Modèles de prédiction de prix des cryptomonnaies basés sur l'apprentissage automatique : de LSTM à Transformer
Le marché des cryptomonnaies est connu pour sa volatilité extrême, offrant d'importantes opportunités aux investisseurs, mais aussi des risques considérables. La prédiction précise des prix est cruciale pour des décisions d'investissement éclairées. Cependant, les méthodes traditionnelles d'analyse financière peinent souvent à faire face à la complexité et aux changements rapides du marché de la crypto. Ces dernières années, l'avancée de l'apprentissage automatique a fourni de puissants outils pour la prévision des séries temporelles financières, notamment dans la prédiction des prix des cryptomonnaies.
Les algorithmes d'apprentissage automatique peuvent apprendre à partir de grands volumes de données historiques sur les prix et d'autres informations pertinentes, identifiant des schémas difficiles à détecter pour les humains. Parmi les différents modèles d'apprentissage automatique, les réseaux neuronaux récurrents (RNN) et leurs variantes, comme les modèles Long Short-Term Memory (LSTM) et Transformer, ont attiré une large attention pour leur capacité exceptionnelle à manipuler des données séquentielles, montrant un potentiel croissant dans la prévision des prix des cryptomonnaies. Cet article offre une analyse approfondie des modèles basés sur l'apprentissage automatique pour la prédiction des prix des cryptomonnaies, en se concentrant sur la comparaison des applications LSTM et Transformer. Il explore également comment l'intégration de sources de données diverses peut améliorer les performances du modèle et examine l'impact des événements cygne noir sur la stabilité du modèle.
Application de l'apprentissage automatique dans la prédiction des prix des cryptomonnaies
L'idée fondamentale de l'apprentissage automatique est de permettre aux ordinateurs d'apprendre à partir de grands ensembles de données et de faire des prédictions basées sur les schémas appris. Ces algorithmes analysent les changements de prix historiques, les volumes de transactions et d'autres données connexes pour découvrir des tendances et des schémas cachés. Les approches courantes incluent l'analyse de régression, les arbres de décision et les réseaux neuronaux, tous largement utilisés dans la construction de modèles de prédiction des prix des cryptomonnaies.
La plupart des études ont fait confiance à des méthodes statistiques traditionnelles dans les premières étapes de la prévision des prix des cryptomonnaies. Par exemple, vers 2017, avant que l'apprentissage profond ne devienne répandu, de nombreuses études ont utilisé des modèles ARIMA pour prédire les tendances des prix des cryptomonnaies comme le Bitcoin. Une étude représentative menée par Dong, Li et Gong (2017) a utilisé le modèle ARIMA pour analyser la volatilité du Bitcoin, démontrant la stabilité et la fiabilité des modèles traditionnels dans la capture des tendances linéaires.
Avec les avancées technologiques, les méthodes d'apprentissage profond ont commencé à montrer des résultats révolutionnaires dans la prévision des séries temporelles financières d'ici 2020. En particulier, les réseaux de Long Short-Term Memory (LSTM) ont gagné en popularité en raison de leur capacité à capturer les dépendances à long terme dans les données de séries temporelles. A étudepar Patel et al. (2019) a prouvé les avantages des LSTM dans la prédiction des prix du Bitcoin, marquant une avancée significative à l'époque.
D'ici 2023, les modèles Transformer, avec leurs mécanismes d'auto-attention uniques capables de capturer les relations dans l'ensemble de la séquence de données en une seule fois, étaient de plus en plus appliqués à la prévision des séries chronologiques financières. Par exemple, Zhao et al. en 2023étudier"Attention ! Le transformateur avec Sentiment sur la prédiction des prix des cryptomonnaies" a intégré avec succès les modèles de transformateur avec les données de sentiment des médias sociaux, améliorant significativement l'exactitude des prédictions de tendance des prix des cryptomonnaies, marquant ainsi une étape importante dans le domaine.

