Gate Ventures Research Insights: 第三のブラウザ戦争:AIエージェント時代の参入バトル
独自の分析、投資論、デジタル資産の未来を形作るプロジェクトへの深堀りにアクセスし、最新のフロンティア技術分析やエコシステムの発展を特集しています。TL;DR
第三のブラウザ戦争が静かに進行中です。歴史を振り返ると、1990年代のNetscapeとMicrosoftのInternet Explorerから、オープンソースのFirefoxやGoogleのChromeに至るまで、ブラウザ戦争は常にプラットフォームの支配と技術的パラダイムシフトの集中的な現れでした。Chromeはその迅速な更新速度と統合されたエコシステムのおかげで支配的な地位を確保しており、Googleはその検索とブラウザの独占的な立場を通じて、情報アクセスの閉じたループを形成しています。
しかし、今日、この風景は揺れています。大規模言語モデル(LLM)の台頭により、ますます多くのユーザーが検索結果ページをクリックすることなくタスクを完了できるようになっており、従来のウェブページのクリックは減少しています。一方、AppleがSafariのデフォルト検索エンジンを置き換える意向があるとの噂は、Alphabet(Googleの親会社)の利益基盤をさらに脅かしており、市場は「検索の正統性」についての不安を表し始めています。
ブラウザ自体もその役割の再構築に直面しています。それは単なるウェブページを表示するためのツールではなく、データ入力、ユーザー行動、プライベートアイデンティティを含む複数の機能のコンテナでもあります。AIエージェントは強力ですが、複雑なページインタラクションを完了し、ローカルアイデンティティデータにアクセスし、ウェブページ要素を制御するためには、ブラウザの信頼境界と機能的サンドボックスに依存しています。ブラウザは人間のインターフェースからエージェントのためのシステムコールプラットフォームへと進化しています。
この記事では、ブラウザが依然として必要かどうかを探ります。私たちは、現在のブラウザ市場の風景を真に混乱させるものは「より良いChrome」ではなく、新しいインタラクション構造であると考えています。それは、単なる情報の表示ではなく、タスクの呼び出しです。未来のブラウザは、AIエージェント向けに設計されなければなりません。AIエージェントは、読み取るだけでなく、書き込みおよび実行も可能です。Browser Useのようなプロジェクトは、ページの構造を意味論的にすることを試みており、視覚インターフェースをLLMによって呼び出せる構造化テキストに変換し、ページをコマンドにマッピングし、インタラクションコストを大幅に削減します。
