Gate Ventures Research Insights : La Troisième Guerre des Navigateurs : La Bataille d'Entrée à l'Ère des Agents IA
TL;DR
La troisième guerre des navigateurs se déroule tranquillement. En regardant en arrière, de Netscape et Internet Explorer de Microsoft dans les années 1990 à Firefox en open-source et Chrome de Google, la guerre des navigateurs a toujours été une manifestation concentrée du contrôle de la plateforme et des changements de paradigme technologiques. Chrome a sécurisé sa position dominante grâce à sa rapidité de mise à jour et à son écosystème intégré, tandis que Google, à travers son duopole de recherche et de navigateur, a formé une boucle fermée d'accès à l'information.
Mais aujourd'hui, ce paysage est en train de trembler. L'essor des grands modèles de langage (LLMs) permet de plus en plus d'utilisateurs d'accomplir des tâches sans cliquer sur la page des résultats de recherche, tandis que les clics sur les pages web traditionnelles sont en déclin. Parallèlement, des rumeurs selon lesquelles Apple a l'intention de remplacer le moteur de recherche par défaut dans Safari menacent encore davantage la base de profit d'Alphabet (la société mère de Google), et le marché commence à exprimer son malaise face à l'"orthodoxie de la recherche."
Le navigateur lui-même est également en train de redéfinir son rôle. Ce n'est pas seulement un outil pour afficher des pages web, mais aussi un conteneur pour de multiples capacités, y compris la saisie de données, le comportement des utilisateurs et l'identité privée. Bien que les agents IA soient puissants, ils dépendent toujours de la frontière de confiance du navigateur et du bac à sable fonctionnel pour réaliser des interactions complexes avec les pages, accéder aux données d'identité locales et contrôler les éléments de la page web. Les navigateurs évoluent d'interfaces humaines à des plateformes d'appels système pour les agents.
Dans cet article, nous explorons si les navigateurs sont toujours nécessaires. Nous croyons que ce qui pourrait vraiment perturber le paysage actuel du marché des navigateurs n'est pas un autre « meilleur Chrome », mais une nouvelle structure d'interaction : pas seulement l'affichage d'informations, mais l'invocation de tâches. Les futurs navigateurs doivent être conçus pour des agents IA - capables non seulement de lire, mais aussi d'écrire et d'exécuter. Des projets comme Browser Use tentent de sémantiser la structure des pages, transformant les interfaces visuelles en texte structuré pouvant être appelé par LLM, cartographiant les pages aux commandes et réduisant considérablement les coûts d'interaction.
Des projets majeurs testent déjà les eaux : Perplexity construit un navigateur natif, Comet, qui remplace les résultats de recherche traditionnels par de l'IA ; Brave combine la protection de la vie privée avec un raisonnement local, utilisant LLM pour améliorer les capacités de recherche et de blocage ; et des projets natifs de la crypto comme Donut ciblent de nouveaux points d'entrée pour que l'IA interagisse avec des actifs on-chain. Un trait commun parmi ces projets est leur tentative de remodeler la couche d'entrée du navigateur, plutôt que d'embellir sa couche de sortie.
Pour les entrepreneurs, les opportunités se situent dans le triangle de l'entrée, de la structure et de l'accès aux agents. En tant qu'interface pour le futur monde basé sur les agents, le navigateur signifie que ceux qui peuvent fournir des "capabilités" structurées, appelables et fiables deviendront un composant de la plateforme de nouvelle génération. Du SEO à l'AEO (Optimisation du Moteur d'Agents), du trafic de page à l'invocation de chaînes de tâches, la forme du produit et la pensée design sont en train d'être redéfinies. La troisième guerre des navigateurs se déroule autour de "l'entrée" plutôt que de "l'affichage". La victoire n'est plus déterminée par qui capte l'attention de l'utilisateur, mais par qui gagne la confiance de l'agent et accède.
Une brève histoire du développement des navigateurs
Au début des années 1990, avant que l'internet ne devienne une partie de la vie quotidienne, Netscape Navigator est arrivé sur le marché, tel un voilier qui a ouvert la porte au monde numérique pour des millions d'utilisateurs. Bien qu'il ne soit pas le premier navigateur, il a été le premier à atteindre véritablement les masses et à façonner l'expérience internet. Pour la première fois, les gens pouvaient naviguer sur le web avec une telle facilité grâce à une interface graphique, comme si le monde entier était soudainement devenu accessible.
Cependant, la gloire est souvent de courte durée. Microsoft a rapidement reconnu l'importance des navigateurs et a décidé d'incorporer de force Internet Explorer dans le système d'exploitation Windows, en faisant le navigateur par défaut. Cette stratégie, un véritable "tueur de plateforme", a directement sapé la domination de Netscape sur le marché. De nombreux utilisateurs n'ont pas activement choisi IE ; ils l'ont simplement accepté comme le navigateur par défaut. Tirant parti des capacités de distribution de Windows, IE est rapidement devenu le leader du secteur, tandis que Netscape est tombé en déclin.

Au milieu de l'adversité, les ingénieurs de Netscape ont choisi un chemin radical et idéaliste : ils ont ouvert le code source du navigateur et ont fait appel à la communauté open-source. Cette décision a été comme une "abdication macédonienne" dans le monde de la technologie, signalant la fin d'une ancienne ère et la montée de nouvelles forces. Ce code est ensuite devenu la base du projet de navigateur Mozilla, d'abord nommé Phoenix (symbolisant la renaissance), mais après plusieurs disputes de marque, il a finalement été renommé Firefox.
Firefox n'était pas une simple copie de Netscape. Il a réalisé des percées en matière d'expérience utilisateur, d'écosystèmes de plugins et de sécurité. Sa naissance a marqué la victoire de l'esprit open-source et a injecté une nouvelle vitalité dans l'ensemble de l'industrie. Certains ont décrit Firefox comme le "successeur spirituel" de Netscape, semblable à la manière dont l'Empire ottoman a hérité de la gloire déclinante de Byzance. Bien que exagérée, la comparaison est significative.
Pourtant, avant la sortie officielle de Firefox, Microsoft avait déjà lancé six versions d'Internet Explorer. En tirant parti de son timing précoce et de sa stratégie d'intégration au système, Firefox a été placé dans une position de rattrapage dès le départ, garantissant que cette course n'a jamais été une compétition équitable partant de la même ligne.
En même temps, un autre acteur précoce est entré discrètement sur la scène. En 1994, le navigateur Opera est né en Norvège, initialement juste un projet expérimental. Mais à partir de la version 7.0 en 2003, il a introduit son moteur Presto auto-développé, pionnier du support CSS, des mises en page adaptatives, du contrôle vocal et de l'encodage Unicode. Bien que sa base d'utilisateurs soit limitée, il a constamment mené l'industrie sur le plan technologique, devenant le "préféré des geeks".
Cette même année, Apple a lancé le navigateur Safari — un tournant significatif. À l'époque, Microsoft avait investi 150 millions de dollars dans une Apple en difficulté pour maintenir une semblance de concurrence et éviter un examen antitrust. Bien que le moteur de recherche par défaut de Safari ait été Google dès le début, cet enchevêtrement avec Microsoft symbolisait les relations complexes et subtiles entre les géants de l'internet : coopération et compétition, toujours entrelacées.
En 2007, IE7 a été lancé en même temps que Windows Vista, mais la réponse du marché a été tiède. Firefox, en revanche, a progressivement augmenté sa part de marché pour atteindre environ 20 %, grâce à des cycles de mise à jour plus rapides, un mécanisme d'extension plus convivial et un attrait naturel pour les développeurs. La domination d'IE a commencé à se relâcher, et les vents étaient en train de changer.
Google, cependant, a adopté une approche différente. Bien qu'elle ait prévu son propre navigateur depuis 2001, il a fallu six ans pour convaincre le PDG Eric Schmidt d'approuver le projet. Chrome a fait ses débuts en 2008, construit sur le projet open-source Chromium et le moteur WebKit utilisé par Safari. Il a été moqué comme un navigateur "gonflé", mais grâce à l'expertise approfondie de Google en matière de publicité et de création de marque, il a rapidement grimpé.