Étapes dans la technologie de prédiction Crypto (Source: Gate Learn Creator John)
Parmi les nombreux modèles d'apprentissage automatique, les modèles d'apprentissage profond, en particulier les réseaux neuronaux récurrents (RNN) et leurs versions avancées, LSTM et Transformer, ont démontré des avantages significatifs dans le traitement des données de séries temporelles. Les RNN sont spécifiquement conçus pour traiter des données séquentielles en transmettant des informations des étapes antérieures aux étapes ultérieures, capturant ainsi efficacement les dépendances entre les points temporels. Cependant, les RNN traditionnels rencontrent des difficultés avec le problème du « gradient qui disparaît » lorsqu'ils traitent de longues séquences, ce qui fait que des informations anciennes mais importantes sont progressivement perdues. Pour remédier à cela, LSTM introduit des cellules de mémoire et des mécanismes de régulation en plus des RNN, permettant une rétention à long terme des informations clés et une meilleure modélisation des dépendances à long terme. Étant donné que les données financières, telles que les prix historiques des cryptomonnaies, présentent de fortes caractéristiques temporelles, les modèles LSTM sont particulièrement adaptés pour prédire de telles tendances.
D'autre part, les modèles de Transformer ont été initialement développés pour le traitement du langage. Leur mécanisme d'auto-attention permet au modèle de considérer les relations à travers l'ensemble de la séquence de données simultanément, plutôt que de les traiter étape par étape. Cette architecture confère aux Transformers un immense potentiel dans la prédiction des données financières avec des dépendances temporelles complexes.
Comparaison des modèles de prédiction
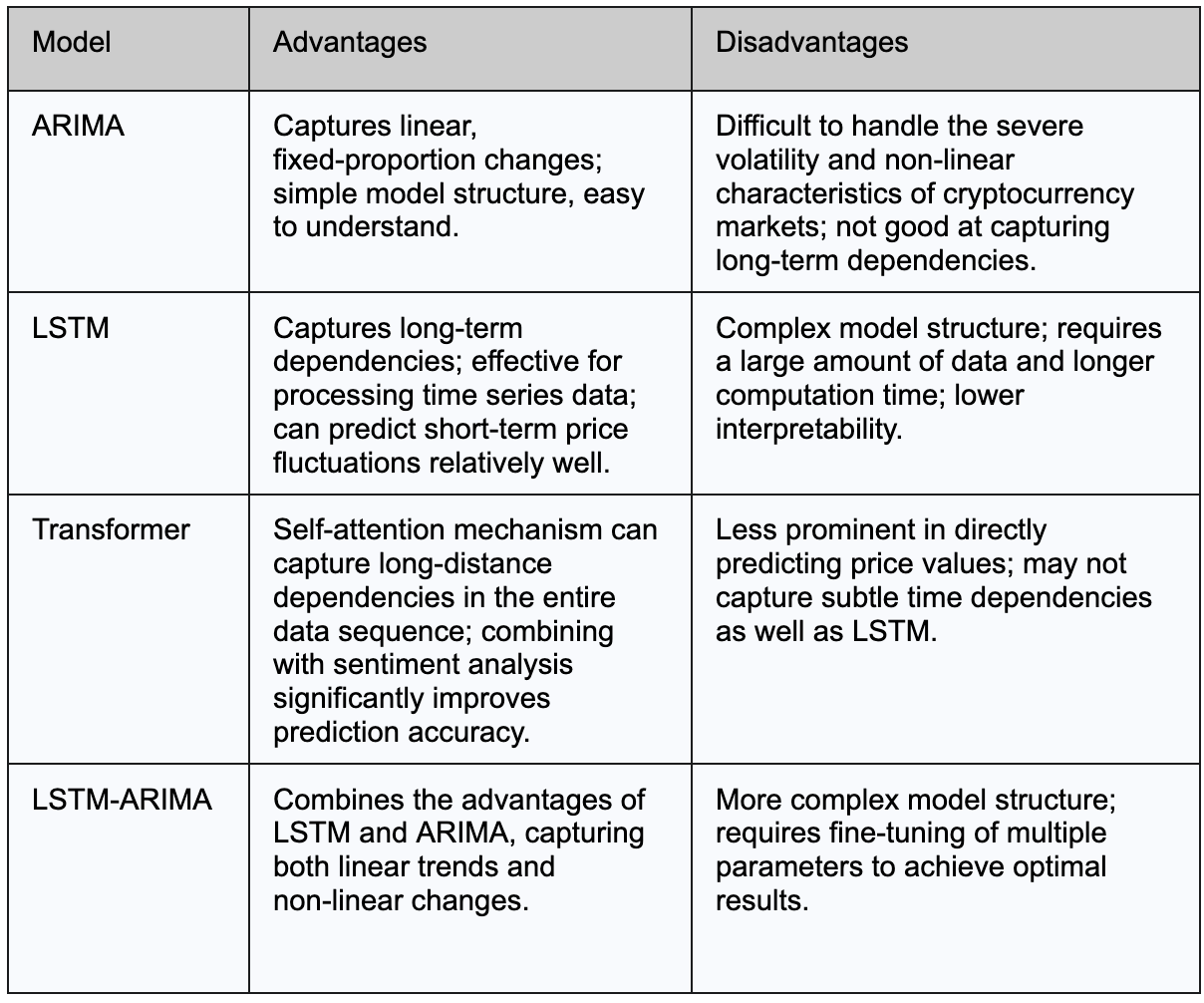
Les modèles traditionnels comme ARIMA sont souvent utilisés comme références aux côtés des modèles d'apprentissage profond dans la prédiction des prix des cryptomonnaies. ARIMA est conçu pour capturer les tendances linéaires et les changements proportionnels constants dans les données, ce qui fonctionne bien dans de nombreuses tâches de prévision. Cependant, en raison de la nature hautement volatile et complexe des prix des cryptomonnaies, les hypothèses linéaires d'ARIMA sont souvent insuffisantes.Des études ont montréque les modèles d'apprentissage profond fournissent généralement des prédictions plus précises dans les marchés non linéaires et hautement fluctuants.