主要なプロジェクトはすでに水面をテストしています:Perplexityは伝統的な検索結果をAIで置き換えるネイティブブラウザCometを構築中です。Braveはプライバシー保護とローカル推論を組み合わせて、検索とブロック機能を強化するためにLLMを使用しています。また、Donutのような暗号ネイティブプロジェクトは、AIがオンチェーン資産と相互作用するための新しい入り口を狙っています。これらのプロジェクトの共通の特徴は、出力層を美化するのではなく、ブラウザの入力層を再構築しようとしている点です。
起業家にとって、機会は入力、構造、エージェントアクセスの三角形の中に存在します。将来のエージェントベースの世界のインターフェースとして、ブラウザは、構造化され、呼び出し可能で、信頼できる「能力」を提供できる者が次世代プラットフォームのコンポーネントになることを意味します。SEOからAEO(エージェンジン最適化)へ、ページトラフィックからタスクチェーンの呼び出しへ、製品の形とデザイン思考が再形成されています。第3次ブラウザ戦争は「表示」ではなく「入力」をめぐって行われています。勝利はもはやユーザーの注意を引く者によって決定されるのではなく、エージェントの信頼を得てアクセスを得る者によって決まります。
ブラウザ開発の簡単な歴史
1990年代初頭、インターネットが日常生活の一部になる前に、Netscape Navigatorは登場し、何百万ものユーザーにデジタル世界への扉を開く帆船のようでした。最初のブラウザではありませんでしたが、初めて大衆に真に届き、インターネット体験を形作ったブラウザでした。初めて、人々はグラフィカルインターフェースを通じて、まるで世界全体が突然アクセス可能になったかのように、簡単にウェブを閲覧できるようになりました。
しかし、栄光はしばしば短命です。マイクロソフトはブラウザの重要性をすぐに認識し、インターネットエクスプローラーをWindowsオペレーティングシステムに強制的にバンドルし、デフォルトのブラウザにしました。この戦略は真の「プラットフォームキラー」であり、ネスケープの市場支配を直接的に脅かしました。多くのユーザーはIEを積極的に選択したわけではなく、単にデフォルトとして受け入れただけでした。Windowsの配布能力を活用して、IEはすぐに業界のリーダーとなり、ネスケープは衰退しました。