L'arme clé de Chrome n'était pas ses fonctionnalités, mais son cycle de mises à jour fréquentes (toutes les six semaines) et son expérience unifiée multiplateforme. En novembre 2011, Chrome a dépassé Firefox pour la première fois, atteignant une part de marché de 27 % ; six mois plus tard, il a dépassé IE, complétant sa transformation de challenger en leader dominant.
Pendant ce temps, l'internet mobile en Chine était en train de former son propre écosystème. Le navigateur UC d'Alibaba a connu une forte popularité au début des années 2010, notamment sur des marchés émergents comme l'Inde, l'Indonésie et la Chine. Grâce à son design léger et à ses fonctionnalités de compression de données qui économisaient de la bande passante, il a séduit les utilisateurs sur des appareils bas de gamme. En 2015, sa part de marché des navigateurs mobiles à l'échelle mondiale a dépassé 17 %, et en Inde, elle a atteint jusqu'à 46 %. Mais cette victoire n'a pas duré longtemps. Alors que le gouvernement indien renforçait les contrôles de sécurité sur les applications chinoises, le navigateur UC a été contraint de quitter des marchés clés, perdant progressivement sa gloire d'antan.
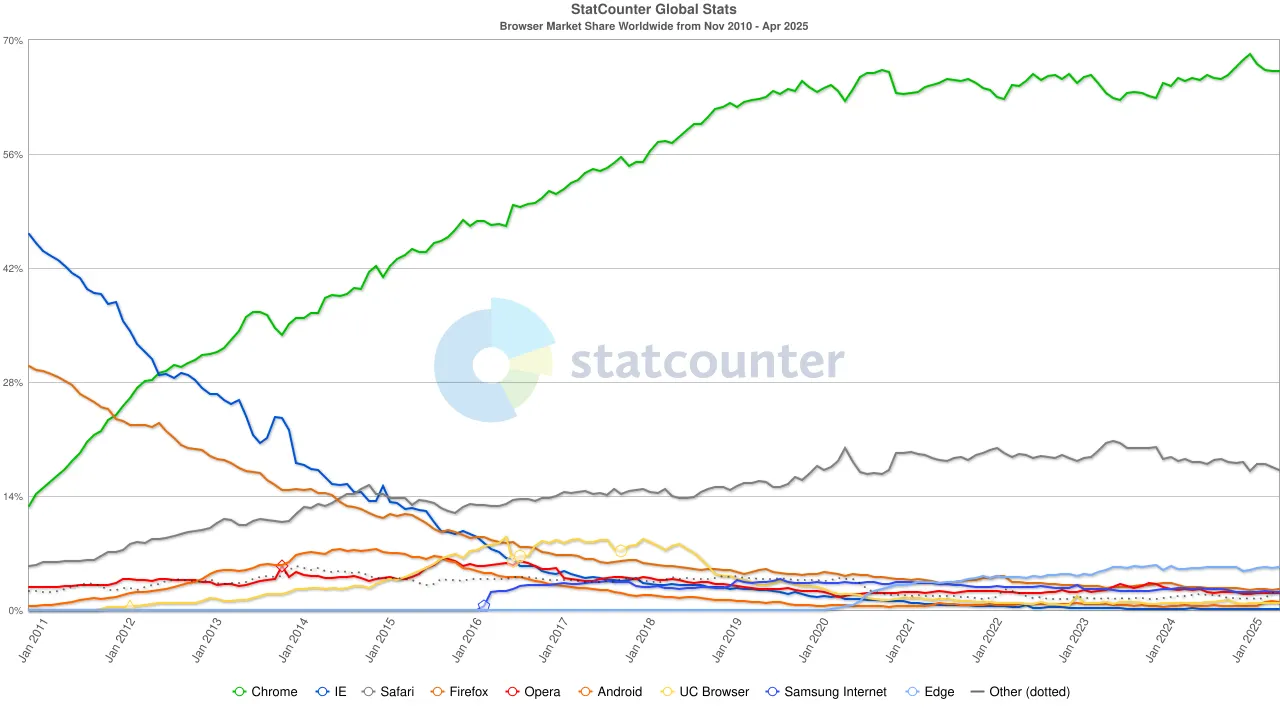
Dans les années 2020, la domination de Chrome était fermement établie, avec sa part de marché mondiale se stabilisant autour de 65 %. Notamment, bien que le moteur de recherche de Google et le navigateur Chrome appartiennent tous deux à Alphabet, d'un point de vue du marché, ils représentent deux hégémonies indépendantes — le premier contrôlant environ 90 % du trafic de recherche mondial, et le second servant de "première fenêtre" par laquelle la plupart des utilisateurs accèdent à Internet.
Pour maintenir cette structure de double monopole, Google n'a pas lésiné sur les moyens. En 2022, Alphabet a payé à Apple environ 20 milliards de dollars juste pour garder Google comme moteur de recherche par défaut dans Safari. Les analystes ont souligné que cette dépense représentait environ 36 % des revenus publicitaires de recherche que Google a gagnés grâce au trafic de Safari. En d'autres termes, Google payait effectivement une "taxe de protection" pour défendre son fossé.
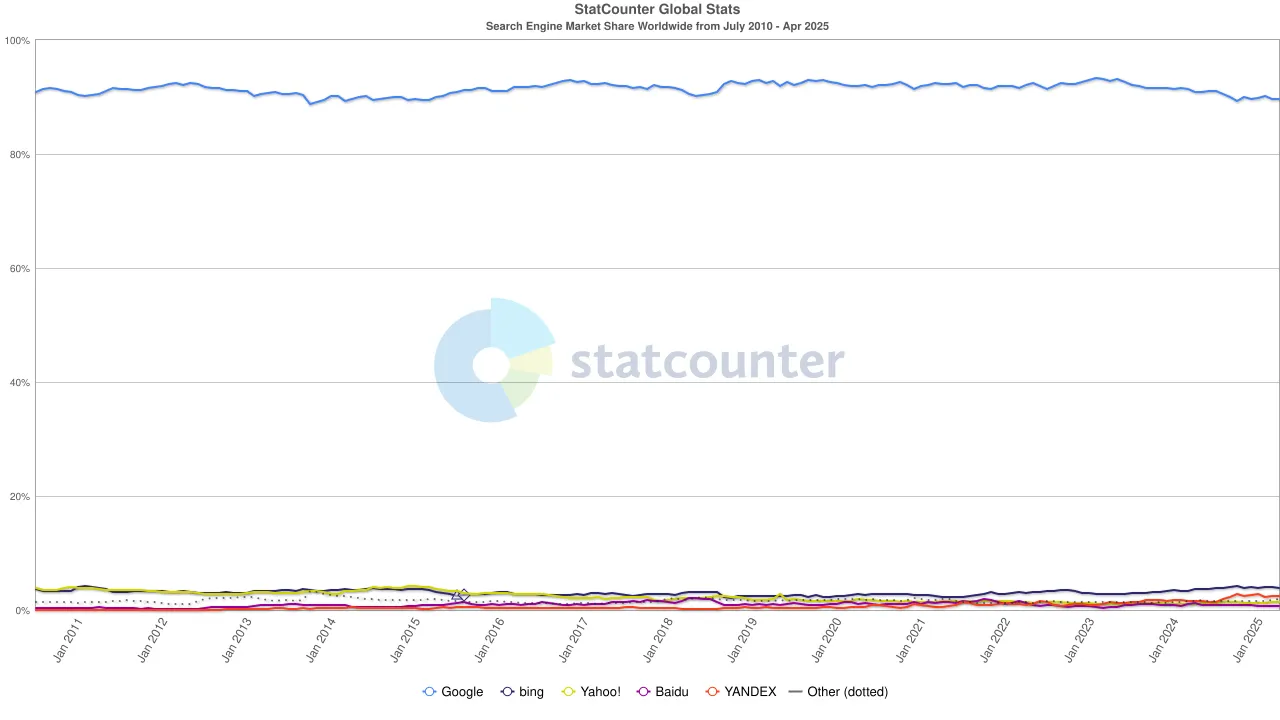
Mais la marée a de nouveau changé. Avec l'essor des grands modèles de langage (LLMs), la recherche traditionnelle a commencé à sentir l'impact. En 2024, la part de marché de Google dans la recherche est tombée de 93 % à 89 %. Bien qu'il domine encore, des fissures commençaient à apparaître. Encore plus perturbants étaient les rumeurs selon lesquelles Apple pourrait lancer son propre moteur de recherche alimenté par l'IA. Si la recherche par défaut de Safari devait passer à l'écosystème propre d'Apple, cela ne ferait pas seulement évoluer le paysage concurrentiel, mais pourrait aussi ébranler les fondements mêmes des bénéfices d'Alphabet. Le marché a réagi rapidement : le prix de l'action d'Alphabet est tombé de 170 $ à 140 $, reflétant non seulement la panique des investisseurs mais aussi une profonde inquiétude quant à la direction future de l'ère de la recherche.
