلومات، وتحميل دون الاعتماد على "إحداثيات البكسل". بدلاً من استخدام OCR البصري أو Selenium المعتمد على الإحداثيات، تأخذ هذه الطريقة مسار "نص منظم → استدعاءات دالة"، مما يجعل التنفيذ أسرع، ويوفر الرموز، ويقلل من الأخطاء. وصفت TechCrunch ذلك بأنه "طبقة الربط التي تسمح للذكاء الاصطناعي بفهم صفحات الويب حقًا". في مارس، أغلقت استخدام المتصفح جولة تمويل أولية بقيمة 17 مليون دولار، مراهنة على هذا الابتكار الأساسي.
إليك كيفية عمل ذلك:
بعد أن يتم عرض HTML، فإنه يشكل شجرة DOM قياسية. ثم يستخرج المتصفح شجرة الوصول، والتي توفر تسميات "أدوار" و"حالات" أغنى لقارئات الشاشة.
كل عنصر تفاعلي (زر، إدخال، إلخ) يتم تجريده إلى مقطع JSON مع بيانات وصفية مثل الدور، الرؤية، الإحداثيات، والإجراءات القابلة للتنفيذ.
تمت ترجمة الصفحة بأكملها إلى قائمة مسطحة من العقد الدلالية، والتي يمكن لـ LLM قراءتها في موجه نظام واحد.
تخرج LLM تعليمات عالية المستوى (على سبيل المثال، انقر (node_id="btn-Checkout"))، والتي يتم إعادة تشغيلها بعد ذلك في المتصفح الحقيقي.
تصف المدونة الرسمية هذه العملية بأنها "تحويل واجهات المواقع إلى نصوص منظمة يمكن لنماذج اللغة الكبيرة تحليلها."
علاوة على ذلك، إذا تم اعتماد هذا المعيار من قبل W3C، فقد يحل بشكل كبير مشكلة إدخال المتصفح. بعد ذلك، سننظر في الرسالة المفتوحة ودراسات الحالة من شركة المتصفح لشرح المزيد عن سبب كون نهجهم معيبًا.
قوس
ذكرت شركة Browser Company (الشركة الأم لـ Arc) في رسالتها المفتوحة أن متصفح Arc سيدخل في وضع الصيانة العادية، بينما سيتحول تركيز الفريق إلى تطوير DIA، وهو متصفح موجه بالكامل نحو الذكاء الاصطناعي. في الرسالة، اعترفوا أيضًا بأن مسار التنفيذ المحدد لـ DIA لم يتم تحديده بعد. في الوقت نفسه، وضع الفريق عدة توقعات حول مستقبل سوق المتصفحات.
استنادًا إلى هذه التوقعات، نعتقد أيضًا أنه إذا كان من المقرر أن يتعرض مشهد المتصفح الحالي للاضطراب حقًا، فإن المفتاح يكمن في تغيير جانب الإخراج للتفاعل.
فيما يلي ثلاث من التوقعات حول سوق المتصفحات المستقبلية التي شاركتها فريق Arc.
https://browsercompany.substack.com/p/letter-to-arc-members-2025
أولاً، يعتقد فريق Arc أن صفحات الويب لن تكون الواجهة الرئيسية للتفاعل بعد الآن. من المؤكد أن هذا ادعاء جريء وصعب، وهو أيضًا السبب الرئيسي الذي يجعلنا نشكك في تأملات مؤسسهم. في رأينا، يبالغ هذا المنظور في تقليل دور المتصفح، ويسلط الضوء على المشكلة الرئيسية التي أغفلها الفريق عند استكشاف مسار متصفح الذكاء الاصطناعي.
تؤدي النماذج الكبيرة بشكل ممتاز في التقاط النية - على سبيل المثال، فهم التعليمات مثل "ساعدني في حجز رحلة." ومع ذلك، فهي لا تزال غير كافية عندما يتعلق الأمر بكثافة المعلومات. عندما يحتاج المستخدم إلى شيء مثل لوحة التحكم، أو دفتر ملاحظات على طراز Bloomberg Terminal، أو قماش بصري مثل Figma، لا يمكن لأي شيء أن يتفوق على صفحة ويب مضبوطة بدقة بكسل. إن تصميم كل منتج - الرسوم البيانية، وظيفة السحب والإفلات، مفاتيح الاختصار - ليست زخرفة سطحية، ولكنها ميزات أساسية تضغط على الإدراك. لا يمكن تكرار هذه القدرات من خلال تفاعلات محادثة بسيطة. أخذ Gate.com كمثال: إذا أراد المستخدم تنفيذ إجراء استثماري، فإن الاعتماد فقط على محادثة الذكاء الاصطناعي بعيد عن كونه كافياً، حيث يعتمد المستخدمون بشكل كبير على المدخلات المنظمة، والدقة، وعرض المعلومات بشكل واضح.
