Gate Ventures Research Insights: La Tercera Guerra de Navegadores: La Batalla de Entrada en la Era de los Agentes de IA
TL;DR
La tercera guerra de los navegadores se está desarrollando en silencio. Mirando hacia atrás en la historia, desde Netscape y el Internet Explorer de Microsoft en los años 90 hasta el Firefox de código abierto y el Chrome de Google, la guerra de los navegadores siempre ha sido una manifestación concentrada del control de plataformas y los cambios de paradigma tecnológico. Chrome ha asegurado su posición dominante gracias a su rápida velocidad de actualización y su ecosistema integrado, mientras que Google, a través de su duopolio de búsqueda y navegador, ha formado un circuito cerrado de acceso a la información.
Pero hoy, este paisaje está temblando. El auge de los grandes modelos de lenguaje (LLMs) está permitiendo que cada vez más usuarios completen tareas sin hacer clic en la página de resultados de búsqueda, mientras que los clics en páginas web tradicionales están disminuyendo. Mientras tanto, los rumores de que Apple tiene la intención de reemplazar el motor de búsqueda predeterminado en Safari amenazan aún más la base de beneficios de Alphabet (la empresa matriz de Google), y el mercado comienza a expresar inquietud sobre la "ortodoxia de la búsqueda."
El navegador mismo también está enfrentando una remodelación de su papel. No es solo una herramienta para mostrar páginas web, sino también un contenedor para múltiples capacidades, incluyendo la entrada de datos, el comportamiento del usuario y la identidad privada. Aunque los agentes de IA son poderosos, todavía dependen del límite de confianza del navegador y del sandbox funcional para completar interacciones complejas en las páginas, acceder a datos de identidad local y controlar elementos de las páginas web. Los navegadores están evolucionando de interfaces humanas a plataformas de llamadas del sistema para agentes.
En este artículo, exploramos si los navegadores siguen siendo necesarios. Creemos que lo que podría realmente interrumpir el actual panorama del mercado de navegadores no es otro "mejor Chrome", sino una nueva estructura de interacción: no solo la visualización de información, sino la invocación de tareas. Los futuros navegadores deben ser diseñados para agentes de IA, capaces no solo de leer, sino también de escribir y ejecutar. Proyectos como Browser Use están intentando semantizar la estructura de las páginas, transformando las interfaces visuales en texto estructurado que puede ser invocado por LLM, mapeando páginas a comandos y reduciendo significativamente los costos de interacción.
Los grandes proyectos ya están probando las aguas: Perplexity está construyendo un navegador nativo, Comet, que reemplaza los resultados de búsqueda tradicionales con IA; Brave está combinando la protección de la privacidad con el razonamiento local, utilizando LLM para mejorar las capacidades de búsqueda y bloqueo; y proyectos nativos de criptomonedas como Donut están buscando nuevos puntos de entrada para que la IA interactúe con activos en cadena. Un rasgo común entre estos proyectos es su intento de remodelar la capa de entrada del navegador, en lugar de embellecer su capa de salida.
Para los emprendedores, las oportunidades se encuentran dentro del triángulo de entrada, estructura y acceso a agentes. Como la interfaz para el futuro mundo basado en agentes, el navegador significa que quien pueda proporcionar "capacidades" estructuradas, invocables y confiables se convertirá en un componente de la plataforma de próxima generación. Desde SEO hasta AEO (Optimización del Motor de Agentes), del tráfico de páginas a la invocación de cadenas de tareas, la forma del producto y el pensamiento de diseño están siendo remodelados. La tercera guerra de navegadores se está llevando a cabo por la "entrada" en lugar de por la "visualización". La victoria ya no se determina por quién captura la atención del usuario, sino por quién gana la confianza del agente y obtiene acceso.
Una Breve Historia del Desarrollo de Navegadores
A principios de la década de 1990, antes de que Internet se convirtiera en parte de la vida cotidiana, Netscape Navigator irrumpió en la escena, como un velero que abrió la puerta al mundo digital para millones de usuarios. Aunque no fue el primer navegador, fue el primero en llegar verdaderamente a las masas y dar forma a la experiencia de Internet. Por primera vez, las personas podían navegar por la web con tal facilidad a través de una interfaz gráfica, como si de repente todo el mundo se hubiera vuelto accesible.
Sin embargo, la gloria a menudo es efímera. Microsoft reconoció rápidamente la importancia de los navegadores y decidió agrupar Internet Explorer de manera forzada en el sistema operativo Windows, convirtiéndolo en el navegador predeterminado. Esta estrategia, un verdadero “asesino de plataformas”, socavó directamente el dominio de mercado de Netscape. Muchos usuarios no eligieron activamente IE; más bien, simplemente lo aceptaron como el predeterminado. Aprovechando las capacidades de distribución de Windows, IE rápidamente se convirtió en el líder de la industria, mientras que Netscape cayó en declive.

En medio de la adversidad, los ingenieros de Netscape eligieron un camino radical e idealista: abrieron el código fuente del navegador y llamaron a la comunidad de código abierto. Esta decisión fue como una "abdicación macedónica" en el mundo tecnológico, señalando el final de una vieja era y el surgimiento de nuevas fuerzas. Ese código se convirtió más tarde en la base del proyecto del navegador Mozilla, que primero se llamó Phoenix (simbolizando renacimiento), pero después de varias disputas de marcas comerciales, finalmente fue renombrado como Firefox.
Firefox no fue una mera copia de Netscape. Hizo avances en experiencia de usuario, ecosistemas de complementos y seguridad. Su nacimiento marcó la victoria del espíritu de código abierto e inyectó nueva vitalidad en toda la industria. Algunos describieron a Firefox como el "sucesor espiritual" de Netscape, similar a cómo el Imperio Otomano heredó la gloria que se desvanecía de Bizancio. Aunque exagerada, la comparación es significativa.
Sin embargo, antes de que Firefox se lanzara oficialmente, Microsoft ya había lanzado seis versiones de Internet Explorer. Al aprovechar su tiempo de lanzamiento anticipado y su estrategia de empaquetado de sistema, Firefox se colocó en una posición de alcanzar desde el principio, asegurando que esta carrera nunca fue una competencia equitativa comenzando desde la misma línea.
Al mismo tiempo, otro jugador temprano entró en escena de manera silenciosa. En 1994, nació el navegador Opera en Noruega, inicialmente solo un proyecto experimental. Pero a partir de la versión 7.0 en 2003, introdujo su motor Presto desarrollado por sí mismo, siendo pionero en el soporte de CSS, diseños adaptativos, control por voz y codificación Unicode. Aunque su base de usuarios era limitada, lideró constantemente la industria tecnológicamente, convirtiéndose en el "favorito de los geeks."
Ese mismo año, Apple lanzó el navegador Safari — un punto de inflexión significativo. En ese momento, Microsoft había invertido $150 millones en una Apple en apuros para mantener una apariencia de competencia y evitar el escrutinio antimonopolio. Aunque el motor de búsqueda predeterminado de Safari era Google desde el principio, este enredo con Microsoft simbolizaba las relaciones complejas y sutiles entre los gigantes de internet: cooperación y competencia, siempre entrelazadas.
En 2007, IE7 fue lanzado junto con Windows Vista, pero la respuesta del mercado fue tibia. Firefox, por otro lado, aumentó constantemente su cuota de mercado a aproximadamente el 20%, gracias a ciclos de actualización más rápidos, un mecanismo de extensiones más amigable para el usuario y un atractivo natural para los desarrolladores. El dominio de IE comenzó a aflojarse, y los vientos estaban cambiando.
Google, sin embargo, adoptó un enfoque diferente. Aunque había estado planeando su propio navegador desde 2001, le tomó seis años convencer al CEO Eric Schmidt para aprobar el proyecto. Chrome debutó en 2008, construido sobre el proyecto de código abierto Chromium y el motor WebKit utilizado por Safari. Se burlaron de él como un navegador "sobrecargado", pero con la profunda experiencia de Google en publicidad y construcción de marcas, ascendió rápidamente.
La principal arma de Chrome no eran sus características, sino su ciclo de actualizaciones frecuente (cada seis semanas) y su experiencia unificada en múltiples plataformas. En noviembre de 2011, Chrome superó a Firefox por primera vez, alcanzando un 27% de cuota de mercado; seis meses después, superó a IE, completando su transformación de retador a líder dominante.