De Navigator à Chrome, des idéaux open-source à la commercialisation axée sur la publicité, des navigateurs légers aux assistants de recherche alimentés par l'IA, la bataille des navigateurs a toujours été une guerre sur la technologie, les plateformes, le contenu et le contrôle. Le champ de bataille continue de changer, mais l'essence n'a jamais changé : quiconque contrôle la Gate définit l'avenir.
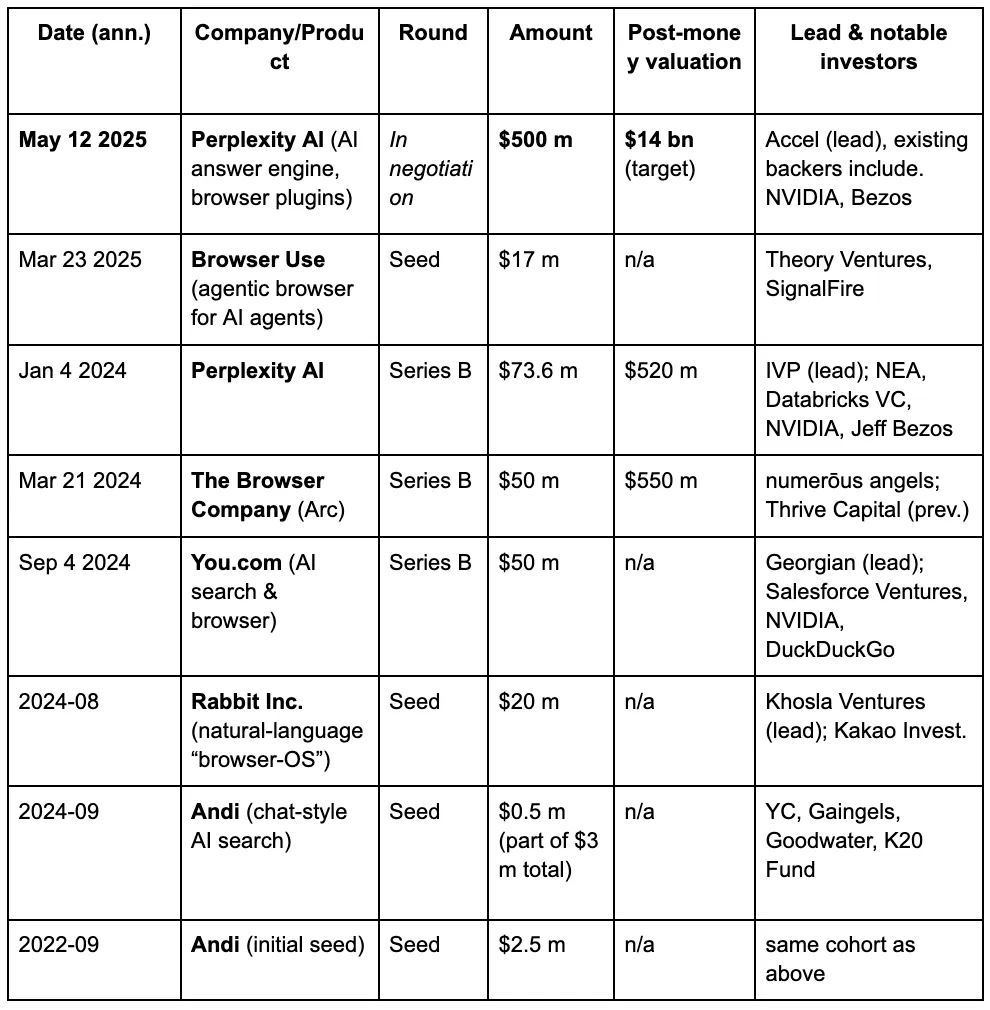
Aux yeux des capital-risqueurs, une troisième guerre des navigateurs est en train de se dérouler, alimentée par les nouvelles exigences que les gens placent sur les moteurs de recherche à l'ère des LLM et de l'IA. Voici les détails de financement de certains projets bien connus dans le domaine des navigateurs IA.
L'architecture obsolète des navigateurs modernes
En ce qui concerne l'architecture des navigateurs, la structure traditionnelle classique est illustrée dans le diagramme ci-dessous :
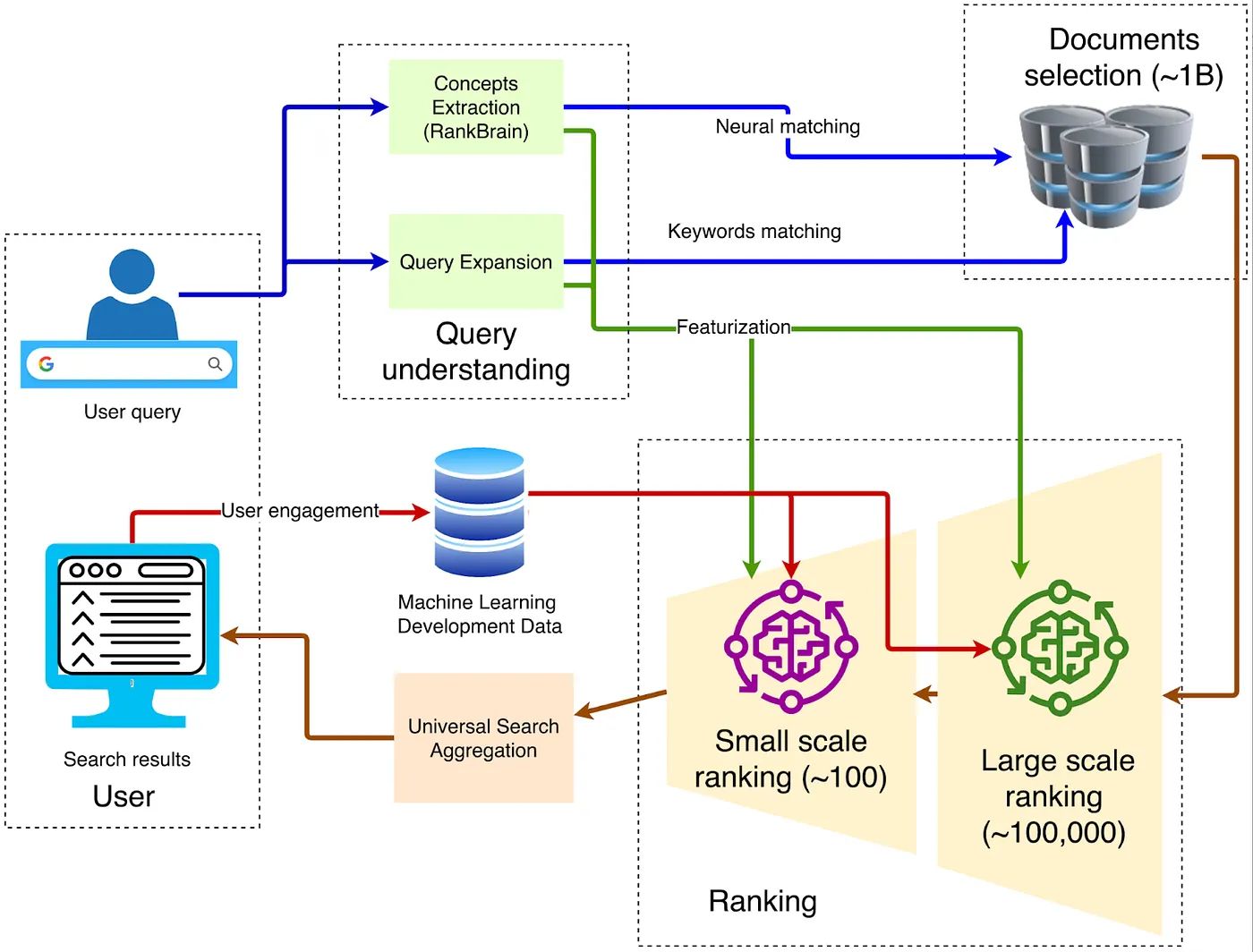
1. Client — Entrée Front-End
La requête est envoyée via HTTPS au Google Front End le plus proche, où le déchiffrement TLS, l'échantillonnage QoS et le routage géographique sont effectués. Si un trafic anormal est détecté (comme des attaques DDoS ou du scraping automatisé), des limitations de taux ou des défis peuvent être appliqués à ce niveau.