تحتوي خريطة طريق فريق Arc على عيب أساسي: إنها تفشل في التمييز بوضوح أن "التفاعل" يتكون من بعدين - الإدخال والإخراج. على جانب الإدخال، إن وجهة نظرهم تحمل بعض الصحة في سيناريوهات معينة، حيث يمكن للذكاء الاصطناعي تحسين كفاءة التفاعلات بأسلوب الأوامر. ولكن على جانب الإخراج، فإن افتراضهم غير متوازن بوضوح، حيث يغفل الدور الأساسي للمتصفح في تقديم المعلومات وتجارب مخصصة. على سبيل المثال، لدى Reddit تخطيطه الفريد وهندسته المعلوماتية، بينما يمتلك AAVE واجهة وبنية مختلفة تمامًا. كمنصة تخزن في الوقت نفسه بيانات خاصة للغاية وتقدم واجهات منتجات متنوعة، فإن المتصفح لديه قابلية استبدال محدودة على جانب الإدخال، بينما تجعل تعقيداته وطبيعته غير القياسية على جانب الإخراج من الصعب للغاية تعطيله.
بالمقابل، تركز متصفحات الذكاء الاصطناعي الحالية في الغالب على طبقة "تلخيص المخرجات": تلخيص الصفحات، استخراج المعلومات، توليد الاستنتاجات. هذا ليس كافياً لطرح تحدٍ جذري للمتصفحات الرئيسية أو أنظمة البحث مثل Google - إنه مجرد تقليص لحصة السوق لتلخيصات البحث.
لذلك، فإن التكنولوجيا الوحيدة التي يمكن أن تهز حقًا حصة سوق كروم البالغة 66% مقدر لها ألا تكون "كروم التالي". لتحقيق disruption حقيقي، يجب إعادة هيكلة نموذج عرض المتصفحات بشكل جذري ليتكيف مع احتياجات التفاعل في عصر وكيل الذكاء الاصطناعي، خاصة من حيث تصميم بنية الجانبين المدخل. وهذا هو السبب في أننا نجد المسار الفني الذي اتخذته Browser Use أكثر إقناعًا - حيث يركز على التغييرات الهيكلية في الآلية الأساسية للمتصفحات. بمجرد أن تحقق أي نظام تصميم "ذري" أو "وحدوي"، فإن القابلية للبرمجة والتركيب المستمدة من ذلك تفتح إمكانيات disruption. هذا بالضبط هو الاتجاه الذي تتابعه Browser Use اليوم.
باختصار، لا يزال تشغيل وكلاء الذكاء الاصطناعي يعتمد بشكل كبير على وجود المتصفحات. المتصفحات ليست فقط المستودعات الرئيسية للبيانات المعقدة المخصصة، ولكنها أيضًا واجهات العرض العالمية للتطبيقات المتنوعة، وبالتالي ستظل تعمل كالبوابة الأساسية للتفاعل في المستقبل. مع تعمق وكلاء الذكاء الاصطناعي في المتصفحات لإكمال المهام الثابتة، سيتفاعلون مع بيانات المستخدم والتطبيقات المحددة بشكل رئيسي من خلال جانب الإدخال. لهذا السبب، يجب ابتكار نموذج العرض الحالي للمتصفحات لتحقيق أقصى قدر من التوافق والتكيف مع وكلاء الذكاء الاصطناعي—مما يسمح لهم في النهاية بالتقاط التطبيقات بشكل أكثر فعالية.