Mientras tanto, el internet móvil de China estaba formando su propio ecosistema. El navegador UC de Alibaba se disparó en popularidad a principios de la década de 2010, especialmente en mercados emergentes como India, Indonesia y China. Con su diseño ligero y características de compresión de datos que ahorraban ancho de banda, conquistó a los usuarios en dispositivos de gama baja. Para 2015, su participación en el mercado global de navegadores móviles superó el 17%, y en India llegó a alcanzar hasta el 46%. Pero esta victoria no duró mucho. A medida que el gobierno indio reforzó las revisiones de seguridad de las aplicaciones chinas, el navegador UC se vio obligado a salir de mercados clave, perdiendo gradualmente su antigua gloria.
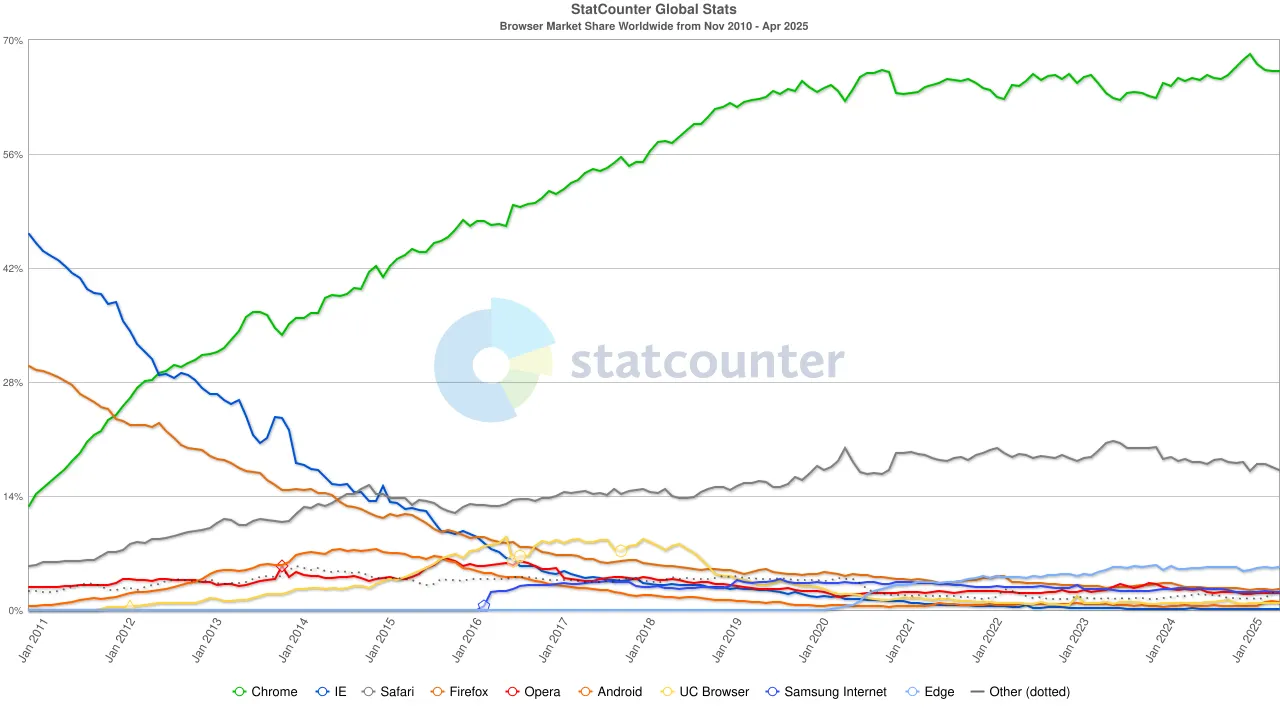
Para la década de 2020, el dominio de Chrome estaba firmemente establecido, con su cuota de mercado global estabilizándose alrededor del 65%. Notablemente, aunque el motor de búsqueda de Google y el navegador Chrome pertenecen a Alphabet, desde una perspectiva de mercado representan dos hegemonías independientes: la primera controla alrededor del 90% del tráfico de búsqueda global, y la segunda sirve como la "primera ventana" a través de la cual la mayoría de los usuarios acceden a Internet.
Para mantener esta estructura de doble monopolio, Google no ha escatimado en gastos. En 2022, Alphabet pagó a Apple aproximadamente 20 mil millones de dólares solo para que Google fuera el motor de búsqueda predeterminado en Safari. Los analistas han señalado que este gasto representó aproximadamente el 36% de los ingresos por publicidad de búsqueda que Google ganó del tráfico de Safari. En otras palabras, Google estaba efectivamente pagando una "cuota de protección" para defender su foso.
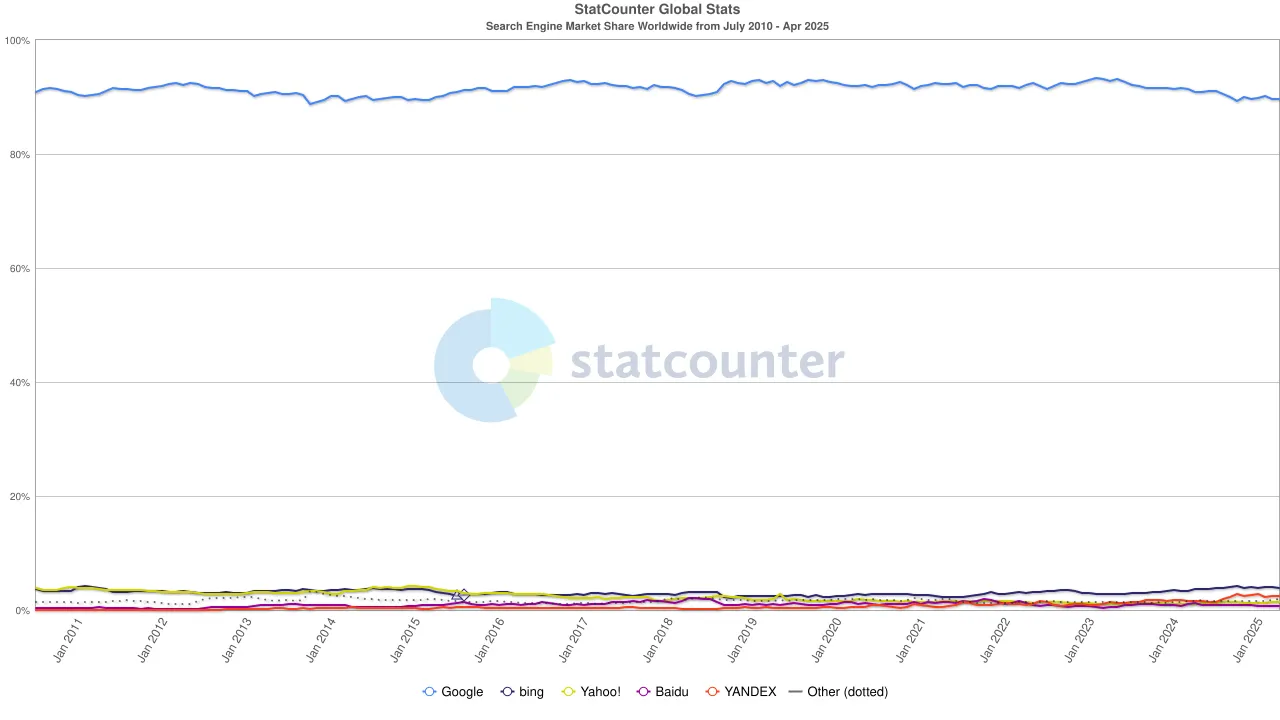
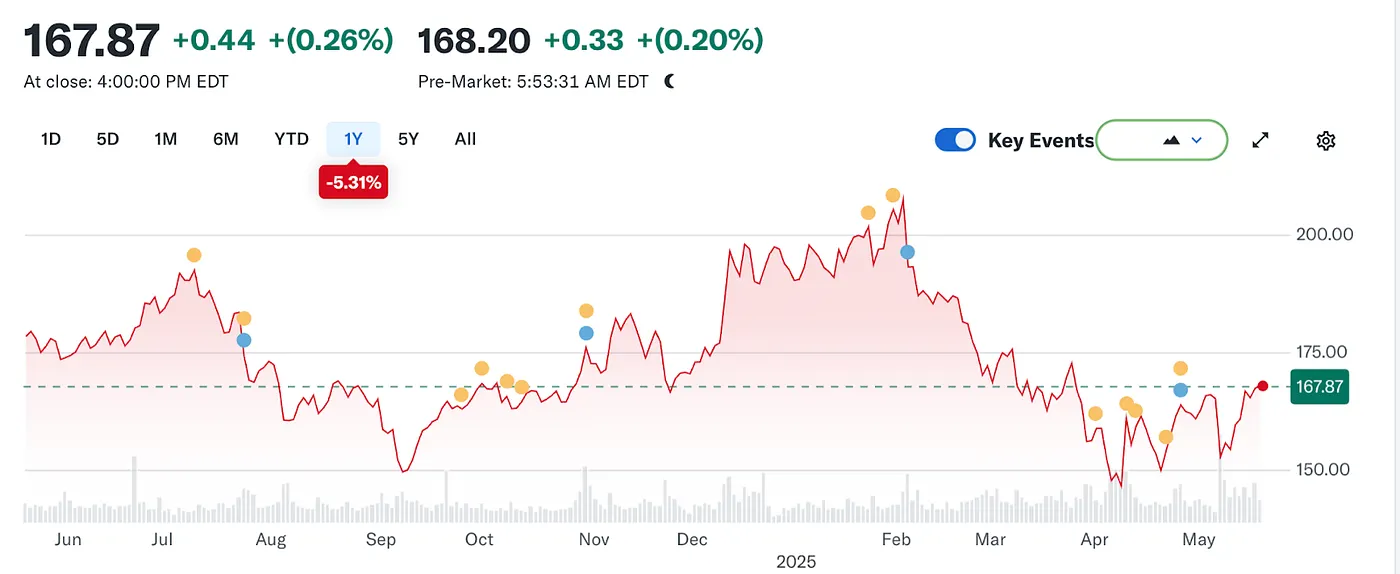
Pero la marea cambió una vez más. Con el auge de los grandes modelos de lenguaje (LLMs), la búsqueda tradicional comenzó a sentir el impacto. En 2024, la participación de Google en el mercado de búsqueda cayó del 93% al 89%. Aunque todavía dominaba, empezaron a aparecer grietas. Aún más disruptivas fueron los rumores de que Apple podría lanzar su propio motor de búsqueda impulsado por inteligencia artificial. Si la búsqueda predeterminada de Safari cambiara al propio ecosistema de Apple, no solo reconfiguraría el paisaje competitivo, sino que también podría sacudir los cimientos de las ganancias de Alphabet. El mercado reaccionó rápidamente: el precio de las acciones de Alphabet cayó de $170 a $140, reflejando no solo el pánico de los inversores, sino también una profunda inquietud sobre la dirección futura de la era de búsqueda.