2. Compréhension de la requête
Le front end doit comprendre le sens des mots tapés par l'utilisateur. Cela implique trois étapes :
Correction orthographique neuronale, comme transformer "recpie" en "recipe".
Expansion de synonymes, par exemple en élargissant "comment réparer un vélo" pour inclure "réparer une bicyclette".
L'analyse d'intention, qui détermine si la requête est informative, de navigation ou transactionnelle, puis attribue la demande verticale appropriée.
3. Récupération de Candidats
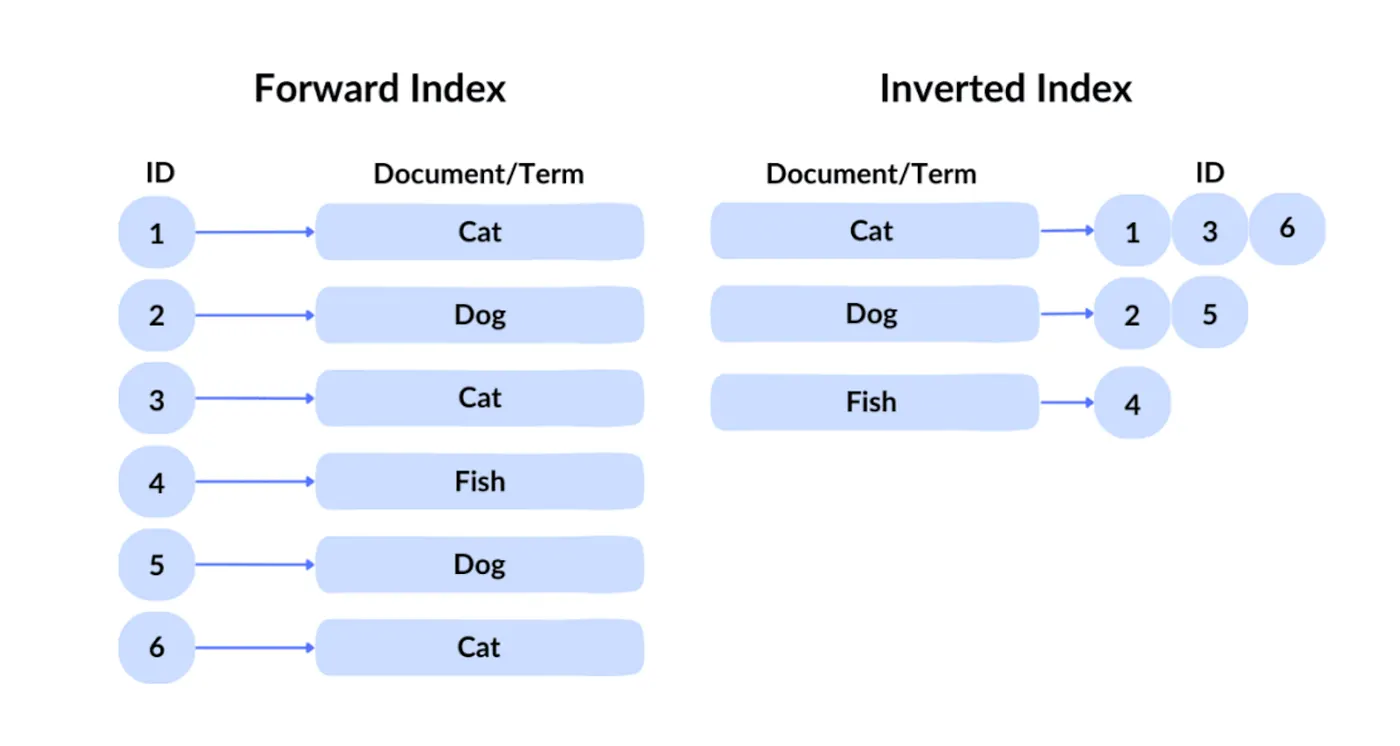
La technologie de requête de Google est connue sous le nom d'index inversé. Dans un index direct, vous récupérez un fichier en fonction de son ID. Mais comme les utilisateurs ne peuvent pas connaître les identifiants du contenu souhaité parmi des centaines de milliards de fichiers, Google utilise l'index inversé traditionnel, qui interroge par contenu pour identifier quels fichiers contiennent les mots-clés correspondants.
Ensuite, Google applique l'indexation vectorielle pour gérer la recherche sémantique, c'est-à-dire trouver du contenu similaire en signification à la requête. Il convertit le texte, les images et d'autres contenus en vecteurs de haute dimension (embeddings), puis recherche en fonction de la similarité entre ces vecteurs. Par exemple, si un utilisateur recherche "comment faire de la pâte à pizza", le moteur de recherche peut renvoyer des résultats liés à "guide de préparation de la pâte à pizza", car les deux sont sémantiquement similaires.
Grâce à l'indexation inversée et à l'indexation vectorielle, environ des centaines de milliers de pages web sont filtrées lors de la phase de sélection initiale.
4. Classement Multi-Étape
Le système utilise généralement des milliers de caractéristiques légères telles que BM25, TF-IDF et des scores de qualité de page pour filtrer des centaines de milliers de pages candidates jusqu'à environ 1 000, formant un ensemble initial de candidats. Ces systèmes sont collectivement appelés moteurs de recommandation. Ils s'appuient sur d'énormes caractéristiques générées par diverses entités, y compris le comportement des utilisateurs, les attributs des pages, l'intention de recherche et les signaux contextuels. Par exemple, Google combine l'historique des utilisateurs, les retours d'autres utilisateurs, la sémantique des pages et le sens des requêtes, tout en tenant compte d'éléments contextuels tels que le temps (heure de la journée, jour de la semaine) et des événements externes comme les nouvelles de dernière minute.
5. Apprentissage profond pour le classement primaire
Au stade de récupération initiale, Google utilise des technologies telles que RankBrain et Neural Matching pour comprendre la sémantique des requêtes et filtrer les résultats les plus pertinents parmi d'énormes collections de documents.
RankBrain, introduit par Google en 2015, est un système d'apprentissage automatique conçu pour mieux comprendre la signification des requêtes des utilisateurs, en particulier les requêtes jamais vues auparavant. Il transforme les requêtes et les documents en représentations vectorielles et calcule leur similarité pour trouver les résultats les plus pertinents. Par exemple, pour la requête "comment faire de la pâte à pizza", même si aucun document ne contient une correspondance exacte de mot-clé, RankBrain peut identifier du contenu lié aux "bases de la pizza" ou à "la préparation de la pâte".