الحيرة
بيربلكستي هو محرك بحث يعمل بالذكاء الاصطناعي مشهور بنظام التوصيات الخاص به. وقد ارتفعت قيمته الأخيرة إلى 14 مليار دولار، بزيادة تقارب خمسة أضعاف من 3 مليارات دولار في يونيو 2024. وهو الآن يتعامل مع أكثر من 400 مليون استعلام بحث شهريًا. في سبتمبر 2024 وحده، تمت معالجة حوالي 250 مليون استعلام، مما يمثل زيادة سنوية تصل إلى ثمانية أضعاف في حجم بحث المستخدمين، مع أكثر من 30 مليون مستخدم نشط شهريًا.
الميزة الرئيسية هي القدرة على تلخيص الصفحات في الوقت الفعلي، مما يمنحها ميزة قوية في الوصول إلى المعلومات المحدثة. في وقت سابق من هذا العام، بدأت Perplexity في بناء متصفحها الأصلي، Comet. تصف الشركة Comet على أنه متصفح لا "يعرض" فقط صفحات الويب ولكن أيضًا "يفكر" فيها. رسميًا، يدعون أنه سيقوم بتضمين محرك إجابات Perplexity في عمق المتصفح نفسه، متبعين نهج "الآلة الكاملة" الذي يذكرنا بفلسفة ستيف جوبز: دمج مهام الذكاء الاصطناعي بعمق على مستوى المتصفح الأساسي، بدلاً من مجرد بناء إضافات جانبية.
تهدف Comet إلى استبدال "الروابط الزرقاء العشر" التقليدية والمنافسة مباشرة مع Chrome، مع إجابات مختصرة مدعومة بالاستشهادات.
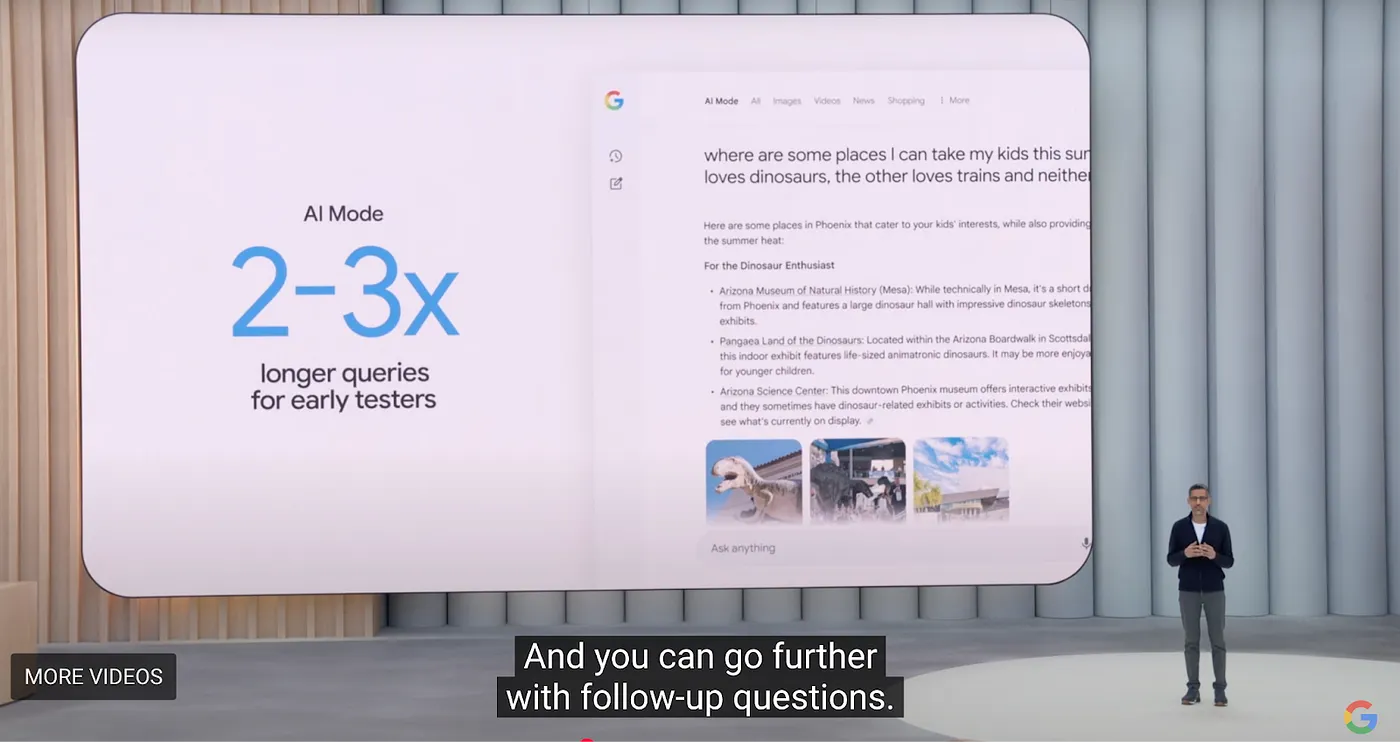
لكن Perplexity لا تزال بحاجة إلى حل مشكلتين أساسيتين: تكاليف البحث العالية وهامش الربح المنخفض من المستخدمين الهامشيين. على الرغم من أن Perplexity تتصدر حاليًا في مجال البحث بالذكاء الاصطناعي، أعلنت Google في مؤتمر I/O 2025 الخاص بها عن إصلاح ذكي واسع النطاق لمنتجاتها الأساسية. بالنسبة للمتصفحات، أطلقت Google تجربة جديدة لعلامة التبويب في المتصفح تسمى AI Model، والتي تدمج Overview، Deep Research، وميزات Agentic المستقبلية. يُشار إلى المبادرة بأكملها باسم "Project Mariner."