Parmi les approches d'apprentissage profond, la recherche comparant les modèles LSTM et Transformer dans la prédiction des prix du Bitcoin a révélé que le LSTM se comporte mieux pour capturer les détails plus fins des changements de prix à court terme. Cet avantage est principalement dû au mécanisme de mémoire du LSTM, qui lui permet de modéliser les dépendances à court terme de manière plus efficace et stable. Alors que le LSTM peut surpasser en précision de prévision à court terme, les modèles Transformer restent très compétitifs. Lorsqu'ils sont améliorés avec des données contextuelles supplémentaires, telles que l'analyse de sentiment de Twitter, les Transformers peuvent offrir une compréhension plus large du marché, améliorant significativement les performances prédictives.
De plus, certaines études ont exploré des modèles hybrides qui combinent l'apprentissage profond avec des approches statistiques traditionnelles, telles que LSTM-ARIMA. Ces modèles hybrides visent à capturer à la fois les modèles linéaires et non linéaires dans les données, améliorant ainsi la précision des prédictions et la robustesse du modèle.
Le tableau ci-dessous résume les principaux avantages et inconvénients des modèles ARIMA, LSTM et Transformer dans la prédiction du prix du Bitcoin :
Améliorer la précision de la prédiction avec l'ingénierie des fonctionnalités
Lors de la prévision des prix des cryptomonnaies, nous ne nous fions pas uniquement aux données historiques des prix, nous incorporons également des informations supplémentaires précieuses pour aider les modèles à faire des prédictions plus précises. Ce processus s'appelle l'ingénierie des caractéristiques, qui consiste à organiser et à construire des "caractéristiques" de données qui améliorent les performances de prédiction.
Sources de données de fonctionnalités communes
Données sur chaîne
Données sur chaînefait référence à toutes les informations transactionnelles et d'activité enregistrées sur la blockchain, y compris le volume de transactions, le nombre d'adresses actives, difficulté de minage, et taux de hashageCes métriques reflètent directement la dynamique de l'offre et de la demande sur le marché et l'activité globale du réseau, ce qui les rend très précieuses pour la prévision des prix. Par exemple, une augmentation significative du volume des échanges peut indiquer un changement de sentiment sur le marché, tandis qu'une augmentation des adresses actives pourrait indiquer une adoption plus large, pouvant potentiellement faire monter les prix.
De telles données sont généralement accessibles via les API des explorateurs de blocs ou des fournisseurs de données spécialisés comme GlassnodeetMétriques de la monnaie. Vous pouvez utiliser la bibliothèque de demandes de Python pour appeler des API ou télécharger directement des fichiers CSV pour l'analyse.