Le Matching Neuronal, lancé en 2018, a été conçu pour mieux capturer la relation sémantique entre les requêtes et les documents. En utilisant des modèles de réseaux neuronaux, il identifie des relations floues entre les mots pour mieux faire correspondre les requêtes avec le contenu web. Par exemple, pour la requête « pourquoi le ventilateur de mon ordinateur portable est-il si bruyant », le Matching Neuronal peut comprendre que l'utilisateur pourrait rechercher des informations de dépannage concernant la surchauffe, l'accumulation de poussière ou une utilisation élevée du CPU, même si ces termes n'apparaissent pas explicitement dans la requête.
6. Deep Re-Ranking : L'application de BERT
Après le filtrage initial des documents pertinents, Google applique BERT (Représentations d'encodeurs bidirectionnels à partir de Transformers) pour affiner le classement et garantir que les résultats les plus pertinents apparaissent en haut. BERT est un modèle de langage pré-entraîné basé sur Transformers qui peut comprendre les relations contextuelles des mots au sein des phrases.
Dans la recherche, BERT est utilisé pour reclasser les documents récupérés dans les étapes précédentes. Il encode conjointement les requêtes et les documents, calcule leurs scores de pertinence, puis réorganise les documents. Par exemple, pour la requête « se garer sur une colline sans bordure », BERT peut correctement interpréter la signification de « sans bordure » et renvoyer des résultats conseillant aux conducteurs de tourner leurs roues vers le bord de la route, plutôt que de mal interpréter cela comme une situation avec une bordure.
Pour les ingénieurs SEO, cela signifie qu'ils doivent étudier attentivement les algorithmes de classement de Google et de recommandation par apprentissage automatique afin d'optimiser le contenu web de manière ciblée, gagnant ainsi en visibilité dans les classements de recherche.
Pourquoi l'IA va transformer les navigateurs
Tout d'abord, nous devons clarifier : pourquoi le navigateur sous forme de formulaire doit-il encore exister ? Y a-t-il un troisième paradigme au-delà des agents IA et des navigateurs ?
Nous croyons que l'existence implique l'irremplaçabilité. Pourquoi l'intelligence artificielle peut-elle utiliser des navigateurs mais ne peut-elle pas les remplacer complètement ? Parce que le navigateur est une plateforme universelle. Ce n'est pas seulement un point d'entrée pour lire des données, mais aussi un point d'entrée général pour saisir des données. Le monde ne peut pas seulement consommer des informations - il doit aussi produire des données et interagir avec des sites web. Par conséquent, les navigateurs qui intègrent des informations utilisateur personnalisées continueront d'exister largement.
Voici le point clé : en tant que passerelle universelle, le navigateur n'est pas seulement destiné à lire des données ; les utilisateurs ont souvent besoin d'interagir avec les données. Le navigateur lui-même est un excellent dépôt pour stocker les empreintes digitales des utilisateurs. Des comportements utilisateurs plus complexes et des actions automatisées doivent être effectués via le navigateur. Le navigateur peut stocker toutes les empreintes comportementales des utilisateurs, les identifiants et d'autres informations privées, permettant une invocation sans confiance lors de l'automatisation. L'interaction avec les données peut évoluer selon ce modèle :
Utilisateur → appelle l'agent IA → Navigateur.
En d'autres termes, la seule partie qui pourrait être remplacée réside dans la tendance naturelle du monde—vers une plus grande intelligence, personnalisation et automatisation. Il est certain que cette partie peut être gérée par des agents IA. Mais les agents IA eux-mêmes ne sont pas bien adaptés pour transporter du contenu utilisateur personnalisé, car ils font face à de multiples défis concernant la sécurité des données et l'utilisabilité. Spécifiquement:
Le navigateur est le dépôt de contenu personnalisé :
La plupart des grands modèles sont hébergés dans le cloud, avec des contextes de session dépendant du stockage serveur, ce qui rend difficile l'accès direct aux mots de passe locaux, aux portefeuilles, aux cookies et à d'autres données sensibles.
L'envoi de toutes les données de navigation et de paiement à des modèles tiers nécessite une nouvelle autorisation de l'utilisateur ; le DMA de l'UE et les lois sur la vie privée au niveau des États-Unis exigent tous deux la minimisation des données à travers les frontières.
Le remplissage automatique des codes d'authentification à deux facteurs, l'invocation des caméras ou l'utilisation des GPU pour l'inférence WebGPU doivent tous être effectués dans le bac à sable du navigateur.
Le contexte des données dépend fortement du navigateur. Les onglets, les cookies, IndexedDB, le cache du Service Worker, les informations d'identification de clé d'accès et les données d'extension sont tous stockés dans le navigateur.
Changements Profonds dans les Formes d'Interaction
Pour revenir au sujet du début, notre comportement lors de l'utilisation des navigateurs peut généralement être divisé en trois catégories : lire des données, saisir des données et interagir avec des données. Les grands modèles de langage (LLM) ont déjà profondément changé l'efficacité et les méthodes par lesquelles nous lisons des données. L'ancienne pratique des utilisateurs recherchant des pages web par mots-clés semble maintenant obsolète et inefficace.
Lorsqu'il s'agit de l'évolution du comportement de recherche des utilisateurs—que l'objectif soit d'obtenir des réponses résumées ou de cliquer sur des pages web—de nombreuses études ont déjà analysé ce changement.
En termes de modèles de comportement des utilisateurs, une étude de 2024 a montré qu'aux États-Unis, sur 1 000 requêtes Google, seulement 374 se sont terminées par un clic sur une page web ouverte. En d'autres termes, près de 63 % des comportements étaient des comportements « zéro-clic ». Les utilisateurs se sont habitués à obtenir des informations telles que la météo, les taux de change et les cartes de connaissance directement à partir de la page des résultats de recherche.
Ce qui pourrait vraiment déclencher une transformation massive des navigateurs, c'est cependant la couche d'interaction des données. Par le passé, les gens interagissaient avec les navigateurs principalement en entrant des mots-clés, le niveau maximal de compréhension que le navigateur lui-même pouvait gérer. Maintenant, les utilisateurs préfèrent de plus en plus utiliser un langage naturel complet pour décrire des tâches complexes, telles que :
"Trouvez-moi des vols directs de New York à Los Angeles pendant une certaine période."
“Trouvez-moi un vol de New York à Shanghai puis à Los Angeles.”
Même pour les humains, de telles tâches nécessitent beaucoup de temps pour visiter plusieurs sites Web, rassembler des informations et comparer des résultats. Mais ces tâches agentiques sont progressivement prises en charge par des agents IA.
Cela s'aligne également avec la trajectoire de l'histoire : l'automatisation et l'intelligence. Les gens souhaitent libérer leurs mains, et les agents IA seront inévitablement profondément intégrés dans les navigateurs. Les navigateurs futurs doivent être conçus en tenant compte de l'automatisation complète, en particulier en considérant :
Comment équilibrer l'expérience de lecture pour les humains avec l'interprétabilité machine pour les agents IA.
Comment s'assurer qu'une seule page web serve à la fois l'utilisateur final et le modèle d'agent.
Ce n'est qu'en répondant à ces deux exigences de conception que les navigateurs peuvent réellement devenir des supports stables pour que les agents IA exécutent des tâches.
Ensuite, nous nous concentrerons sur cinq projets importants : Browser Use, Arc (The Browser Company), Perplexity, Brave et Donut. Ces projets représentent les futures directions de l'évolution des navigateurs AI, ainsi que leur potentiel d'intégration native dans des contextes Web3 et crypto.
Du point de vue de la psychologie des utilisateurs, une enquête de 2023 a montré que 44 % des répondants considéraient que les résultats organiques réguliers étaient plus fiables que les extraits en vedette. Des recherches académiques ont également révélé que dans les cas de controverse ou d'absence d'une vérité autoritaire unique, les utilisateurs préfèrent les pages de résultats contenant des liens provenant de plusieurs sources.