تقوم Google بنشاط بتعزيز تحولها في الذكاء الاصطناعي، مما يعني أن تقليد الميزات السطحية - مثل نظرة عامة، البحث العميق، أو الوكالات - لن يشكل تهديدًا حقيقيًا. ما يمكن أن يؤسس حقًا نظامًا جديدًا وسط الفوضى هو إعادة بناء بنية المتصفح من الألف إلى الياء، مع تضمين نماذج اللغة الكبيرة (LLMs) بعمق في نواة المتصفح، وتحويل طرق التفاعل بشكل أساسي.
بريف
برايف هو واحد من أقدم وأنجح المتصفحات في صناعة العملات المشفرة. تم بناؤه على بنية كروميوم، وهو متوافق مع الإضافات من متجر جوجل. يجذب برايف المستخدمين بنموذج يعتمد على الخصوصية وكسب الرموز من خلال التصفح. يظهر مسار تطويره إمكانيات نمو معينة. ومع ذلك، من منظور المنتج، في حين أن الخصوصية مهمة بالفعل، لا يزال الطلب مركزًا ضمن مجموعات مستخدمين معينة. بالنسبة للجمهور الأوسع، فإن الوعي بالخصوصية لم يصبح بعد عامل قرار رئيسي. لذلك، من غير المحتمل أن تنجح محاولة الاعتماد على هذه الميزة وحدها لإحداث تغيير في عمالقة السوق الحاليين.
حتى الآن، وصلت Brave إلى 82.7 مليون مستخدم نشط شهريًا (MAU) و35.6 مليون مستخدم نشط يوميًا (DAU)، مما يمنحها حصة سوقية تبلغ حوالي 1%–1.5%. لقد أظهر قاعدة مستخدميها نموًا مستقرًا: من 6 ملايين في يوليو 2019، إلى 25 مليونًا في يناير 2021، إلى 57 مليونًا في يناير 2023، وبحلول فبراير 2025، تجاوزت 82 مليونًا. تظل معدلات نموها السنوية المركبة في خانة العشرات.
تتعامل Brave مع حوالي 1.34 مليار استعلام بحث شهريًا، وهو ما يمثل حوالي 0.3% من حجم Google.