逆境の中で、Netscapeのエンジニアたちは急進的で理想主義的な道を選びました — 彼らはブラウザのソースコードを公開し、オープンソースコミュニティに呼びかけました。この決定はテクノロジーの世界における「マケドニアの放棄」のようなもので、古い時代の終わりと新しい力の台頭を示すものでした。そのコードは後にMozillaブラウザプロジェクトの基盤となり、最初はフェニックス(再生を象徴する)と名付けられましたが、いくつかの商標紛争の後、最終的にはファイアフォックスに改名されました。
FirefoxはNetscapeの単なるコピーではありませんでした。ユーザーエクスペリエンス、プラグインエコシステム、セキュリティにおいて革新をもたらしました。その誕生はオープンソースの精神の勝利を示し、業界全体に新たな活力を注ぎ込みました。Firefoxを「精神的な後継者」と表現する人もおり、オスマン帝国が衰退するビザンチウムの栄光を受け継いだのに似ています。誇張されているとはいえ、この比較には意味があります。
しかし、Firefoxが正式にリリースされる前に、Microsoftはすでに6つのバージョンのInternet Explorerをリリースしていました。早期のタイミングとシステムバンドル戦略を活用することで、Firefoxは最初から追いつく立場に置かれ、このレースは同じスタートラインからの平等な競争には決してなりませんでした。
同時に、別の初期のプレーヤーが静かに登場しました。1994年、オペラブラウザがノルウェーで誕生し、最初は単なる実験プロジェクトでした。しかし、2003年のバージョン7.0から、独自に開発したPrestoエンジンを導入し、CSS、適応レイアウト、音声コントロール、Unicodeエンコーディングのサポートを先駆けて行いました。ユーザーベースは限られていましたが、常に技術的に業界をリードし、「ギークのお気に入り」となりました。
その年、AppleはSafariブラウザを立ち上げました — 重要な転換点です。当時、Microsoftは苦境に立たされていたAppleに1億5000万ドルを投資し、競争の体裁を保ち、独占禁止法の監視を回避しようとしていました。Safariのデフォルト検索エンジンは最初からGoogleでしたが、Microsoftとのこの絡みは、インターネットの巨人たちの間の複雑で微妙な関係を象徴していました:協力と競争は常に絡み合っています。