Desde Navigator hasta Chrome, desde ideales de código abierto hasta la comercialización impulsada por la publicidad, desde navegadores ligeros hasta asistentes de búsqueda basados en IA, la batalla de los navegadores siempre ha sido una guerra sobre tecnología, plataformas, contenido y control. El campo de batalla sigue cambiando, pero la esencia nunca ha cambiado: quien controla el Gate define el futuro.
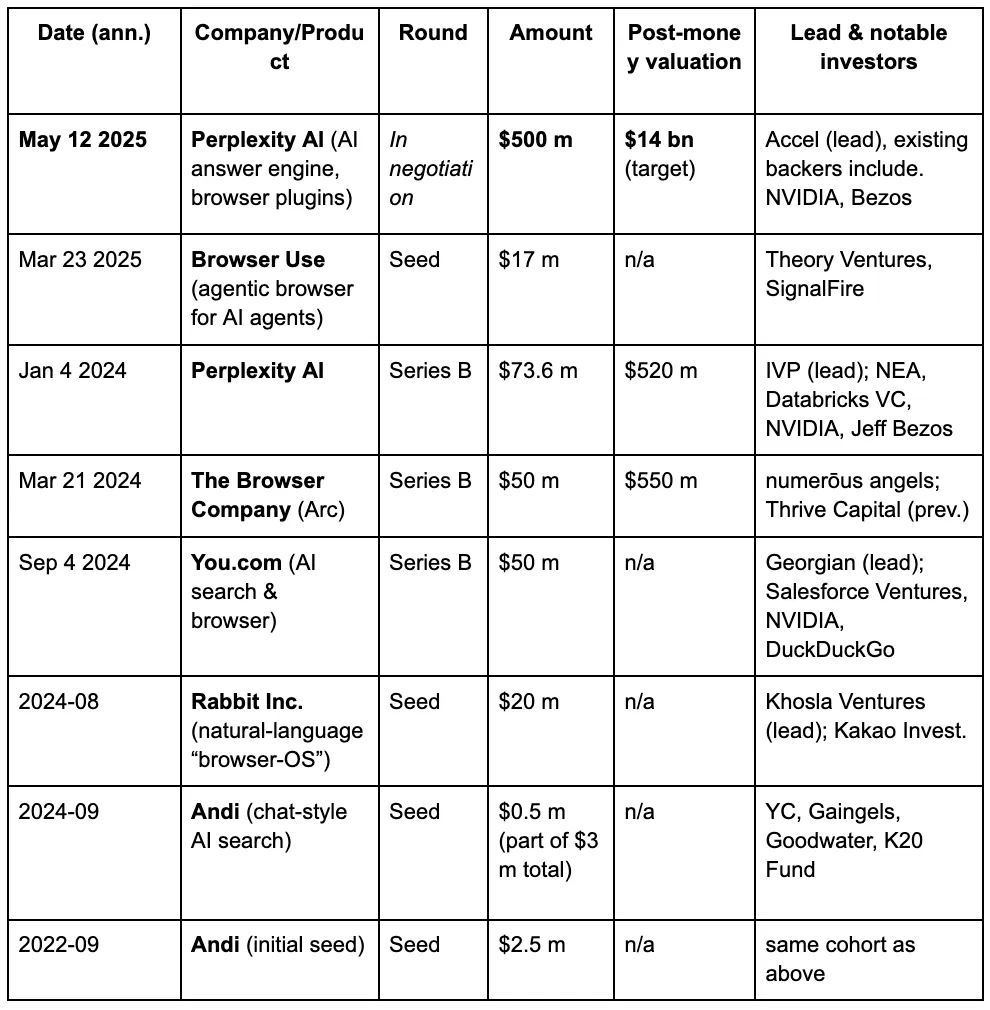
A ojos de los capitalistas de riesgo, una tercera guerra de navegadores se está desarrollando gradualmente, impulsada por las nuevas demandas que las personas imponen a los motores de búsqueda en la era de los LLM y la IA. A continuación se presentan los detalles de financiación de algunos proyectos conocidos en la pista de navegadores de IA.