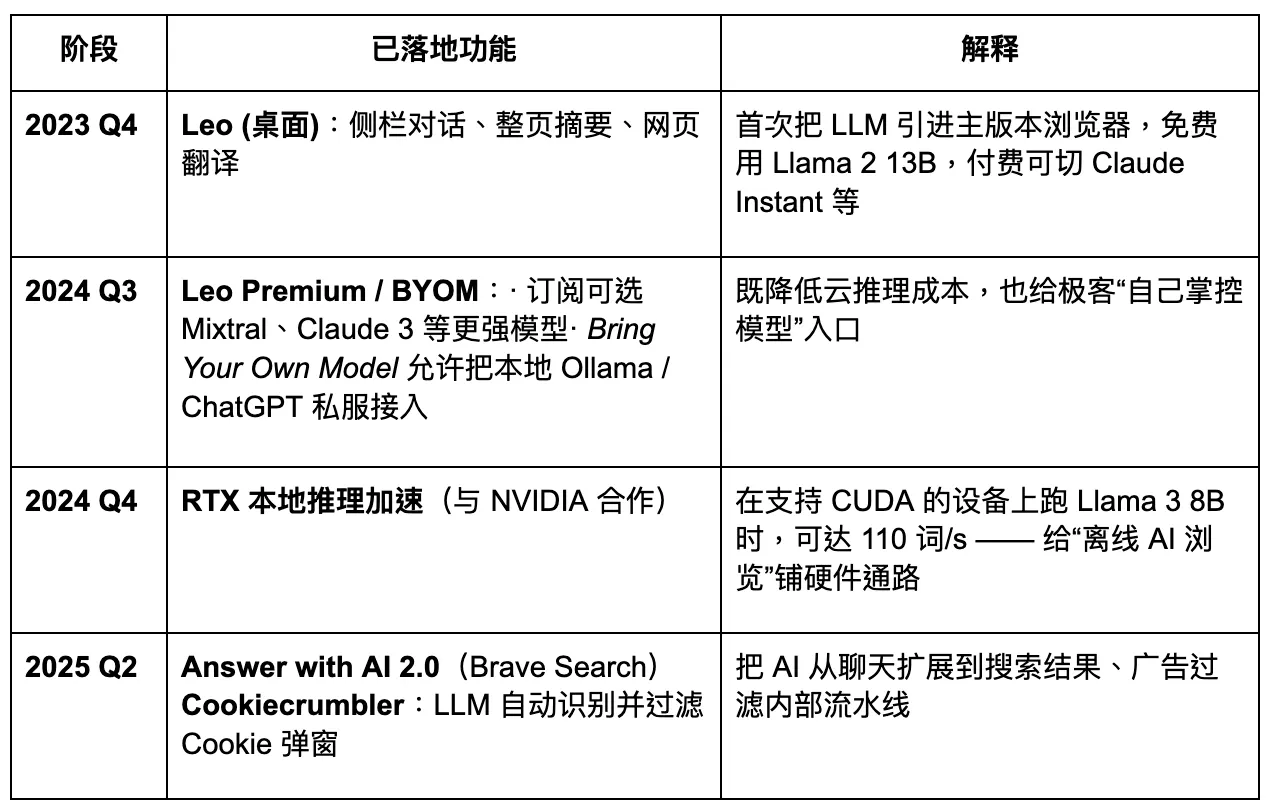
تخطط Brave للترقية إلى متصفح AI يركز على الخصوصية. ومع ذلك، فإن وصولها المحدود إلى بيانات المستخدم يقلل من مستوى التخصيص الممكن للنماذج الكبيرة، مما يعيق بدوره التكرار السريع والدقيق للمنتجات. في عصر متصفح Agentic القادم، قد تحافظ Brave على حصة مستقرة بين مجموعات المستخدمين المستهدفة التي تركز على الخصوصية، ولكن سيكون من الصعب عليها أن تصبح لاعبًا مهيمنًا. يعمل مساعدها الذكي، ليو، بشكل أكثر كإضافة لتعزيز الأداء - حيث يقدم بعض قدرات تلخيص المحتوى، ولكنه يفتقر إلى استراتيجية واضحة للانتقال الكامل نحو وكلاء الذكاء الاصطناعي. تظل الابتكارات في التفاعل غير كافية.
دونات
مؤخراً، حقق قطاع العملات المشفرة تقدماً أيضاً في مجال المستعرضات الوكيلة. جمعت المشروع في مرحلته المبكرة Donut مبلغ 7 ملايين دولار في جولة تمويل أولية، بقيادة Hongshan (Sequoia China) وHackVC وBitkraft Ventures. لا يزال المشروع في مرحلته المفاهيمية المبكرة، برؤية لتحقيق "الاكتشاف - اتخاذ القرار - والتنفيذ الأصلي للعملات المشفرة" كقدرة متكاملة.