En d'autres termes, bien qu'une partie des utilisateurs ne fasse pas entièrement confiance aux résumés générés par l'IA, un pourcentage significatif des comportements a déjà évolué vers le "zéro-clic". Par conséquent, les navigateurs IA doivent encore explorer le bon paradigme d'interaction—en particulier dans le domaine de la lecture des données. Étant donné que le problème des hallucinations dans les grands modèles n'est pas encore complètement résolu, de nombreux utilisateurs ont encore du mal à faire confiance aux résumés de contenu générés automatiquement. À cet égard, l'intégration de grands modèles dans les navigateurs ne nécessite pas nécessairement une transformation perturbatrice. Au lieu de cela, elle nécessite simplement des améliorations progressives en précision et en contrôlabilité—un processus qui est déjà en cours.
Utilisation du navigateur
C'est précisément la logique fondamentale derrière le financement massif reçu par Perplexity et Browser Use. En particulier, Browser Use est devenu la deuxième opportunité d'innovation la plus prometteuse début 2025, avec à la fois une certitude et un fort potentiel de croissance.

L'utilisation du navigateur a construit une véritable couche sémantique, avec son objectif principal de créer une architecture de reconnaissance sémantique pour la prochaine génération de navigateurs.
Browser Use réinterprète la traditionnelle "DOM = un arbre de nœuds pour que les humains voient" en "Semantic DOM = un arbre d'instructions pour que les LLMs lisent." Cela permet aux agents de cliquer, remplir et télécharger précisément sans se fier aux "coordonnées de pixel." Au lieu d'utiliser la reconnaissance optique de caractères visuelle ou Selenium basé sur des coordonnées, cette approche prend la voie de "texte structuré → appels de fonction," rendant l'exécution plus rapide, économisant des tokens et réduisant les erreurs. TechCrunch l'a décrit comme "la couche de colle qui permet à l'IA de vraiment comprendre les pages web." En mars, Browser Use a clôturé un tour de financement de démarrage de 17 millions de dollars, pariant sur cette innovation fondamentale.
Voici comment cela fonctionne :
Après le rendu de l'HTML, cela forme un arbre DOM standard. Le navigateur en déduit ensuite un arbre d'accessibilité, qui fournit des étiquettes "rôles" et "états" plus riches pour les lecteurs d'écran.
Chaque élément interactif (bouton, champ de saisie, etc.) est abstrait dans un extrait JSON avec des métadonnées telles que le rôle, la visibilité, les coordonnées et les actions exécutables.
La page entière est traduite en une liste aplatie de nœuds sémantiques, que le LLM peut lire dans une seule invite système.
Le LLM fournit des instructions de haut niveau (par exemple, cliquer(node_id="btn-Checkout")), qui sont ensuite rejouées dans le navigateur réel.
Le blog officiel décrit ce processus comme "transformer les interfaces de site Web en texte structuré que les LLM peuvent analyser."
De plus, si cette norme est un jour adoptée par le W3C, elle pourrait grandement résoudre le problème d'entrée dans les navigateurs. Ensuite, nous examinerons la lettre ouverte et les études de cas de The Browser Company pour expliquer davantage pourquoi leur approche est erronée.
Arc
La société Browser Company (la société mère d'Arc) a déclaré dans sa lettre ouverte que le navigateur Arc entrera en mode de maintenance régulier, tandis que l'équipe concentrera ses efforts sur le développement de DIA, un navigateur entièrement orienté vers l'IA. Dans la lettre, ils ont également admis que le chemin d'implémentation spécifique pour DIA n'a pas encore été déterminé. En même temps, l'équipe a esquissé plusieurs prévisions sur l'avenir du marché des navigateurs.
Sur la base de ces prévisions, nous croyons également que si le paysage actuel des navigateurs doit vraiment être perturbé, la clé réside dans le changement du côté de sortie de l'interaction.
Voici trois des prévisions concernant le futur du marché des navigateurs partagées par l'équipe Arc.
https://browsercompany.substack.com/p/letter-to-arc-members-2025
Tout d'abord, l'équipe d'Arc estime que les pages web ne seront plus l'interface principale d'interaction. Certes, c'est une affirmation audacieuse et difficile, et c'est également la principale raison pour laquelle nous restons sceptiques quant aux réflexions de leur fondateur. À notre avis, cette perspective sous-estime considérablement le rôle du navigateur, et elle met en évidence la question clé que l'équipe a négligée en explorant le chemin du navigateur AI.
Les grands modèles excellent dans la capture de l'intention—par exemple, comprendre des instructions comme « aidez-moi à réserver un vol ». Cependant, ils restent insuffisants en ce qui concerne la densité d'information. Lorsqu'un utilisateur a besoin de quelque chose comme un tableau de bord, un carnet de style Bloomberg Terminal, ou un canvas visuel comme Figma, rien ne peut surpasser une page web finement ajustée avec une précision au niveau des pixels. L'ergonomie de chaque produit—graphes, fonctionnalité de glisser-déposer, touches de raccourci—n'est pas une décoration superficielle, mais des atouts essentiels qui compressent la cognition. Ces capacités ne peuvent pas être reproduites par de simples interactions conversationnelles. Prenons Gate.com comme exemple : si un utilisateur souhaite exécuter une action d'investissement, s'appuyer uniquement sur une conversation AI est loin d'être suffisant, car les utilisateurs dépendent fortement d'une saisie structurée, de l'exactitude et d'une présentation claire de l'information.
La feuille de route de l'équipe Arc contient un défaut fondamental : elle ne parvient pas à bien distinguer que « l'interaction » est composée de deux dimensions : l'entrée et la sortie. Du côté de l'entrée, leur point de vue a une certaine validité dans certains scénarios, car l'IA peut en effet améliorer l'efficacité des interactions de type commande. Mais du côté de la sortie, leur hypothèse est clairement déséquilibrée, négligeant le rôle central du navigateur dans la présentation de l'information et les expériences personnalisées. Par exemple, Reddit a sa propre mise en page et architecture d'information uniques, tandis qu'AAVE a une interface et une structure complètement différentes. En tant que plateforme qui stocke simultanément des données hautement privées et rend divers interfaces de produit, le navigateur a une substituabilité limitée du côté de l'entrée, tandis que sa complexité et sa nature non standardisée du côté de la sortie rendent encore plus difficile la disruption.
En revanche, les navigateurs AI actuels se concentrent principalement sur la couche de « résumé de sortie » : résumer des pages, extraire des informations, générer des conclusions. Cela ne suffit pas à poser un défi fondamental aux navigateurs grand public ou aux systèmes de recherche comme Google, cela grignote simplement la part de marché des résumés de recherche.
Par conséquent, la seule technologie qui pourrait vraiment ébranler la part de marché de 66 % de Chrome est destinée à ne pas être « le prochain Chrome. » Pour réaliser une véritable disruption, le modèle de rendu des navigateurs doit être fondamentalement restructuré pour s'adapter aux besoins d'interaction de l'ère de l'agent IA, notamment en termes de conception de l'architecture côté entrée. C'est pourquoi nous trouvons le chemin technique emprunté par Browser Use bien plus convaincant : il se concentre sur des changements structurels au niveau du mécanisme sous-jacent des navigateurs. Une fois qu'un système atteint une conception « atomique » ou « modulaire », la programmabilité et la composition qui en découlent débloquent un potentiel disruptif. C'est exactement la direction que suit Browser Use aujourd'hui.
En résumé, le fonctionnement des agents IA dépend encore fortement de l'existence de navigateurs. Les navigateurs ne sont pas seulement les principaux dépôts de données personnalisées complexes, mais également les interfaces de rendu universelles pour diverses applications, et continueront donc à servir de passerelle centrale pour l'interaction à l'avenir. À mesure que les agents IA s'intègrent profondément dans les navigateurs pour accomplir des tâches fixes, ils interagiront avec les données des utilisateurs et les applications spécifiques principalement par le biais de l'entrée. Pour cette raison, le modèle de rendu actuel des navigateurs doit être innové pour atteindre une compatibilité et une adaptabilité maximales avec les agents IA, permettant finalement de capturer les applications plus efficacement.