La arquitectura obsoleta de los navegadores modernos
Cuando se trata de la arquitectura del navegador, la estructura tradicional clásica se muestra en el diagrama a continuación:
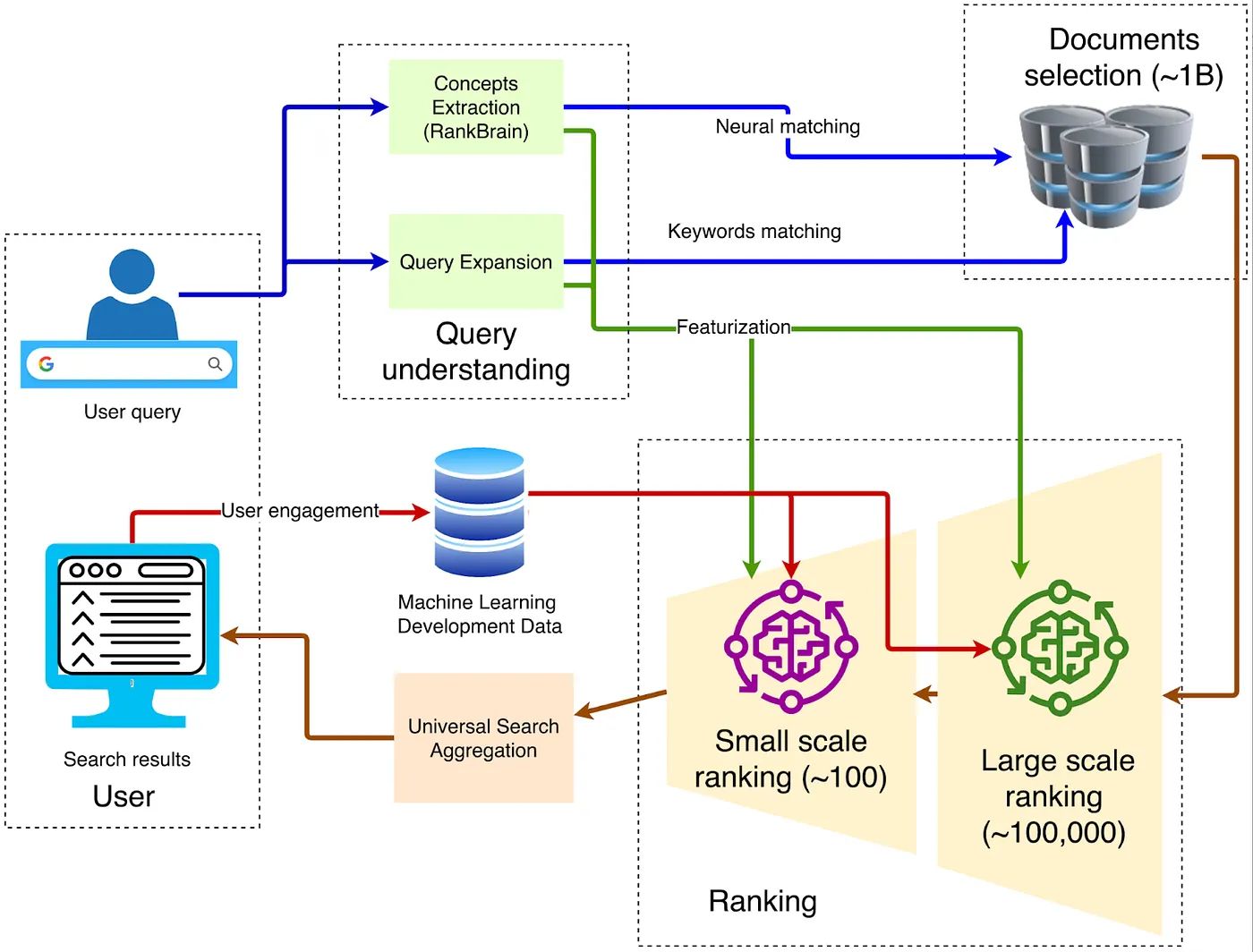
1. Cliente — Entrada del Front-End
La consulta se envía a través de HTTPS al Front End de Google más cercano, donde se realizan la descifrado TLS, el muestreo de QoS y el enrutamiento geográfico. Si se detecta tráfico anormal (como ataques DDoS o scraping automatizado), se pueden aplicar limitaciones de tasa o desafíos en esta capa.
2. Comprensión de Consultas
El front end necesita entender el significado de las palabras escritas por el usuario. Esto implica tres pasos:
Corrección ortográfica neural, como transformar “recpie” en “recipe”.
Expansión de sinónimos, por ejemplo, expandir "cómo arreglar una bicicleta" para incluir "reparar bicicleta".
El análisis de intenciones, que determina si la consulta es informativa, de navegación o transaccional, y luego asigna la solicitud vertical apropiada.
3. Recuperación de Candidatos
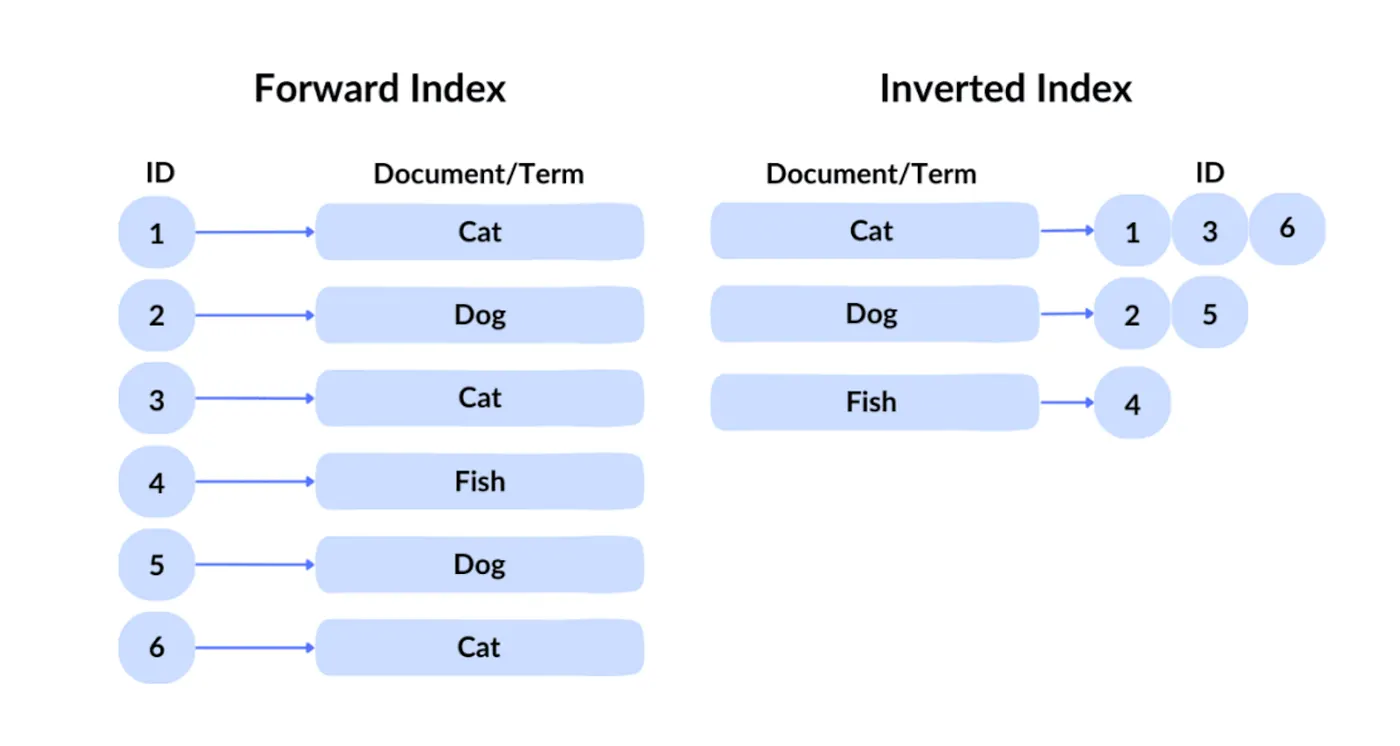
La tecnología de consulta de Google se conoce como un índice invertido. En un índice directo, recuperas un archivo dado su ID. Pero dado que los usuarios no pueden conocer los identificadores del contenido deseado entre cientos de miles de millones de archivos, Google utiliza el índice invertido tradicional, que consulta por contenido para identificar qué archivos contienen las palabras clave correspondientes.
A continuación, Google aplica indexación vectorial para manejar la búsqueda semántica, es decir, encontrar contenido similar en significado a la consulta. Convierte texto, imágenes y otro contenido en vectores de alta dimensión (embeddings), y luego busca en función de la similitud entre esos vectores. Por ejemplo, si un usuario busca "cómo hacer masa de pizza", el motor de búsqueda puede devolver resultados relacionados con "guía de preparación de masa de pizza", porque ambos son semánticamente similares.
A través de la indexación invertida y la indexación vectorial, se filtran aproximadamente cientos de miles de páginas web en la etapa de selección inicial.
4. Clasificación de Múltiples Etapas
El sistema utiliza típicamente miles de características ligeras como BM25, TF-IDF y puntajes de calidad de página para filtrar las cientos de miles de páginas candidatas hasta aproximadamente 1,000, formando un conjunto inicial de candidatos. Estos sistemas se denominan colectivamente motores de recomendación. Dependen de características masivas generadas a partir de diversas entidades, incluyendo el comportamiento del usuario, los atributos de la página, la intención de búsqueda y las señales contextuales. Por ejemplo, Google combina el historial del usuario, la retroalimentación de otros usuarios, la semántica de la página y el significado de la consulta, mientras también considera elementos contextuales como el tiempo (hora del día, día de la semana) y eventos externos como noticias de última hora.
5. Aprendizaje Profundo para el Ranking Primario
En la etapa de recuperación inicial, Google utiliza tecnologías como RankBrain y Neural Matching para entender la semántica de las consultas y filtrar los resultados más relevantes de grandes colecciones de documentos.
RankBrain, introducido por Google en 2015, es un sistema de aprendizaje automático diseñado para comprender mejor el significado de las consultas de los usuarios, especialmente las consultas nunca antes vistas. Transforma consultas y documentos en representaciones vectoriales y calcula su similitud para encontrar los resultados más relevantes. Por ejemplo, para la consulta “cómo hacer masa para pizza”, incluso si ningún documento contiene una coincidencia exacta de palabras clave, RankBrain puede identificar contenido relacionado con “conceptos básicos de pizza” o “preparación de masa.”