Indicateurs de sentiment des médias sociaux
Des plateformes comme Santimentanalyser le contenu textuel de sources telles que Twitter et Reddit pour évaluer le sentiment des participants du marché à l'égard des cryptomonnaies. Ils appliquent ensuite des techniques de traitement du langage naturel (NLP) telles que l'analyse de sentiment pour convertir ce texte en indicateurs de sentiment. Ces indicateurs reflètent les opinions et les attentes des investisseurs, offrant ainsi une entrée précieuse pour la prédiction des prix. Par exemple, un sentiment globalement positif sur les réseaux sociaux peut attirer plus d'investisseurs et faire monter les prix, tandis qu'un sentiment négatif pourrait déclencher une pression vendeuse. Des plateformes comme Santiment fournissent également des API et des outils pour aider les développeurs à intégrer les données de sentiment dans les modèles de prédiction.Des études ont montréque l'incorporation de l'analyse du sentiment des médias sociaux peut considérablement améliorer les performances des modèles de prédiction des prix des cryptos, notamment pour les prévisions à court terme.

Santiment peut fournir des données de sentiment sur les avis des participants du marché concernant les cryptomonnaies (Source: Santiment)
Facteurs macroéconomiques
Des indicateurs macroéconomiques tels que les taux d'intérêt, les taux d'inflation, la croissance du PIB et les taux de chômage influencent également les prix des cryptomonnaies. Ces facteurs affectent les préférences en matière de risque des investisseurs et les flux de capitaux. Par exemple, les investisseurs peuvent transférer des fonds d'actifs à haut risque comme les cryptomonnaies vers des alternatives plus sûres lorsque les taux d'intérêt augmentent, entraînant des baisses de prix. En revanche, lorsque l'inflation augmente, les investisseurs peuvent rechercher des actifs préservant la valeur—le Bitcoin est parfois considéré comme une couverture contre l'inflation.
Les données sur les taux d'intérêt, l'inflation, la croissance du PIB et le chômage peuvent généralement être obtenues auprès des gouvernements nationaux ou d'organisations internationales telles que la Banque mondiale ou le FMI. Ces ensembles de données sont généralement disponibles au format CSV ou JSON et peuvent être consultés via des bibliothèques Python comme pandas_datareader.
Le tableau suivant résume les données couramment utilisées sur la chaîne, les indicateurs de sentiment des médias sociaux et les facteurs macroéconomiques, ainsi que la manière dont ils pourraient influencer les prix des cryptomonnaies :

Comment intégrer les données de fonctionnalité
En général, ce processus peut être divisé en quelques étapes :
1. Nettoyage des données et normalisation
Les données provenant de différentes sources peuvent avoir des formats différents, certaines peuvent être manquantes ou incohérentes. Dans de tels cas, le nettoyage des données est nécessaire. Par exemple, convertir toutes les données dans le même format de date, remplir les données manquantes et normaliser les données afin qu'elles puissent être plus facilement comparées.
2. Intégration des données
Après le nettoyage, les données de différentes sources sont fusionnées en fonction des dates, créant un ensemble de données complet qui montre les conditions du marché pour chaque jour.
3. Construction de l'entrée du modèle
Enfin, ces données intégrées sont transformées en un format compréhensible par le modèle. Par exemple, si nous voulons que le modèle prédise le prix d'aujourd'hui en fonction des données des 60 derniers jours, nous organiserions les données de ces 60 jours dans une liste (ou matrice) pour servir d'entrée au modèle. Le modèle apprend les relations au sein de ces données pour prédire les tendances futures des prix.
Le modèle peut tirer parti d'informations plus complètes pour améliorer la précision de la prédiction grâce à ce processus d'ingénierie des fonctionnalités.
Exemples de projets open source
Il existe de nombreux projets populaires de prédiction de prix de cryptomonnaies en open source sur GitHub. Ces projets utilisent différents modèles d'apprentissage machine et d'apprentissage profond pour prédire les tendances de prix de différentes cryptomonnaies.
La plupart des projets utilisent des frameworks populaires d'apprentissage profond comme TensorFlow ou Keraspour construire et former des modèles, apprendre des schémas à partir de données de prix historiques et prédire les mouvements de prix futurs. Le processus entier inclut généralement le prétraitement des données (tel que l'organisation et la normalisation des données de prix historiques), la construction du modèle (définition des couches LSTM et d'autres couches nécessaires), l'entraînement du modèle (ajustement des paramètres du modèle à travers un grand ensemble de données pour réduire les erreurs de prédiction) et l'évaluation finale et la visualisation des résultats de prédiction.
Un tel projet qui utilise des techniques d'apprentissage profond pour prédire les prix des cryptomonnaies est Dat-TG/Prediction-de-prix-de-cryptomonnaie.
