El auge de la inteligencia artificial está transformando la industria global de los semiconductores. Con la creciente demanda de modelos de lenguaje de gran tamaño, IA generativa y computación de alto rendimiento, el volumen de datos que deben procesar los chips de cómputo crece de forma exponencial. En este contexto, las tecnologías de memoria tradicionales están alcanzando sus límites en ancho de banda y eficiencia energética, mientras que la HBM (High Bandwidth Memory), que permite una transferencia de datos ultrarrápida, se ha consolidado como un pilar fundamental de la infraestructura de IA.
En el mercado global de HBM, SK Hynix ocupa una posición destacada. Como uno de los principales fabricantes de chips de memoria del mundo, SK Hynix no solo cuenta con una profunda experiencia en DRAM, sino que también tomó la delantera en el desarrollo y la producción en masa de productos HBM. Dado que las GPU de IA exigen memorias cada vez más rápidas, SK Hynix se ha convertido en un proveedor clave en la cadena de suministro de chips de memoria para IA.
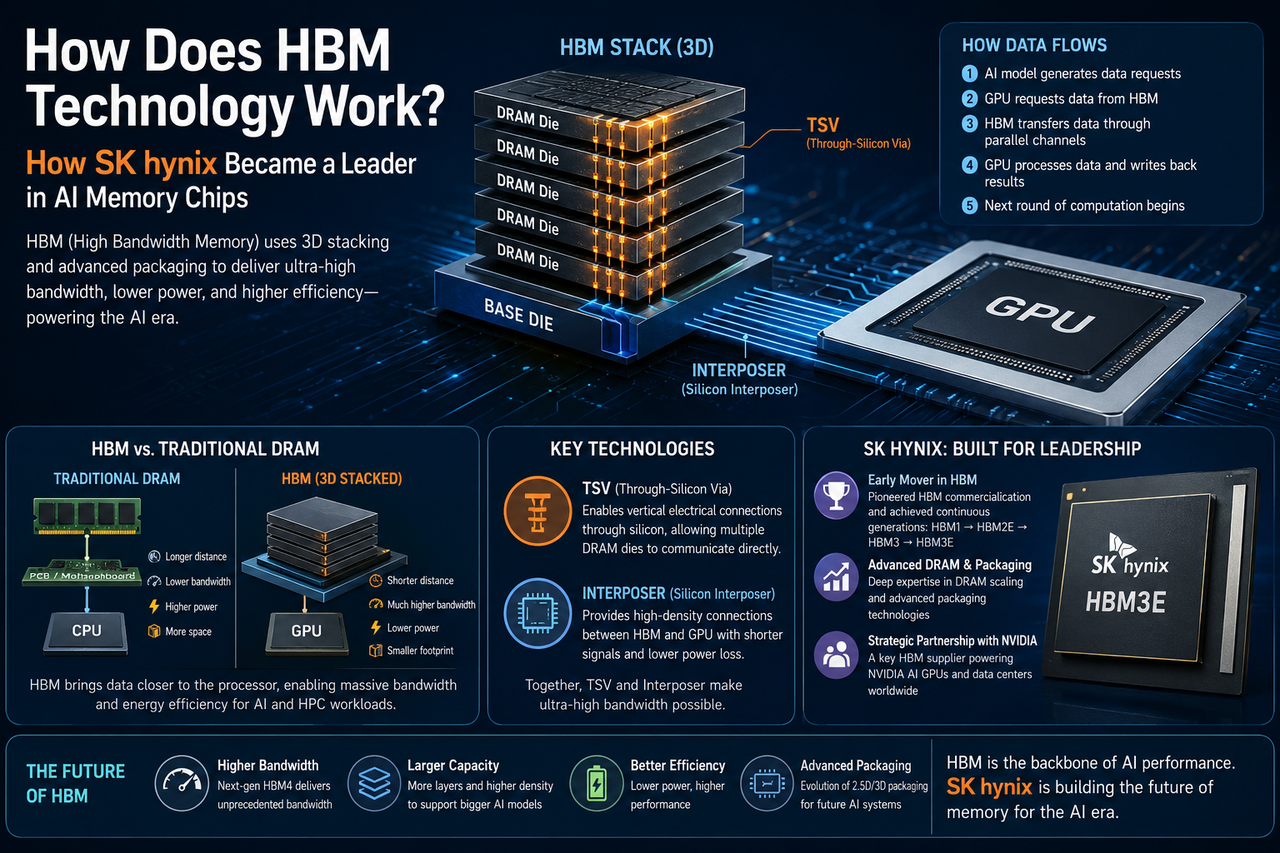
¿Qué es HBM?