Neural Matching, lanzado en 2018, fue diseñado para capturar mejor la relación semántica entre las consultas y los documentos. Utilizando modelos de redes neuronales, identifica relaciones difusas entre las palabras para hacer coincidir mejor las consultas con el contenido web. Por ejemplo, para la consulta "¿por qué es tan ruidoso el ventilador de mi laptop?", Neural Matching puede entender que el usuario podría estar buscando información de solución de problemas sobre sobrecalentamiento, acumulación de polvo o alto uso de CPU, incluso si esos términos no aparecen explícitamente en la consulta.
6. Re-ranking profundo: La aplicación de BERT
Después del filtrado inicial de documentos relevantes, Google aplica BERT (Representaciones de Codificadores Bidireccionales de Transformers) para refinar el ranking y asegurar que los resultados más relevantes aparezcan en la parte superior. BERT es un modelo de lenguaje preentrenado basado en Transformers que puede comprender las relaciones contextuales de las palabras dentro de las oraciones.
En la búsqueda, BERT se utiliza para volver a clasificar los documentos recuperados en etapas anteriores. Codifica conjuntamente las consultas y los documentos, calcula sus puntuaciones de relevancia y luego reorganiza los documentos. Por ejemplo, para la consulta "estacionar en una colina sin bordillo", BERT puede interpretar correctamente el significado de "sin bordillo" y devolver resultados que aconsejan a los conductores que giren sus ruedas hacia el borde de la carretera, en lugar de malinterpretarlo como una situación con un bordillo.
Para los ingenieros de SEO, esto significa que deben estudiar cuidadosamente los algoritmos de clasificación y recomendación de aprendizaje automático de Google para optimizar el contenido web de manera específica, obteniendo así una mayor visibilidad en los rankings de búsqueda.
Por qué la IA remodelará los navegadores
Primero, necesitamos aclarar: ¿por qué necesita existir aún el navegador como una forma? ¿Hay un tercer paradigma más allá de los agentes de IA y los navegadores?
Creemos que la existencia implica irremplazabilidad. ¿Por qué la inteligencia artificial puede usar navegadores pero no reemplazarlos por completo? Porque el navegador es una plataforma universal. No solo es un punto de entrada para leer datos, sino también un punto de entrada general para ingresar datos. El mundo no puede solo consumir información; también debe producir datos e interactuar con sitios web. Por lo tanto, los navegadores que integren información personalizada del usuario continuarán existiendo ampliamente.
Aquí está el punto clave: como una puerta de enlace universal, el navegador no solo es para leer datos; los usuarios a menudo necesitan interactuar con los datos. El navegador en sí es un excelente repositorio para almacenar huellas digitales de los usuarios. Comportamientos de usuario más complejos y acciones automatizadas deben llevarse a cabo a través del navegador. El navegador puede almacenar todas las huellas digitales de comportamiento del usuario, credenciales y otra información privada, lo que permite la invocación sin confianza durante la automatización. La interacción con los datos puede evolucionar hacia este patrón:
Usuario → llama a Agente AI → Navegador.
En otras palabras, la única parte que podría ser reemplazada se encuentra en la tendencia natural del mundo—hacia una mayor inteligencia, personalización y automatización. Sin duda, esta parte puede ser manejada por agentes de IA. Pero los agentes de IA en sí mismos no son adecuados para llevar contenido personalizado para el usuario, porque enfrentan múltiples desafíos en cuanto a la seguridad de los datos y la usabilidad. Específicamente:
El navegador es el repositorio de contenido personalizado:
La mayoría de los modelos grandes están alojados en la nube, con contextos de sesión dependientes del almacenamiento del servidor, lo que dificulta el acceso directo a contraseñas locales, billeteras, cookies y otros datos sensibles.
Enviar todos los datos de navegación y pago a modelos de terceros requiere una nueva autorización del usuario; tanto la DMA de la UE como las leyes de privacidad a nivel estatal en EE. UU. exigen la minimización de datos a través de las fronteras.
El llenado automático de los códigos de autenticación de dos factores, la invocación de cámaras o el uso de GPUs para la inferencia de WebGPU deben realizarse dentro del sandbox del navegador.
El contexto de datos depende en gran medida del navegador. Las pestañas, las cookies, IndexedDB, la caché del Service Worker, las credenciales de clave de acceso y los datos de la extensión se almacenan dentro del navegador.
Cambios profundos en las formas de interacción
Regresando al tema desde el principio, nuestro comportamiento al usar navegadores se puede dividir generalmente en tres categorías: leer datos, ingresar datos e interactuar con datos. Los grandes modelos de lenguaje (LLMs) ya han cambiado profundamente la eficiencia y los métodos con los que leemos datos. La antigua práctica de que los usuarios buscaran páginas web a través de palabras clave ahora parece obsoleta e ineficiente.
Cuando se trata de la evolución del comportamiento de búsqueda de los usuarios—ya sea que el objetivo sea obtener respuestas resumidas o hacer clic en páginas web—muchos estudios ya han analizado este cambio.
En términos de patrones de comportamiento del usuario, un estudio de 2024 mostró que en EE. UU., de cada 1,000 consultas en Google, solo 374 terminaron en un clic en una página web abierta. En otras palabras, casi el 63% fueron comportamientos de "cero clics". Los usuarios se han acostumbrado a obtener información como el clima, tasas de cambio y tarjetas de conocimiento directamente de la página de resultados de búsqueda.
Lo que realmente podría desencadenar una transformación masiva de los navegadores, sin embargo, es la capa de interacción de datos. En el pasado, las personas interactuaban con los navegadores principalmente ingresando palabras clave, el nivel máximo de comprensión que el propio navegador podía manejar. Ahora, los usuarios prefieren cada vez más utilizar un lenguaje natural completo para describir tareas complejas, como:
“Encuéntrame vuelos directos de Nueva York a Los Ángeles durante un cierto período.”
"Encuéntrame un vuelo de Nueva York a Shanghái y luego a Los Ángeles."
Incluso para los humanos, tales tareas requieren mucho tiempo para visitar múltiples sitios web, reunir información y comparar resultados. Pero estas Tareas Agenciales están siendo gradualmente asumidas por agentes de IA.
Esto también se alinea con la trayectoria de la historia: automatización e inteligencia. Las personas desean liberarse de las manos, y los agentes de IA estarán inevitablemente profundamente integrados en los navegadores. Los navegadores futuros deben ser diseñados con la automatización completa en mente, especialmente considerando:
Cómo equilibrar la experiencia de lectura para los humanos con la interpretabilidad de máquina para los agentes de IA.
Cómo asegurar que una sola página web sirva tanto al usuario final como al modelo de agente.
Solo al cumplir con ambos requisitos de diseño, los navegadores pueden convertirse verdaderamente en portadores estables para que los agentes de IA ejecuten tareas.
A continuación, nos centraremos en cinco proyectos destacados: Browser Use, Arc (The Browser Company), Perplexity, Brave y Donut. Estos proyectos representan direcciones futuras para la evolución de los navegadores de IA, así como su potencial para la integración nativa dentro de contextos de Web3 y criptomonedas.
Desde la perspectiva de la psicología del usuario, una encuesta de 2023 mostró que el 44% de los encuestados consideraba que los resultados orgánicos regulares eran más confiables que los fragmentos destacados. La investigación académica también ha encontrado que en casos de controversia o falta de una única verdad autoritaria, los usuarios prefieren páginas de resultados que contengan enlaces de múltiples fuentes.
En otras palabras, mientras que una parte de los usuarios no confía completamente en los resúmenes generados por IA, un porcentaje significativo del comportamiento ya se ha desplazado hacia el "cero clic". Por lo tanto, los navegadores de IA aún necesitan explorar el paradigma de interacción correcto, especialmente en el área de lectura de datos. Debido a que el problema de la alucinación en los modelos grandes aún no se ha resuelto por completo, muchos usuarios todavía luchan por confiar completamente en los resúmenes de contenido generados automáticamente. En este sentido, incrustar modelos grandes en los navegadores no requiere necesariamente una transformación disruptiva. En cambio, simplemente requiere mejoras incrementales en precisión y controlabilidad, un proceso que ya está en marcha.
Uso del Navegador
Esta es precisamente la lógica central detrás de la enorme financiación recibida por Perplexity y Browser Use. En particular, Browser Use ha surgido como la segunda oportunidad de innovación más prometedora de principios de 2025, con certeza y un fuerte potencial de crecimiento.