Le principal objectif de ce projet est d'utiliser un modèle LSTM pour prédire les prix de clôture du Bitcoin (BTC-USD), de l'Ethereum (ETH-USD) et du Cardano (ADA-USD) afin d'aider les investisseurs à mieux comprendre les tendances du marché. Les utilisateurs peuvent cloner le dépôt GitHub et exécuter l'application en local en suivant les instructions fournies.

Résultats de prédiction BTC pour le projet (Source: Tableau de bord des prix des cryptomonnaies)
La structure du code de ce projet est claire, avec des scripts séparés et des cahiers Jupyter pour obtenir des données, entraîner le modèle et exécuter l'application web. En fonction de la structure du répertoire du projet et en interne code, le processus de construction du modèle de prédiction est le suivant:
- Les données sont téléchargées depuis Yahoo Finance, puis nettoyées et organisées à l'aide de Pandas, y compris des tâches telles que normaliser le format de la date et remplir les valeurs manquantes.
- Les données traitées génèrent une "fenêtre coulissante" - utilisant les 60 derniers jours de données pour prédire le prix du 61e jour.
- Les données sont ensuite alimentées dans un modèle construit en utilisant LSTM (mémoire à court terme et long terme). LSTM se souvient efficacement des changements de prix à court et à long terme, ce qui le rend bien adapté pour prédire les tendances des prix.
- Les résultats de prédiction et les prix réels sont affichés à l'aide de divers graphiques via Plotly Dash, avec un menu déroulant permettant aux utilisateurs de sélectionner différentes cryptomonnaies ou indicateurs techniques, mettant à jour les graphiques en temps réel.

Structure du répertoire du projet (Source: Cryptomonnaie-Prix-Prédiction)
Analyse des risques du modèle de prévision des prix des cryptomonnaies
Impact des événements cygne noir sur la stabilité du modèle
Un événement Cygne Noir est extrêmement rare et imprévisible avec un impact massif. Ces événements sont généralement au-delà des attentes des modèles prédictifs conventionnels et peuvent causer une perturbation importante sur le marché. Un exemple typique est le Luna crashen mai 2022.
Luna, en tant que projet de stablecoin algorithmique, s'appuyait sur un mécanisme complexe avec son jeton frère LUNA pour la stabilité. Début mai 2022, le stablecoin UST de Luna a commencé à se découpler du dollar américain, entraînant des ventes paniques de la part des investisseurs. En raison des failles du mécanisme algorithmique, l'effondrement de l'UST a entraîné une augmentation spectaculaire de l'offre de LUNA. En quelques jours seulement, le prix de LUNA a chuté de près de 80 $ à presque zéro, évitant des centaines de milliards de dollars de valeur marchande. Cela a entraîné des pertes importantes pour les investisseurs impliqués et a suscité de vives inquiétudes concernant les risques systémiques sur le marché des cryptomonnaies.
Ainsi, lorsqu'un événement Cygne Noir se produit, les modèles traditionnels d'apprentissage automatique entraînés sur des données historiques n'auront probablement jamais rencontré de telles situations extrêmes, ce qui conduira les modèles à échouer dans la réalisation de prédictions précises ou même à produire des résultats trompeurs.
Risques intrinsèques du modèle
En plus des événements Cygne Noir, nous devons également être conscients de certains risques inhérents au modèle lui-même, qui peuvent s'accumuler progressivement et affecter la précision des prédictions dans un usage quotidien.
(1) Biais de données et valeurs aberrantes
Dans les séries chronologiques financières, les données présentent souvent une asymétrie ou contiennent des valeurs aberrantes. Si un prétraitement adéquat des données n'est pas effectué, le processus de formation du modèle peut être perturbé par du bruit, ce qui affecte la précision des prévisions.
(2) Modèles trop simplistes et validation insuffisante
Certaines études peuvent s'appuyer trop fortement sur une seule structure mathématique lors de la construction de modèles, en utilisant par exemple uniquement le modèle ARIMA pour capturer les tendances linéaires tout en ignorant les facteurs non linéaires sur le marché. Cela peut conduire à une simplification excessive du modèle. De plus, une validation insuffisante du modèle peut entraîner des performances de backtesting trop optimistes, mais de mauvais résultats de prédiction dans les applications réelles (par exemple, surajustementconduit à d'excellentes performances sur les données historiques mais à des écarts significatifs dans l'utilisation réelle).