2007年に、IE7はWindows Vistaとともにリリースされましたが、市場の反応は冷淡でした。一方、Firefoxは、より迅速な更新サイクル、よりユーザーフレンドリーな拡張機構、そして開発者に対する自然な魅力のおかげで、市場シェアを約20%にまで安定的に増加させました。IEの支配力は緩み始め、風向きが変わりつつありました。
しかし、Googleは異なるアプローチを取りました。2001年から独自のブラウザを計画していたものの、CEOのエリック・シュミットをプロジェクト承認に納得させるのに6年かかりました。Chromeは2008年にデビューし、ChromiumオープンソースプロジェクトとSafariで使用されているWebKitエンジンを基に構築されました。「肥大化した」ブラウザとして嘲笑されましたが、Googleの広告とブランド構築の深い専門知識により、急速に成長しました。
Chromeの主な武器はその機能ではなく、頻繁な更新サイクル(6週間ごと)と統一されたクロスプラットフォーム体験でした。2011年11月、Chromeは初めてFirefoxを超え、27%の市場シェアに達しました。6ヶ月後にはIEを抜き、挑戦者から支配的なリーダーへの変革を完了しました。
一方、中国のモバイルインターネットは独自のエコシステムを形成していました。アリババのUCブラウザーは2010年代初頭に人気が急上昇し、特にインド、インドネシア、中国などの新興市場で支持を集めました。軽量なデザインとデータ圧縮機能により帯域幅を節約し、低価格のデバイスを使用するユーザーを獲得しました。2015年までに、世界のモバイルブラウザ市場シェアは17%を超え、インドではかつて46%に達したこともありました。しかし、この勝利は長続きしませんでした。インド政府が中国のアプリのセキュリティ審査を厳格化するにつれて、UCブラウザーは主要市場からの撤退を余儀なくされ、徐々に以前の栄光を失っていきました。
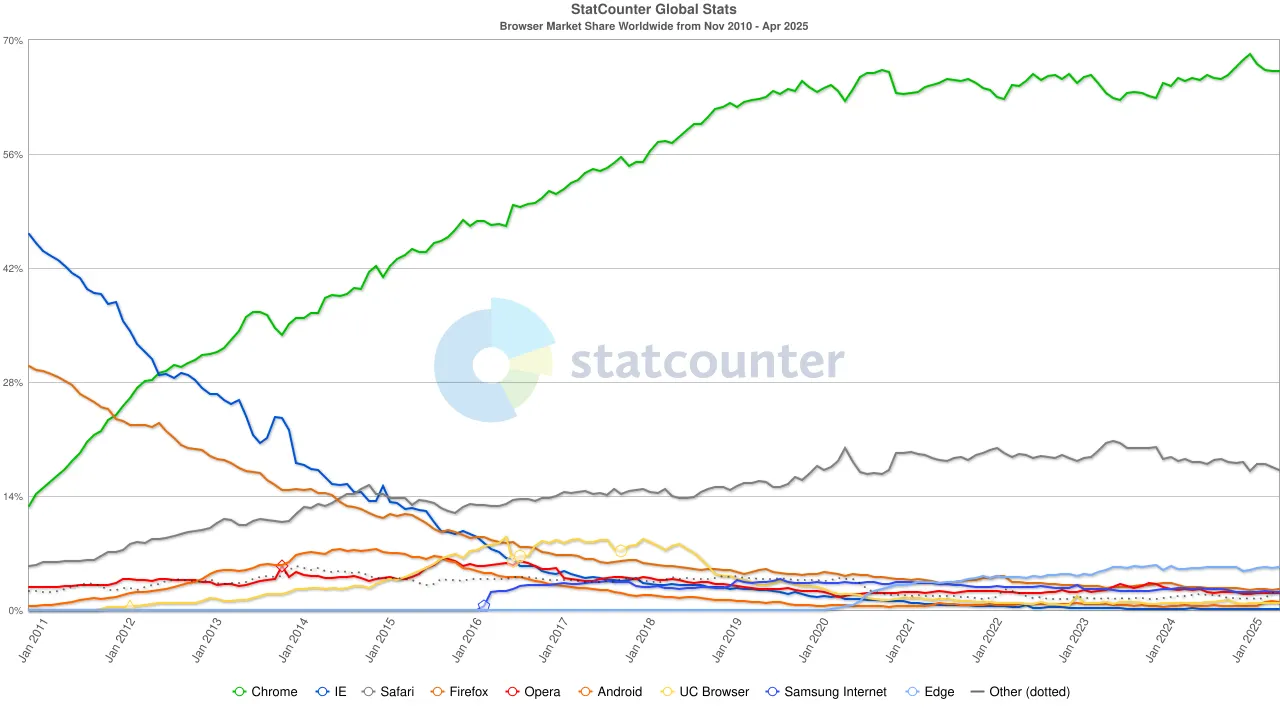
2020年代には、Chromeの支配が確立され、世界市場シェアは約65%で安定しました。特に、Googleの検索エンジンとChromeブラウザはどちらもAlphabetに属していますが、市場の観点から見ると、前者は世界の検索トラフィックの約90%をコントロールし、後者はほとんどのユーザーがインターネットにアクセスする「最初の窓口」として機能する、二つの独立した覇権を代表しています。