Perplexité
Perplexity est un moteur de recherche AI réputé pour son système de recommandations. Sa dernière valorisation a grimpé à 14 milliards de dollars, soit presque un quintuplement par rapport à 3 milliards de dollars en juin 2024. Il traite désormais plus de 400 millions de requêtes de recherche par mois. Rien qu'en septembre 2024, il a traité environ 250 millions de requêtes, marquant une augmentation de huit fois d'une année sur l'autre du volume de recherche des utilisateurs, avec plus de 30 millions d'utilisateurs actifs mensuels.
Sa caractéristique principale est la capacité de résumer des pages en temps réel, lui donnant un fort avantage dans l'accès à des informations à jour. Plus tôt cette année, Perplexity a commencé à construire son propre navigateur natif, Comet. L'entreprise décrit Comet comme un navigateur qui non seulement "affiche" des pages web mais qui "réfléchit" également à leur sujet. Officiellement, ils affirment qu'il intégrera le moteur de réponse de Perplexity profondément à l'intérieur du navigateur lui-même, suivant une approche "machine entière" rappelant la philosophie de Steve Jobs : intégrer profondément les tâches d'IA au niveau de base du navigateur, plutôt que de simplement construire des plugins de barre latérale.
Avec des réponses concises étayées par des citations, Comet vise à remplacer les « dix liens bleus » traditionnels et à concurrencer directement Chrome.
Mais Perplexity doit encore résoudre deux problèmes fondamentaux : les coûts de recherche élevés et les faibles marges bénéficiaires des utilisateurs marginaux. Bien que Perplexity soit actuellement en tête dans le domaine de la recherche AI, Google a annoncé lors de sa conférence I/O 2025 un renouvellement intelligent à grande échelle de ses produits phares. Pour les navigateurs, Google a lancé une nouvelle expérience d'onglet de navigateur appelée AI Model, qui intègre Overview, Deep Research et les futures capacités Agentic. L'ensemble de l'initiative est désigné sous le nom de "Project Mariner."
Google avance activement dans sa transformation IA, ce qui signifie que l'imitation superficielle de fonctionnalités—comme Overview, Deep Research ou Agentics—ne posera guère de menace réelle. Ce qui pourrait réellement établir un nouvel ordre au milieu du chaos, c'est de reconstruire l'architecture du navigateur depuis le début, d'intégrer profondément des modèles de langage de grande taille (LLMs) dans le noyau du navigateur, et de transformer fondamentalement les méthodes d'interaction.
Brave
Brave est l'un des premiers et des plus réussis navigateurs dans l'industrie de la crypto. Construit sur l'architecture Chromium, il est compatible avec les extensions du Google Store. Brave attire les utilisateurs avec un modèle basé sur la confidentialité et le gain de jetons grâce à la navigation. Son parcours de développement démontre un certain potentiel de croissance. Cependant, d'un point de vue produit, bien que la confidentialité soit effectivement importante, la demande reste concentrée au sein de groupes d'utilisateurs spécifiques. Pour le grand public, la sensibilisation à la confidentialité n'est pas encore devenue un facteur de décision dominant. Par conséquent, tenter de s'appuyer uniquement sur cette caractéristique pour perturber les géants existants est peu susceptible de réussir.
À l'heure actuelle, Brave a atteint 82,7 millions d'utilisateurs actifs mensuels (UAM) et 35,6 millions d'utilisateurs actifs quotidiens (UAQ), détenant une part de marché d'environ 1 % à 1,5 %. Sa base d'utilisateurs a montré une croissance constante : de 6 millions en juillet 2019, à 25 millions en janvier 2021, à 57 millions en janvier 2023, et d'ici février 2025, elle a dépassé 82 millions. Son taux de croissance annuel composé reste dans la plage à deux chiffres.
Brave traite environ 1,34 milliard de requêtes de recherche par mois, ce qui représente environ 0,3 % du volume de Google.
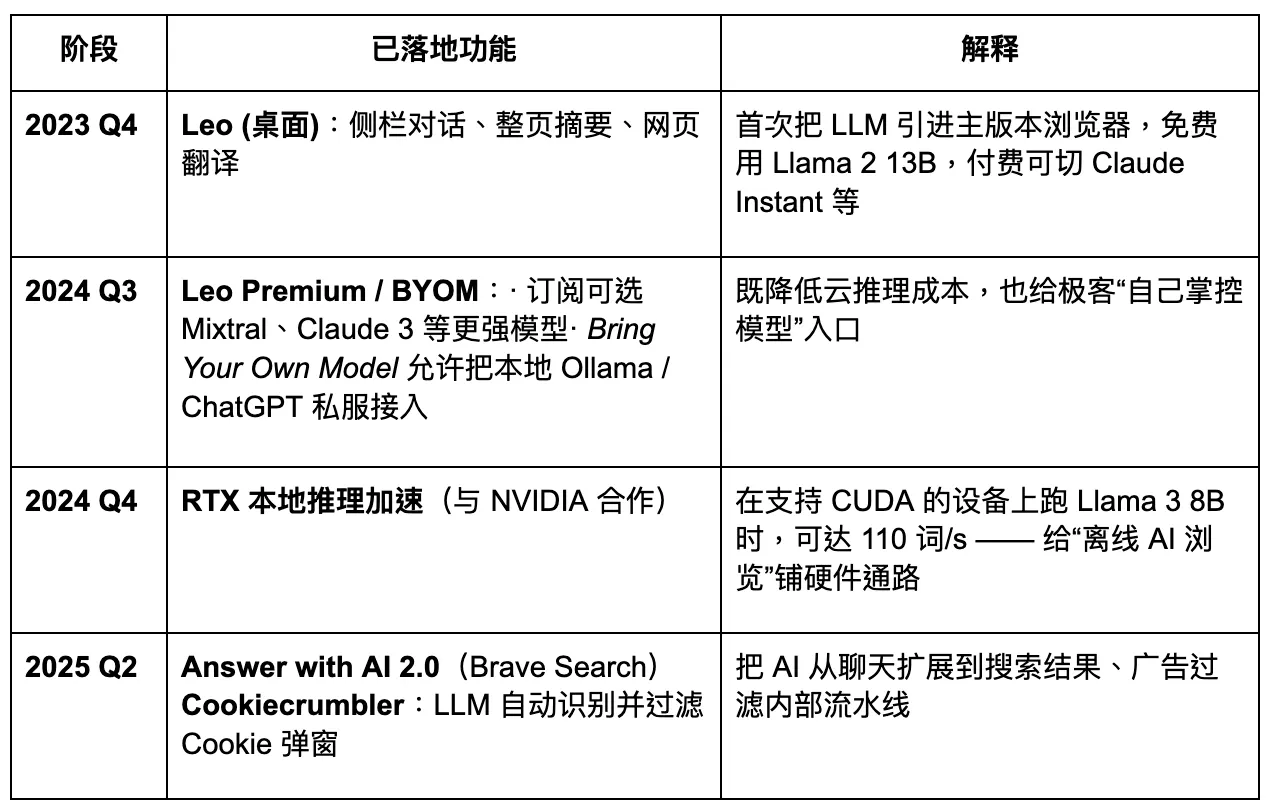
Brave prévoit de se transformer en un navigateur AI axé sur la confidentialité. Cependant, son accès limité aux données des utilisateurs réduit le niveau de personnalisation possible pour de grands modèles, ce qui, à son tour, freine l'itération rapide et précise des produits. À l'ère du navigateur Agentic à venir, Brave pourrait maintenir une part stable parmi des groupes d'utilisateurs spécifiques axés sur la confidentialité, mais il sera difficile pour lui de devenir un acteur dominant. Son assistant AI, Leo, fonctionne davantage comme une amélioration de plugin—offrant certaines capacités de résumé de contenu, mais manquant d'une stratégie claire pour un passage complet vers des agents AI. L'innovation dans l'interaction reste insuffisante.