(3) Risque de latence des données de l'API
Dans le trading en direct, si le modèle repose sur des API pour les données en temps réel, tout retard dans l'API ou défaut de mise à jour des données en temps utile peut avoir un impact direct sur le fonctionnement du modèle et les résultats des prédictions, entraînant un échec dans le trading en direct.
Mesures visant à améliorer la stabilité du modèle de prédiction
Face aux risques mentionnés ci-dessus, des mesures correspondantes doivent être prises pour améliorer la stabilité du modèle. Les stratégies suivantes sont particulièrement importantes :
(1) Sources de données diverses et prétraitement des données
La combinaison de plusieurs sources de données (telles que les prix historiques, le volume des échanges, les données de sentiment social, etc.) peut compenser les lacunes d'un seul modèle, tandis qu'un nettoyage rigoureux des données, une transformation et une division devraient être effectués. Cette approche améliore la capacité de généralisation du modèle et réduit les risques posés par les biais et les valeurs aberrantes des données.
(2) Sélection des indicateurs d'évaluation de modèle appropriés
Pendant le processus de construction du modèle, il est essentiel de sélectionner les métriques d'évaluation appropriées en fonction des caractéristiques des données (telles que MAPE, RMSE, AIC, BIC, etc.) pour évaluer les performances du modèle et éviter un surajustement de manière exhaustive. La validation croisée régulière et les prévisions roulantes sont également des étapes critiques pour améliorer la robustesse du modèle.
(3) Validation du modèle et itération
Une fois que le modèle est établi, il doit subir une validation approfondie en utilisant une analyse des résidus et des mécanismes de détection des anomalies. La stratégie de prédiction doit être ajustée continuellement en fonction des changements du marché. Par exemple, introduire l'apprentissage conscient du contexte pour ajuster les paramètres du modèle selon les conditions actuelles du marché de manière dynamique est une approche. De plus, combiner des modèles traditionnels avec des modèles d'apprentissage profond pour former un modèle hybride est une méthode efficace pour améliorer la précision et la stabilité des prédictions.
Attention aux risques de conformité
Enfin, en plus des risques techniques, les risques liés à la confidentialité des données et à la conformité doivent être pris en compte lors de l'utilisation de sources de données non traditionnelles telles que les données de sentiment. Par exemple, la Securities and Exchange Commission des États-Unis (SEC)SEC) a des exigences strictes en matière d'examen concernant la collecte et l'utilisation des données de sentiment afin de prévenir les risques juridiques liés aux problèmes de confidentialité.
Cela signifie que, lors du processus de collecte de données, les informations personnellement identifiables (telles que les noms d'utilisateur, les détails personnels, etc.) doivent être anonymisées. Cela vise à empêcher que la vie privée ne soit exposée tout en évitant une utilisation incorrecte des données. De plus, il est essentiel de s'assurer que les sources de données collectées sont légitimes et non obtenues de manière incorrecte (telles que le raclage web non autorisé). Il est également nécessaire de divulguer publiquement les méthodes de collecte et d'utilisation des données, permettant aux investisseurs et aux organismes de réglementation de comprendre comment les données sont traitées et appliquées. Cette transparence aide à empêcher toute manipulation du sentiment du marché à l'aide des données.
Conclusion et Perspectives futures
En conclusion, les modèles de prédiction des prix des cryptomonnaies basés sur l'apprentissage automatique montrent un grand potentiel pour faire face à la volatilité et à la complexité du marché. Intégrer des stratégies de gestion des risques et explorer continuellement de nouvelles architectures de modèles et méthodes d'intégration de données sera une direction importante pour le développement futur de la prédiction des prix des cryptomonnaies. Avec l'avancée de la technologie de l'apprentissage automatique, nous croyons que des modèles de prédiction des prix des cryptomonnaies plus précis et stables émergeront, offrant aux investisseurs un soutien plus solide dans la prise de décisions.
Partager
Contenu
Application de l'apprentissage automatique dans la prédiction des prix des cryptomonnaies
Comparaison des modèles de prédiction
Améliorer la précision de la prédiction avec l'ingénierie des fonctionnalités
Comment intégrer les données de fonctionnalité
Exemples de projets open source
Analyse des risques du modèle de prédiction des prix des cryptomonnaies
Conclusion et perspectives futures


Articles Connexes

Comment faire votre propre recherche (DYOR)?

Qu'entend-on par analyse fondamentale ?
Top 10 Plateformes de trading de jetons MEME

Qu’est-ce que l’analyse technique ?

Que sont les Altcoins ?