الاتجاه الرئيسي هو دمج مسارات التنفيذ الآلي الأصلية للعملات المشفرة. كما توقع a16z، قد تحل الوكلاء محل محركات البحث كبوابة المرور الرئيسية في المستقبل. لن يتنافس رواد الأعمال بعد الآن حول خوارزميات ترتيب Google، بل سيقاتلون من أجل حركة المرور والتحويلات التي تأتي من تنفيذ الوكلاء. صنعت الصناعة بالفعل اسمًا لهذه الظاهرة "AEO" (تحسين محرك الإجابة / الوكيل)، أو حتى "ATF" (إنجاز المهام الوكيلة) - حيث لم يعد الهدف هو تحسين تصنيفات البحث، بل الخدمة مباشرةً للنماذج الذكية التي يمكن أن تكمل المهام للمستخدمين، مثل تقديم الطلبات، حجز التذاكر، أو كتابة الرسائل.
للرواد الأعمال
أولاً، يجب الاعتراف: المتصفح نفسه يظل أكبر "بوابة" غير مٌعاد تشكيلها في عالم الإنترنت. مع حوالي 2.1 مليار مستخدم لأجهزة الكمبيوتر المكتبية وأكثر من 4.3 مليار مستخدم للهواتف المحمولة على مستوى العالم، فإنه يعمل كوسيلة نقل شائعة لإدخال البيانات، والسلوك التفاعلي، وتخزين بصمات الأصابع المخصصة. سبب استمراره ليس الخمول، بل الطبيعة المزدوجة المتأصلة في المتصفح: فهو نقطة الدخول لقراءة البيانات ونقطة الخروج لإجراءات الكتابة.
لذلك، بالنسبة لرجال الأعمال، يكمن الإمكانات الحقيقية لتعطيل السوق ليس في تحسين "طبقة مخرجات الصفحة". حتى لو استطاع المرء تكرار وظائف نظرة عامة مشابهة لـ Google في علامة تبويب جديدة، فسيظل ذلك مجرد تكرار في طبقة المكونات الإضافية، وليس تحولاً جوهريًا في النموذج. يكمن الاختراق الحقيقي في "جانب الإدخال" - كيفية جعل الوكلاء الذكاء الاصطناعي يستدعون منتجك بنشاط لإكمال مهام معينة. سيحدد هذا ما إذا كان يمكن للمنتج الاندماج في نظام الوكلاء، والتقاط الحركة، والمشاركة في توزيع القيمة.
في عصر البحث، كانت المنافسة تدور حول النقرات؛ في عصر الوكلاء، تتعلق بالمكالمات.
إذا كنت رائد أعمال، يجب أن تعيد تصور منتجك كعنصر واجهة برمجة التطبيقات - شيء يمكن لوكيل ذكي فهمه واستدعائه. يتطلب هذا منك أن تأخذ في اعتبارك ثلاثة أبعاد منذ بداية تصميم المنتج:
1. معيارية هيكل الواجهة: هل منتجك قابل للاستدعاء؟
تعتمد قدرة الوكيل على استدعاء منتج ما على ما إذا كان هيكله المعلوماتي يمكن توحيده وتجريده إلى مخطط واضح. على سبيل المثال، هل يمكن وصف الإجراءات الأساسية مثل تسجيل المستخدم، أو تقديم الطلبات، أو إرسال التعليقات من خلال هيكل DOM دلالي أو خريطة JSON؟ هل يوفر النظام آلة حالة حتى يتمكن الوكيل من تكرار سير العمل للمستخدم بشكل موثوق؟ هل يمكن برمجة تفاعلات المستخدمين على الصفحة؟ هل يقدم المنتج Webhooks مستقرة أو نقاط نهاية API؟
هذا هو السبب بالضبط في أن استخدام المتصفح نجح في جمع الأموال - فقد حول المتصفح من عارض HTML بسيط إلى شجرة دلالية قابلة للاستدعاء بواسطة LLMs. بالنسبة لرواد الأعمال، فإن اعتماد فلسفة تصميم مماثلة في منتجات الويب يعني الاستعداد للتكيف المنظم في عصر وكلاء الذكاء الاصطناعي.