El uso del navegador ha construido una verdadera capa semántica, con su enfoque central en crear una arquitectura de reconocimiento semántico para la próxima generación de navegadores.
Browser Use reinterpreta el tradicional "DOM = un árbol de nodos para que los humanos lo vean" como un "DOM Semántico = un árbol de instrucciones para que los LLMs lo lean." Esto permite a los agentes hacer clic, completar y subir sin depender de "coordenadas de píxeles." En lugar de usar OCR visual o Selenium basado en coordenadas, este enfoque toma la ruta de "texto estructurado → llamadas a funciones," haciendo que la ejecución sea más rápida, ahorrando tokens y reduciendo errores. TechCrunch lo describió como "la capa de unión que permite a la IA realmente entender las páginas web." En marzo, Browser Use cerró una ronda semilla de 17 millones de dólares, apostando por esta innovación fundamental.
Así es como funciona:
Después de que se renderiza HTML, se forma un árbol DOM estándar. Luego, el navegador deriva un árbol de accesibilidad, que proporciona etiquetas de “roles” y “estados” más ricas para los lectores de pantalla.
Cada elemento interactivo (botón, entrada, etc.) se abstrae en un fragmento JSON con metadatos como rol, visibilidad, coordenadas y acciones ejecutables.
La página completa se traduce en una lista aplanada de nodos semánticos, que el LLM puede leer en un solo aviso del sistema.
El LLM genera instrucciones de alto nivel (por ejemplo, click(node_id="btn-Checkout")), que luego se reproducen en el navegador real.
El blog oficial describe este proceso como “convertir las interfaces de los sitios web en texto estructurado que los LLMs pueden analizar.”
Además, si este estándar es adoptado por el W3C, podría solucionar en gran medida el problema de entrada del navegador. A continuación, analizaremos la carta abierta y los estudios de caso de The Browser Company para explicar más a fondo por qué su enfoque es defectuoso.
Arco
La empresa Browser Company (la empresa matriz de Arc) declaró en su carta abierta que el navegador Arc ingresará en un modo de mantenimiento regular, mientras que el equipo cambiará su enfoque hacia el desarrollo de DIA, un navegador totalmente orientado hacia la IA. En la carta, también admitieron que el camino de implementación específico para DIA aún no se ha determinado. Al mismo tiempo, el equipo esbozó varias predicciones sobre el futuro del mercado de navegadores.
Basado en estas predicciones, creemos además que si el actual panorama de los navegadores va a ser realmente interrumpido, la clave radica en cambiar el lado de salida de la interacción.
A continuación se presentan tres de las predicciones sobre el futuro del mercado de navegadores compartidas por el equipo de Arc.
https://browsercompany.substack.com/p/letter-to-arc-members-2025
Primero, el equipo de Arc cree que las páginas web ya no serán la interfaz principal para la interacción. Admitidamente, esta es una afirmación audaz y desafiante, y también es la razón principal por la que seguimos escépticos de las reflexiones de su fundador. En nuestra opinión, esta perspectiva subestima significativamente el papel del navegador, y resalta el problema clave que el equipo pasó por alto al explorar el camino del navegador de IA.
Los modelos grandes funcionan excelentemente al captar la intención—por ejemplo, entender instrucciones como “ayúdame a reservar un vuelo.” Sin embargo, siguen siendo insuficientes cuando se trata de llevar densidad de información. Cuando un usuario necesita algo como un tablero, un cuaderno al estilo de Bloomberg Terminal, o un lienzo visual como Figma, nada puede superar una página web finamente ajustada con precisión a nivel de píxel. La ergonomía de cada producto—gráficos, funcionalidad de arrastrar y soltar, teclas de acceso rápido—no son una decoración superficial, sino affordances esenciales que comprimen la cognición. Estas capacidades no pueden ser replicadas por interacciones conversacionales simples. Tomando Gate.com como ejemplo: si un usuario quiere ejecutar una acción de inversión, confiar únicamente en la conversación de IA está lejos de ser suficiente, ya que los usuarios dependen en gran medida de la entrada estructurada, la precisión y la presentación clara de la información.
El roadmap del equipo de Arc contiene un defecto fundamental: no logra distinguir claramente que "interacción" se compone de dos dimensiones: entrada y salida. En el lado de la entrada, su visión tiene cierta validez en ciertos escenarios, ya que la IA puede mejorar la eficiencia de las interacciones de estilo comando. Pero en el lado de la salida, su suposición es claramente desequilibrada, pasando por alto el papel central del navegador en la presentación de información y experiencias personalizadas. Por ejemplo, Reddit tiene su propio diseño único y arquitectura de información, mientras que AAVE tiene una interfaz y estructura completamente diferentes. Como una plataforma que almacena simultáneamente datos altamente privados y presenta diversas interfaces de productos, el navegador tiene una sustitución limitada en el lado de la entrada, mientras que su complejidad y naturaleza no estandarizada en el lado de la salida hacen que sea aún más difícil de interrumpir.
Por el contrario, los navegadores de IA actuales se concentran principalmente en la capa de "resumen de salida": resumiendo páginas, extrayendo información, generando conclusiones. Esto no es suficiente para representar un desafío fundamental a los navegadores convencionales o sistemas de búsqueda como Google; simplemente reduce la participación de mercado de los resúmenes de búsqueda.
Por lo tanto, la única tecnología que podría realmente sacudir la cuota de mercado del 66% de Chrome está destinada a no ser "el próximo Chrome". Para lograr una verdadera disrupción, el modelo de renderizado de los navegadores debe ser reestructurado fundamentalmente para adaptarse a las necesidades de interacción de la era del Agente de IA, especialmente en términos de diseño de la arquitectura del lado de entrada. Es por eso que encontramos el camino técnico que ha tomado Browser Use mucho más convincente: se centra en cambios estructurales en el mecanismo subyacente de los navegadores. Una vez que cualquier sistema logra un diseño "atómico" o "modular", la programabilidad y la composabilidad derivadas de él desbloquean un potencial disruptivo. Esta es exactamente la dirección que Browser Use está persiguiendo hoy.
En resumen, la operación de los agentes de IA todavía depende en gran medida de la existencia de navegadores. Los navegadores no solo son los principales repositorios de datos personalizados complejos, sino también las interfaces de representación universales para diversas aplicaciones, y por lo tanto, continuarán sirviendo como la puerta de enlace central para la interacción en el futuro. A medida que los agentes de IA se integran profundamente en los navegadores para completar tareas fijas, interactuarán con los datos de los usuarios y aplicaciones específicas principalmente a través del lado de entrada. Por esta razón, el modelo de representación actual de los navegadores debe ser innovado para lograr la máxima compatibilidad y adaptabilidad con los agentes de IA, lo que en última instancia les permitirá capturar aplicaciones de manera más efectiva.
Perplejidad
Perplexity es un motor de búsqueda de IA famoso por su sistema de recomendaciones. Su última valoración ha aumentado a $14 mil millones, casi un aumento de cinco veces desde $3 mil millones en junio de 2024. Ahora maneja más de 400 millones de consultas de búsqueda al mes. Solo en septiembre de 2024, procesó alrededor de 250 millones de consultas, marcando un aumento interanual de ocho veces en el volumen de búsquedas de los usuarios, con más de 30 millones de usuarios activos mensuales.
Su característica principal es la capacidad de resumir páginas en tiempo real, lo que le brinda una gran ventaja para acceder a información actualizada. A principios de este año, Perplexity comenzó a construir su propio navegador nativo, Comet. La compañía describe Comet como un navegador que no solo "muestra" páginas web, sino que también "piensa" en ellas. Oficialmente, afirman que integrará el motor de respuestas de Perplexity profundamente dentro del propio navegador, siguiendo un enfoque de "máquina completa" que recuerda la filosofía de Steve Jobs: integrar profundamente las tareas de IA a nivel fundamental del navegador, en lugar de simplemente construir complementos en la barra lateral.
Con respuestas concisas respaldadas por citas, Comet tiene como objetivo reemplazar los tradicionales "diez enlaces azules" y competir directamente con Chrome.