HBM (High Bandwidth Memory) es una tecnología de memoria de alto ancho de banda diseñada específicamente para entornos de IA, computación de alto rendimiento (HPC), centros de datos y procesamiento gráfico. Frente a la DRAM tradicional, HBM ofrece un rendimiento de datos muy superior en un espacio mucho más reducido.
La innovación clave de HBM reside en su arquitectura de apilamiento 3D: varios chips DRAM se apilan verticalmente y se interconectan a alta velocidad mediante la tecnología TSV (Through-Silicon Via). Al recorrer distancias más cortas, HBM aumenta drásticamente el ancho de banda y reduce el consumo de energía.
Por qué la DRAM tradicional se queda corta para la IA
Durante años, la DRAM tradicional ha sido la solución de memoria estándar para ordenadores y servidores. Sin embargo, las exigencias de datos de la era de la IA han superado con creces las de la computación convencional.
Durante el entrenamiento de modelos grandes, las GPU deben leer y escribir constantemente enormes cantidades de parámetros. Si los datos no se mueven con la suficiente rapidez para mantener alimentada la GPU, incluso los procesadores más potentes desperdician ciclos esperando.
La DRAM tradicional presenta problemas con:
| Desafío |
Rendimiento de la DRAM tradicional |
| Techo de ancho de banda |
Rendimiento de datos limitado |
| Alto consumo de energía |
Las rutas de datos más largas aumentan el gasto energético |
| Gran huella física |
Difícil de encajar en despliegues densos |
| Escalabilidad para IA |
La eficiencia disminuye en configuraciones con varias GPU |
Por eso la industria ha recurrido a nuevas arquitecturas de memoria más adecuadas para la IA, y HBM ha despegado.
Cómo funciona la tecnología HBM
La idea central de HBM: acortar la distancia que deben recorrer los datos y aumentar significativamente el número de canales de datos.
La DRAM tradicional se conecta al procesador a través de la placa base. HBM, en cambio, se empaqueta directamente junto a la GPU. Varios troqueles DRAM se apilan verticalmente mediante TSV, y un interponedor de silicio los vincula a la GPU para lograr una comunicación de ultra alto ancho de banda.
El flujo de datos funciona así:
- Un modelo de IA que se ejecuta en la GPU genera un flujo constante de solicitudes de datos.
- La GPU envía comandos de lectura a HBM.
- HBM devuelve los datos a través de múltiples canales paralelos a una velocidad vertiginosa.
- Una vez finalizado el cálculo, la GPU escribe los resultados de vuelta en la memoria.
- El siguiente ciclo de cálculo comienza de inmediato.
Este diseño minimiza la latencia del movimiento de datos y mejora drásticamente la eficiencia del entrenamiento de IA.
HBM frente a DRAM tradicional: diferencias estructurales
| Dimensión |
HBM |
DRAM tradicional |
| Arquitectura del chip |
Apilamiento 3D |
Diseño plano |
| Interconexión de datos |
TSV + Interponedor |
Trazas de PCB |
| Ancho de banda |
Ultra alto |
Moderado |
| Consumo de energía |
Menor |
Mayor |
| Casos de uso principales |
IA, GPU, HPC |
PC, servidores |
Por qué son importantes el TSV y el interponedor
TSV (Through-Silicon Via) es la tecnología que permite el apilamiento 3D de HBM. Crea canales verticales a través del chip, lo que permite que las capas de memoria apiladas se comuniquen directamente entre sí. El interponedor (interponedor de silicio) actúa como puente de conexión entre la GPU y HBM, proporcionando vías de datos mucho más densas y una menor pérdida de señal que las trazas tradicionales de la placa base.
Juntas, estas dos tecnologías forman la columna vertebral de la arquitectura HBM y son las razones principales por las que puede alcanzar un ancho de banda tan extremo.
El papel de HBM en el entrenamiento de IA
Los modelos de IA modernos contienen miles de millones o incluso billones de parámetros. Cada ejecución de entrenamiento requiere leer conjuntos de datos masivos.
Si la GPU calcula más rápido de lo que se pueden suministrar los datos, el sistema experimenta capacidad de cómputo ociosa. La función de HBM es mantener llena la canalización de datos, garantizando que la GPU pueda trabajar con la máxima eficiencia.
En la inferencia de IA, HBM es igualmente crítica. Un acceso rápido a la memoria acelera los tiempos de respuesta y mejora el rendimiento del modelo. Por eso HBM se ha convertido en un componente indispensable en el diseño de chips de IA.
Cómo se convirtió SK Hynix en líder de HBM
SK Hynix tiene profundas raíces en la tecnología DRAM, lo que sentó las bases para sus avances en HBM.