Donut
Récemment, l'industrie de la cryptographie a également progressé dans le domaine des navigateurs agentiques. Le projet en phase de démarrage Donut a levé 7 millions de dollars lors d'un tour de pré-amorçage, dirigé par Hongshan (Sequoia China), HackVC et Bitkraft Ventures. Le projet est encore à un stade conceptuel précoce, avec pour vision d'atteindre "Découverte – Prise de décision – et Exécution crypto-native" en tant que capacité intégrée.
La direction principale est de combiner des chemins d'exécution automatiques natifs de la crypto. Comme l'a prédit a16z, les agents pourraient remplacer les moteurs de recherche en tant que principale passerelle de trafic à l'avenir. Les entrepreneurs ne rivaliseront plus autour des algorithmes de classement de Google, mais lutteront plutôt pour le trafic et les conversions qui proviennent de l'exécution par agents. L'industrie a déjà nommé cette tendance « AEO » (Optimisation des Réponses / des Moteurs d'Agents), ou même plus loin, « ATF » (Accomplissement des Tâches Agentiques) - où l'objectif n'est plus d'optimiser les classements de recherche, mais de servir directement des modèles intelligents capables d'accomplir des tâches pour les utilisateurs, comme passer des commandes, réserver des billets ou écrire des lettres.
Pour les entrepreneurs
Tout d'abord, il faut reconnaître : le navigateur lui-même reste le plus grand "Gateway" non reconstruit dans le monde d'internet. Avec environ 2,1 milliards d'utilisateurs de bureau et plus de 4,3 milliards d'utilisateurs mobiles dans le monde, il sert de transporteur commun pour la saisie de données, le comportement interactif et le stockage d'empreintes digitales personnalisées. La raison de sa persistance n'est pas l'inertie, mais la nature duale inhérente au navigateur : il est à la fois le point d'entrée pour la lecture des données et le point de sortie pour les actions d'écriture.
Par conséquent, pour les entrepreneurs, le véritable potentiel disruptif ne réside pas dans l'optimisation de la couche "sortie de page". Même si l'on pouvait répliquer des fonctions de synthèse d'IA similaires à celles de Google dans un nouvel onglet, ce ne serait qu'une itération au niveau du plugin, et non un changement de paradigme fondamental. La véritable percée se situe du côté "entrée" : comment faire en sorte que les agents d'IA appellent activement votre produit pour accomplir des tâches spécifiques. Cela déterminera si un produit peut s'intégrer dans l'écosystème des agents, capter du trafic et partager la distribution de valeur.
À l'ère de la recherche, la compétition portait sur les clics ; à l'ère des agents, elle porte sur les appels.
Si vous êtes un entrepreneur, vous devriez réimaginer votre produit comme un composant API—quelque chose qu'un agent intelligent peut non seulement comprendre mais aussi invoquer. Cela vous oblige à considérer trois dimensions dès le début de la conception du produit :
1. Normalisation de la structure de l'interface : Votre produit est-il appelable ?
La capacité d'un agent à invoquer un produit dépend de la possibilité de standardiser et d'abstraire sa structure d'information en un schéma clair. Par exemple, des actions clés telles que l'inscription d'un utilisateur, la passation de commandes ou la soumission de commentaires peuvent-elles être décrites par une structure DOM sémantique ou un mappage JSON ? Le système fournit-il une machine à états afin que l'agent puisse reproduire de manière fiable les flux de travail des utilisateurs ? Les interactions des utilisateurs sur la page peuvent-elles être scriptées ? Le produit offre-t-il des webhooks ou des points de terminaison API stables ?
C'est précisément pourquoi Browser Use a réussi à lever des fonds : il a transformé le navigateur d'un simple rendu HTML en un arbre sémantique appelable par des LLM. Pour les entrepreneurs, adopter une philosophie de design similaire dans les produits web signifie se préparer à une adaptation structurée à l'ère des agents d'IA.
2. Identité et accès : Pouvez-vous aider les agents à "franchir la barrière de confiance" ?
Pour que les agents puissent effectuer des transactions ou appeler des fonctions de paiement et d'actifs, ils ont besoin d'un intermédiaire de confiance—pouvez-vous devenir cet intermédiaire ? Les navigateurs ont naturellement la capacité de lire le stockage local, d'accéder aux portefeuilles, de gérer les CAPTCHA et d'intégrer l'authentification à deux facteurs. Cela les rend plus adaptés que les modèles hébergés dans le cloud pour exécuter des tâches. C'est particulièrement vrai dans le Web3, où les interfaces d'interaction avec les actifs ne sont pas standardisées. Sans « identité » ou « capacité de signature », un agent ne peut pas avancer.
Pour les entrepreneurs en crypto, cela ouvre un espace blanc hautement imaginatif : le "MCP (Plateforme Multi-Capacité) du monde blockchain." Cela pourrait prendre la forme d'une couche de commande universelle (permettant aux agents d'appeler des Dapps), d'un ensemble d'interface de contrat standardisé, ou même d'un portefeuille local léger + hub d'identité.
3. Repenser les mécanismes de trafic : l'avenir n'est pas le SEO, mais l'AEO / l'ATF.
Dans le passé, il fallait gagner l'algorithme de Google ; maintenant, vous devez être intégré dans les chaînes de tâches des agents d'IA. Cela signifie que votre produit doit avoir une granularité de tâche claire : pas une "page", mais une série d'unités de capacité appelables. Cela signifie également commencer à optimiser pour l'Optimisation du Moteur d'Agent (AEO) ou s'adapter à l'Accomplissement de Tâches Agentiques (ATF). Par exemple, le processus d'inscription peut-il être simplifié en étapes structurées ? Les prix peuvent-ils être extraits via une API ? L'inventaire est-il accessible en temps réel ?
Vous devrez peut-être même vous adapter à différentes syntaxes d'appel dans les frameworks LLM, puisque OpenAI et Claude, par exemple, ont des préférences différentes pour les appels de fonction et l'utilisation des outils. Chrome est le terminal de l'ancien monde, pas la porte d'entrée vers le nouveau. Les projets de l'avenir ne reconstruiront pas les navigateurs, mais plutôt feront en sorte que les navigateurs servent des agents—construisant des ponts pour la nouvelle génération de « flux d'instructions ».
Ce que vous devez créer, c'est le "langage d'interface" à travers lequel les agents appellent votre monde.
Ce que vous devez gagner est une place dans la chaîne de confiance des systèmes intelligents.
Ce que vous devez construire est un "château API" dans le prochain paradigme de recherche.
Si le Web2 a capté l'attention des utilisateurs par son interface utilisateur, alors l'ère Web3 + AI Agent capturera l'intention d'exécution de l'agent par le biais de chaînes d'appels.
Avertissement
Ce contenu ne constitue pas une offre, une sollicitation ou une recommandation. Vous devriez toujours demander des conseils professionnels indépendants avant de prendre une décision d'investissement. Veuillez noter que Gate et/ou Gate Ventures peuvent restreindre ou interdire certains ou tous les services dans les régions restreintes. Veuillez lire l'accord utilisateur applicable pour plus de détails.
À propos de Gate Ventures
Gate Ventures est le bras de capital-risque de Gate, se concentrant sur les investissements dans les infrastructures décentralisées, les écosystèmes et les applications—des technologies qui redéfiniront le monde à l'ère du Web 3.0. Gate Ventures collabore avec des leaders mondiaux de l'industrie pour habiliter les équipes et les startups avec une pensée innovante et des capacités pour redéfinir la manière dont la société et la finance interagissent.
Site Web : https://www.gate.com/ventures
Partager
Contenu
TL;DR
Une brève histoire du développement des navigateurs
L'architecture obsolète des navigateurs modernes
Pourquoi l'IA va remodeler les navigateurs
Changements Profonds dans les Formes d'Interaction
Utilisation du navigateur
Arc
Perplexité
Brave
Donut
Pour les entrepreneurs
Avertissement
À propos de Gate Ventures