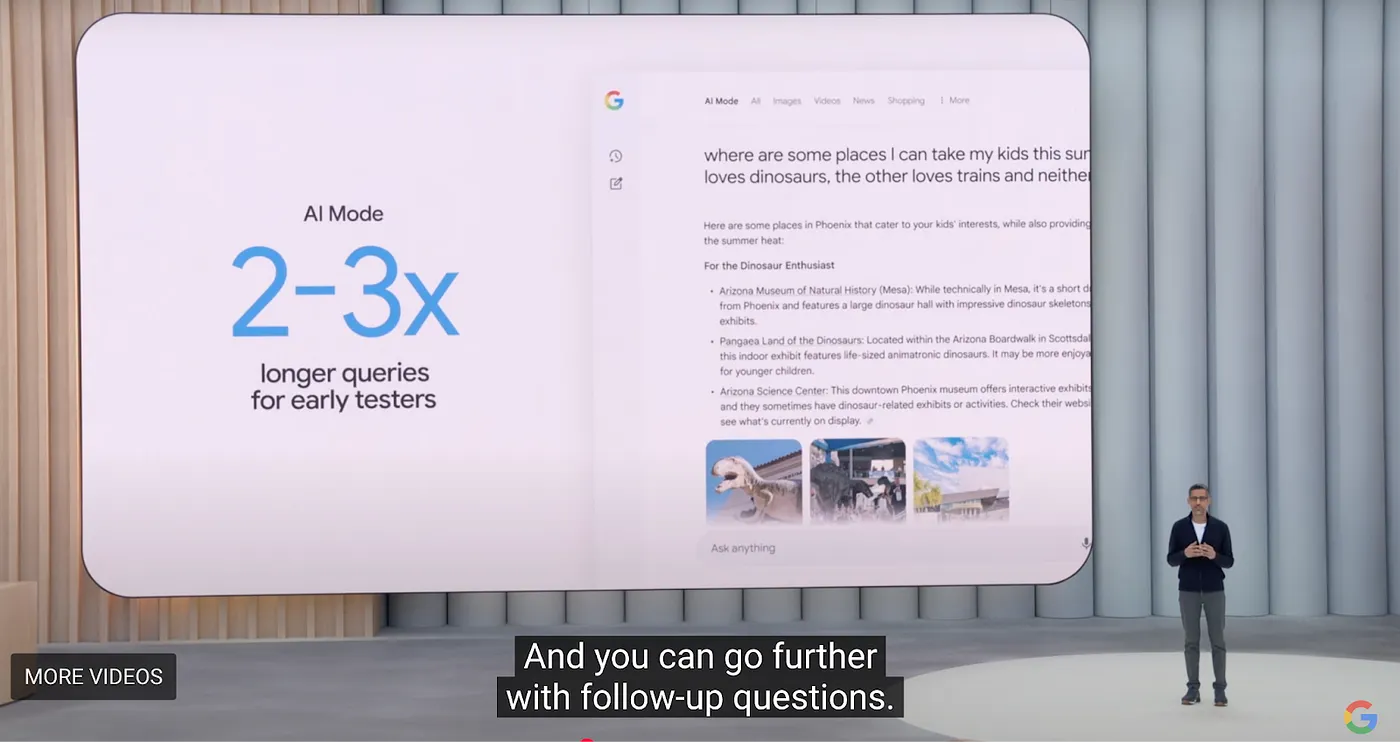
Pero Perplexity aún necesita resolver dos problemas centrales: altos costos de búsqueda y bajos márgenes de beneficio de los usuarios marginales. Aunque Perplexity actualmente lidera en el campo de la búsqueda de IA, Google anunció en su conferencia I/O de 2025 una revisión inteligente a gran escala de sus productos principales. Para los navegadores, Google lanzó una nueva experiencia de pestaña del navegador llamada AI Model, que integra Overview, Deep Research y futuras capacidades Agentic. La iniciativa completa se denomina "Project Mariner."
Google está avanzando activamente en su transformación de IA, lo que significa que la imitación superficial de características—como Overview, Deep Research o Agentics—difícilmente representará una verdadera amenaza. Lo que podría realmente establecer un nuevo orden en medio del caos es reconstruir la arquitectura del navegador desde cero, incrustando profundamente modelos de lenguaje grande (LLMs) en el núcleo del navegador y transformando fundamentalmente los métodos de interacción.
Valiente
Brave es uno de los navegadores más antiguos y exitosos dentro de la industria crypto. Construido sobre la arquitectura Chromium, es compatible con extensiones de la tienda de Google. Brave atrae a los usuarios con un modelo basado en la privacidad y la obtención de tokens a través de la navegación. Su trayectoria de desarrollo demuestra un cierto potencial de crecimiento. Sin embargo, desde una perspectiva de producto, aunque la privacidad es ciertamente importante, la demanda sigue concentrándose en grupos de usuarios específicos. Para el público en general, la conciencia sobre la privacidad aún no se ha convertido en un factor de decisión generalizado. Por lo tanto, intentar depender de esta característica por sí sola para interrumpir a los gigantes existentes es poco probable que tenga éxito.
Hasta ahora, Brave ha alcanzado 82.7 millones de usuarios activos mensuales (MAU) y 35.6 millones de usuarios activos diarios (DAU), manteniendo una cuota de mercado de alrededor del 1% al 1.5%. Su base de usuarios ha mostrado un crecimiento constante: de 6 millones en julio de 2019, a 25 millones en enero de 2021, a 57 millones en enero de 2023, y para febrero de 2025, superó los 82 millones. Su tasa de crecimiento anual compuesta se mantiene en dos dígitos.
Brave maneja aproximadamente 1.34 mil millones de consultas de búsqueda por mes, lo que representa alrededor del 0.3% del volumen de Google.
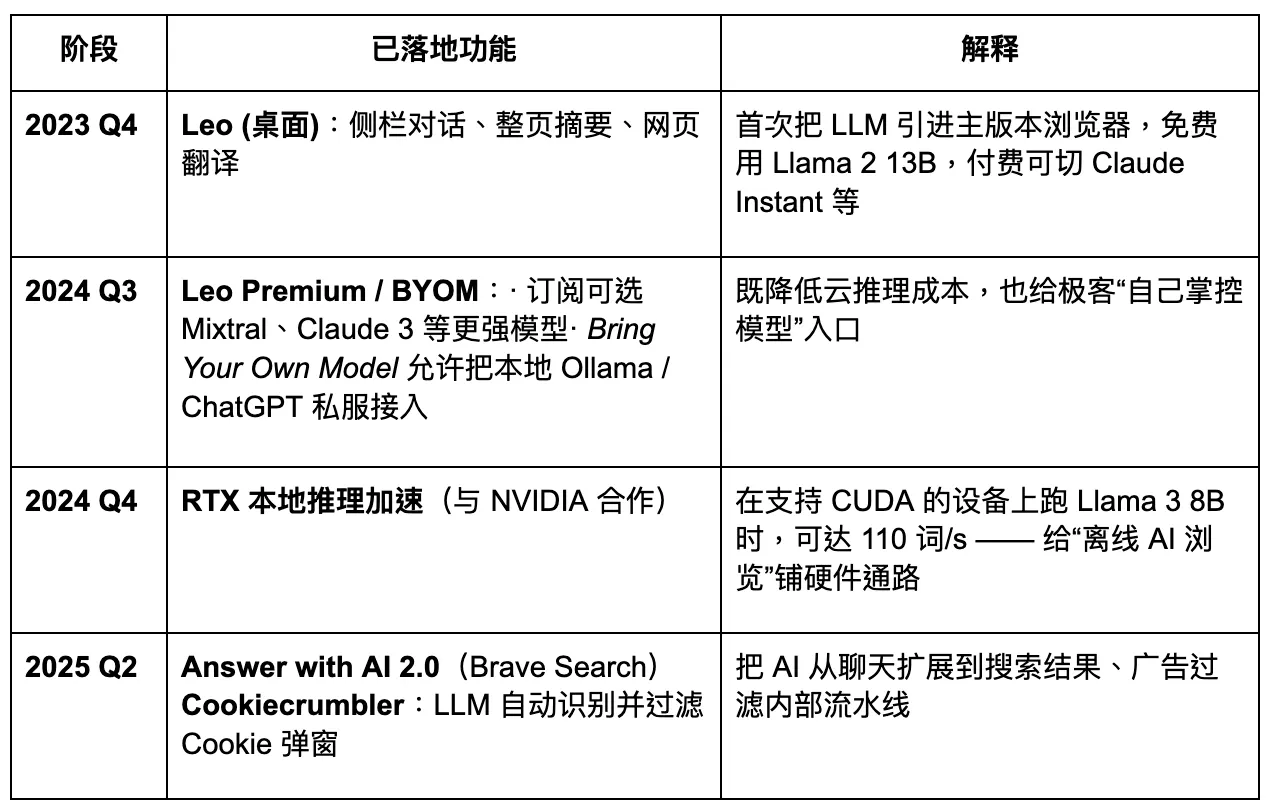
Brave planea actualizarse a un navegador de IA que prioriza la privacidad. Sin embargo, su acceso limitado a los datos de los usuarios reduce el nivel de personalización posible para modelos grandes, lo que a su vez dificulta la iteración rápida y precisa del producto. En la próxima era del Navegador Agente, Brave puede mantener una cuota estable entre grupos específicos de usuarios enfocados en la privacidad, pero será difícil que se convierta en un jugador dominante. Su asistente de IA, Leo, funciona más como una mejora de plugin—ofreciendo algunas capacidades de resumen de contenido, pero careciendo de una estrategia clara para un cambio completo hacia agentes de IA. La innovación en la interacción sigue siendo insuficiente.