2. الهوية والوصول: هل يمكنك مساعدة الوكلاء في "تجاوز حاجز الثقة"؟
لإتمام المعاملات أو استدعاء وظائف الدفع والأصول، يحتاج الوكلاء إلى وسيط موثوق - هل يمكنك أن تصبح ذلك الوسيط؟ تتمتع المتصفحات بشكل طبيعي بالقدرة على قراءة التخزين المحلي، والوصول إلى المحافظ، والتعامل مع CAPTCHAs، ودمج المصادقة الثنائية. وهذا يجعلها أكثر ملاءمة من النماذج المستضافة في السحابة لتنفيذ المهام. هذا صحيح بشكل خاص في Web3، حيث لا يتم توحيد واجهات تفاعل الأصول. بدون "هوية" أو "قدرة على التوقيع"، لا يمكن لوكيل المضي قدماً.
بالنسبة لرواد الأعمال في مجال التشفير، يفتح هذا مساحة بيضاء خيالية للغاية: "منصة القدرات المتعددة (MCP) لعالم البلوكشين." يمكن أن تتخذ هذه شكل طبقة أوامر عالمية (تتيح للوكيل استدعاء التطبيقات اللامركزية)، مجموعة واجهات عقود موحدة، أو حتى محفظة محلية خفيفة + مركز هوية.
3. إعادة التفكير في آليات المرور: المستقبل ليس تحسين محركات البحث، بل تحسين تجربة المستخدم / تحسين التفاعل.
في الماضي، كان عليك الفوز بخوارزمية جوجل؛ الآن تحتاج إلى أن تكون مدمجًا في سلاسل المهام لوكلاء الذكاء الاصطناعي. هذا يعني أن منتجك يجب أن يحتوي على دقة مهام واضحة: ليس "صفحة"، بل سلسلة من وحدات القدرة القابلة للاستدعاء. كما يعني البدء في تحسين محركات الوكلاء (AEO) أو التكيف مع تلبية المهام الوكيلة (ATF). على سبيل المثال، هل يمكن تبسيط عملية التسجيل إلى خطوات منظمة؟ هل يمكن سحب التسعير من خلال واجهة برمجة التطبيقات؟ هل يمكن الوصول إلى المخزون في الوقت الحقيقي؟
قد تحتاج حتى إلى التكيف مع صيغ الاتصال المختلفة عبر أطر LLM—لأن OpenAI وClaude، على سبيل المثال، لديهما تفضيلات مختلفة لاستدعاءات الوظائف واستخدام الأدوات. Chrome هو محطة العالم القديم، وليس البوابة إلى العالم الجديد. مشاريع المستقبل لن تعيد بناء المتصفحات، بل ستجعل المتصفحات تخدم الوكلاء—تبني جسوراً للجيل الجديد من "تدفقات التعليمات."
ما تحتاج لبنائه هو "لغة الواجهة" التي من خلالها يتصل الوكلاء بعالمك.
ما تحتاجه لكسبه هو مكان في سلسلة الثقة للأنظمة الذكية.
ما تحتاجه لبنائه هو "قلعة API" في نموذج البحث التالي.
إذا كانت Web2 قد اجتذبت انتباه المستخدمين من خلال واجهة المستخدم، فإن عصر Web3 + وكيل الذكاء الاصطناعي سيجذب نية تنفيذ الوكيل من خلال سلاسل المكالمات.
إخلاء المسؤولية
لا تشكل هذه المحتوى عرضًا أو دعوة أو توصية. يجب عليك دائمًا طلب نصيحة مهنية مستقلة قبل اتخاذ أي قرار استثماري. يرجى ملاحظة أن Gate و/أو Gate Ventures قد تقيد أو تمنع بعض أو كل الخدمات في المناطق المحظورة. يرجى قراءة اتفاقية المستخدم المعمول بها لمزيد من التفاصيل.
حول Gate Ventures
تعد Gate Ventures الذراع الاستثماري لرأس المال المغامر لشركة Gate، حيث تركز على الاستثمارات في البنية التحتية اللامركزية، والأنظمة البيئية، والتطبيقات - التقنيات التي ستعيد تشكيل العالم في عصر الويب 3.0. تعمل Gate Ventures مع قادة الصناعة العالميين لتمكين الفرق والشركات الناشئة من خلال التفكير الابتكاري والقدرات لإعادة تعريف الطريقة التي تتفاعل بها المجتمعات والتمويل.
الموقع الإلكتروني: https://www.gate.com/ventures
مشاركة
المحتوى