La empresa fue una de las primeras en comercializar HBM. Desde HBM1 hasta HBM3E, SK Hynix ha ido superando constantemente los límites en ancho de banda, capacidad, eficiencia energética y empaquetado avanzado.

Antes del auge de la IA, el mercado de HBM era relativamente nicho. Sin embargo, SK Hynix siguió invirtiendo en I+D. Para cuando la IA generativa y los grandes modelos dispararon la demanda, la empresa ya contaba con tecnología madura y capacidad de producción lista para usar.
Este posicionamiento estratégico a largo plazo le otorgó a SK Hynix una ventaja competitiva formidable.
SK Hynix y NVIDIA: una alianza estratégica
Las GPU de IA representan el mayor mercado de aplicación para HBM, y NVIDIA es un actor importante en el ámbito de los chips de IA.
Las GPU de IA de primer nivel actuales requieren subsistemas de memoria masivos y de alto ancho de banda. HBM se ha convertido en el estándar para las GPU de gama alta, y SK Hynix es un proveedor clave de HBM.
Esta relación permite a SK Hynix desempeñar un papel central en la construcción de infraestructura de IA, y refuerza su importancia estratégica en la cadena de suministro global de semiconductores.
El futuro de HBM
A medida que los modelos de IA siguen creciendo, la tecnología HBM continúa evolucionando.
Tendencias clave en el horizonte:
| Dirección tecnológica |
Objetivo |
| HBM4 |
Ancho de banda y capacidad aún mayores |
| Más capas de apilamiento |
Mayor densidad de memoria |
| Empaquetado avanzado |
Menor latencia y consumo |
| Memoria optimizada para IA |
Mejor eficiencia de entrenamiento |
| Integración con chiplets |
Escalabilidad del sistema mejorada |
En el futuro, las ganancias de rendimiento en los chips de IA dependerán no solo de la GPU en sí, sino cada vez más de la innovación en memorias.
HBM frente a GDDR: ¿cuál es la diferencia?
Tanto HBM como GDDR son memorias de alto rendimiento, pero están diseñadas para trabajos diferentes.
GDDR está pensada para tarjetas gráficas de consumo y aumenta la velocidad mediante frecuencias de reloj más altas. HBM, en cambio, logra su rendimiento a través de un bus ultra ancho y apilamiento vertical, ofreciendo mayor ancho de banda y menor consumo. En entornos de entrenamiento de IA, HPC y centros de datos, HBM suele tener una clara ventaja.
Resumen
HBM es una de las tecnologías de memoria más importantes de la era de la IA. Mediante el apilamiento 3D, TSV e interponedores de silicio, ofrece un ancho de banda que supera con creces a la DRAM tradicional. A medida que el entrenamiento de modelos grandes y la computación de alto rendimiento exigen más, HBM se ha vuelto esencial para las GPU de IA y la infraestructura de centros de datos.
Gracias a décadas de experiencia en DRAM, habilidades de empaquetado avanzado y una inversión incesante en HBM, SK Hynix se ha consolidado como líder mundial. Desde chips de IA hasta centros de datos, pasando por GPU y superordenadores, HBM impulsa el crecimiento de la computación de IA, y SK Hynix se sitúa en el centro de esta cadena de suministro crítica.
Preguntas frecuentes
¿Por qué HBM es mejor para la IA que la DRAM tradicional?
HBM ofrece un ancho de banda mucho mayor, menor latencia y menor consumo de energía. El entrenamiento de modelos de IA lee constantemente grandes conjuntos de datos, por lo que HBM es una opción mucho más adecuada para las necesidades de memoria de las GPU.
¿Qué es la tecnología TSV?
TSV (Through-Silicon Via) crea conexiones eléctricas verticales a través de chips apilados. HBM utiliza TSV para lograr un empaquetado 3D denso.
¿Cuál es la diferencia entre HBM y GDDR?
GDDR está diseñada para renderizado gráfico; HBM está pensada para IA, HPC y centros de datos. HBM suele ofrecer un ancho de banda y una eficiencia energética superiores.
¿Por qué SK Hynix lidera el mercado de HBM?
SK Hynix invirtió temprano en HBM y tiene una profunda experiencia en fabricación de DRAM y empaquetado avanzado. Cuando la demanda de IA explotó, la empresa contaba con productos maduros y producción lista para escalar.
¿Qué cambiará con HBM4?
Se espera que HBM4 lleve el ancho de banda, la capacidad y la eficiencia energética aún más lejos, dando soporte a cargas de trabajo de entrenamiento de IA más grandes. A medida que la computación de IA sigue escalando, se espera que HBM4 se convierta en una importante solución de memoria para plataformas de alto rendimiento de próxima generación.