Donut
Recientemente, la industria de las criptomonedas también ha avanzado en el campo de los Navegadores Agentes. El proyecto en etapa temprana Donut recaudó $7 millones en una ronda de pre-semilla, liderada por Hongshan (Sequoia China), HackVC y Bitkraft Ventures. El proyecto aún se encuentra en su etapa conceptual inicial, con la visión de lograr "Descubrimiento - Toma de decisiones - y Ejecución nativa de criptomonedas" como una capacidad integrada.
La dirección principal es combinar rutas de ejecución automatizadas nativas de criptomonedas. Como ha predicho a16z, los agentes pueden reemplazar a los motores de búsqueda como la principal puerta de tráfico en el futuro. Los emprendedores ya no competirán alrededor de los algoritmos de clasificación de Google, sino que lucharán por el tráfico y las conversiones que provienen de la ejecución de agentes. La industria ya ha nombrado esta tendencia "AEO" (Optimización de Motor de Respuesta / Agente), o incluso más, "ATF" (Cumplimiento de Tareas Agénticas), donde el objetivo ya no es optimizar las clasificaciones de búsqueda, sino servir directamente a modelos inteligentes que pueden completar tareas para los usuarios, como realizar pedidos, reservar boletos o escribir cartas.
Para Emprendedores
Primero, debe reconocerse: el navegador en sí mismo sigue siendo el mayor "Gateway" no reconstruido en el mundo de internet. Con alrededor de 2.1 mil millones de usuarios de escritorio y más de 4.3 mil millones de usuarios móviles a nivel mundial, sirve como el transportista común para la entrada de datos, el comportamiento interactivo y el almacenamiento de huellas personalizadas. La razón de su persistencia no es la inercia, sino la doble naturaleza inherente del navegador: es tanto el punto de entrada para leer datos como el punto de salida para las acciones de escritura.
Por lo tanto, para los emprendedores, el verdadero potencial disruptivo no radica en optimizar la capa de "salida de página". Incluso si se pudieran replicar funciones de visión general de IA similares a las de Google en una nueva pestaña, eso seguiría siendo solo una iteración en la capa de plugin, no un cambio de paradigma fundamental. El verdadero avance radica en el "lado de entrada": cómo hacer que los agentes de IA llamen activamente a tu producto para completar tareas específicas. Esto determinará si un producto puede integrarse en el ecosistema de agentes, captar tráfico y compartir en la distribución del valor.
En la era de búsqueda, la competencia se trataba de clics; en la era de agentes, se trata de llamadas.
Si eres un emprendedor, debes reinventar tu producto como un componente de API—algo que un agente inteligente no solo pueda entender, sino también invocar. Esto requiere que consideres tres dimensiones desde el inicio del diseño del producto:
1. Estandarización de la Estructura de la Interfaz: ¿Es su producto invocable?
La capacidad de un agente para invocar un producto depende de si su estructura de información puede ser estandarizada y abstraída en un esquema claro. Por ejemplo, ¿se pueden describir acciones clave como el registro de usuarios, la realización de pedidos o la presentación de comentarios a través de una estructura DOM semántica o un mapeo JSON? ¿Proporciona el sistema una máquina de estados para que el agente pueda replicar de manera confiable los flujos de trabajo de los usuarios? ¿Se pueden guionizar las interacciones de los usuarios en la página? ¿Ofrece el producto webhooks o puntos finales de API estables?
Esta es precisamente la razón por la que Browser Use tuvo éxito en la recaudación de fondos: transformó el navegador de un renderizador HTML plano en un árbol semántico que puede ser llamado por LLMs. Para los emprendedores, adoptar una filosofía de diseño similar en los productos web significa prepararse para una adaptación estructurada en la era de los agentes de IA.
2. Identidad y Acceso: ¿Puedes ayudar a los agentes a "cruzar la barrera de confianza"?
Para que los agentes completen transacciones o llamen funciones de pago y activos, requieren un intermediario de confianza: ¿podrías ser ese intermediario? Los navegadores, por naturaleza, tienen la capacidad de leer el almacenamiento local, acceder a billeteras, manejar CAPTCHAs e integrar la autenticación de dos factores. Esto los hace más adecuados que los modelos alojados en la nube para ejecutar tareas. Esto es especialmente cierto en Web3, donde las interfaces de interacción de activos no están estandarizadas. Sin "identidad" o "capacidad de firma", un agente no puede avanzar.
Para los emprendedores de criptomonedas, esto abre un espacio en blanco altamente imaginativo: el “MCP (Plataforma de Múltiples Capacidades) del mundo blockchain.” Esto podría tomar la forma de una capa de comando universal (permitiendo a los agentes llamar a Dapps), un conjunto de interfaces de contratos estandarizadas, o incluso una billetera local ligera + centro de identidad.
3. Repensando los mecanismos de tráfico: el futuro no es SEO, sino AEO / ATF.
En el pasado, tenías que ganar el algoritmo de Google; ahora necesitas estar incrustado en las cadenas de tareas de los agentes de IA. Esto significa que tu producto debe tener una clara granularidad de tareas: no una "página", sino una serie de unidades de capacidad llamables. También significa comenzar a optimizar para la Optimización del Motor de Agentes (AEO) o adaptarse al Cumplimiento de Tareas Agénticas (ATF). Por ejemplo, ¿se puede simplificar el proceso de registro en pasos estructurados? ¿Se puede extraer el precio a través de una API? ¿Está el inventario accesible en tiempo real?
Es posible que incluso necesites adaptarte a diferentes sintaxis de llamada en los marcos de LLM, ya que OpenAI y Claude, por ejemplo, tienen diferentes preferencias para las llamadas a funciones y el uso de herramientas. Chrome es el terminal del viejo mundo, no la puerta de entrada al nuevo. Los proyectos del futuro no reconstruirán navegadores, sino que harán que los navegadores sirvan a los agentes, construyendo puentes para la nueva generación de "flujos de instrucciones."
Lo que necesitas construir es el "lenguaje de interfaz" a través del cual los agentes llaman a tu mundo.
Lo que necesitas ganar es un lugar en la cadena de confianza de los sistemas inteligentes.
Lo que necesitas construir es un "castillo API" en el próximo paradigma de búsqueda.
Si Web2 capturó la atención del usuario a través de la interfaz de usuario, entonces la era de Web3 + Agente de IA capturará la intención de ejecución del agente a través de cadenas de llamadas.
Descargo de responsabilidad
Este contenido no constituye una oferta, solicitud o recomendación. Siempre debe buscar asesoramiento profesional independiente antes de tomar cualquier decisión de inversión. Tenga en cuenta que Gate y/o Gate Ventures pueden restringir o prohibir algunos o todos los servicios en regiones restringidas. Por favor, lea el acuerdo de usuario aplicable para más detalles.
Acerca de Gate Ventures
Gate Ventures es el brazo de capital de riesgo de Gate, centrado en inversiones en infraestructura descentralizada, ecosistemas y aplicaciones: tecnologías que transformarán el mundo en la era Web 3.0. Gate Ventures trabaja con líderes de la industria global para empoderar a equipos y startups con pensamiento innovador y capacidades para redefinir la forma en que la sociedad y las finanzas interactúan.
Sitio web: https://www.gate.com/ventures
Compartir
Contenido
TL;DR
Una Breve Historia del Desarrollo de Navegadores
La arquitectura obsoleta de los navegadores modernos
Por qué la IA transformará los navegadores
Cambios profundos en las formas de interacción
Uso del navegador
Arco
Perplejidad
Brave
Donut
Para emprendedores
Descargo de responsabilidad
Acerca de Gate Ventures