この二重独占構造を維持するために、Googleは一切の費用を惜しまなかった。2022年、AlphabetはAppleに約200億ドルを支払い、GoogleをSafariのデフォルトの検索エンジンとして維持した。アナリストたちは、この費用がGoogleがSafariトラフィックから得た検索広告収益の約36%に相当すると指摘している。言い換えれば、Googleは実質的に自社の防護壁を守るために「保護料」を支払っていた。
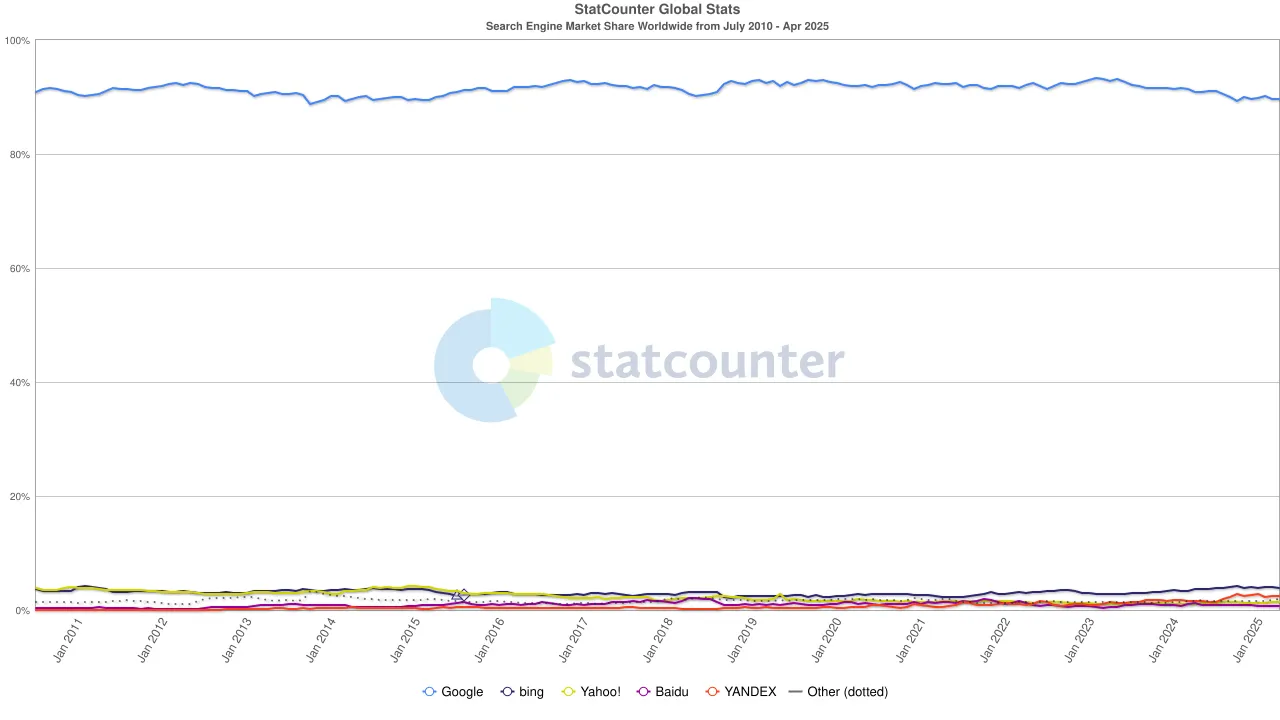
しかし、潮流は再び変わった。大規模言語モデル(LLM)の台頭により、従来の検索が影響を受け始めた。2024年には、Googleの検索市場シェアは93%から89%に減少した。まだ支配的ではあるものの、ひびが入ってきている。さらに破壊的だったのは、Appleが独自のAI駆動の検索エンジンを立ち上げるかもしれないという噂だった。もしSafariのデフォルト検索がAppleの独自のエコシステムに切り替わった場合、競争の風景を一新するだけでなく、Alphabetの利益の根本を揺るがす可能性もあった。市場は迅速に反応した:Alphabetの株価は$170から$140に下落し、投資家のパニックだけでなく、検索の時代の今後の方向性に対する深い不安も反映していた。
ナビゲーターからChromeへ、オープンソースの理念から広告主導の商業化へ、軽量ブラウザからAI検索アシスタントへ、ブラウザの戦いは常に技術、プラットフォーム、コンテンツ、そしてコントロールの戦争でした。戦場は常に変わっていますが、本質は決して変わりません:ゲートウェイを制御する者が未来を定義します。
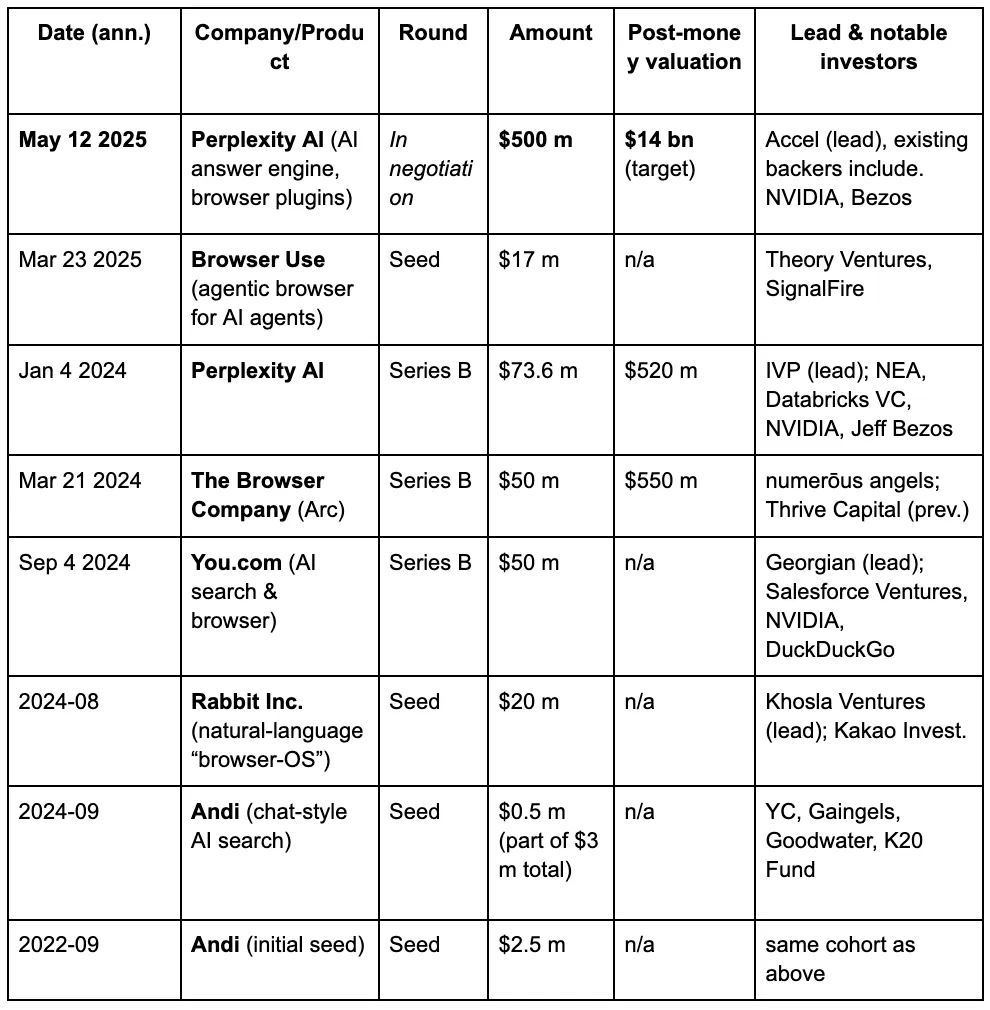
ベンチャーキャピタリストの目には、LLMやAIの時代に人々が検索エンジンに対して求める新たな要求によって、第三のブラウザ戦争が徐々に展開されているように映っています。以下は、AIブラウザトラックにおけるいくつかの有名なプロジェクトの資金調達の詳細です。
現代ブラウザの古いアーキテクチャ
ブラウザアーキテクチャについて言えば、クラシックな従来の構造は以下の図に示されています。
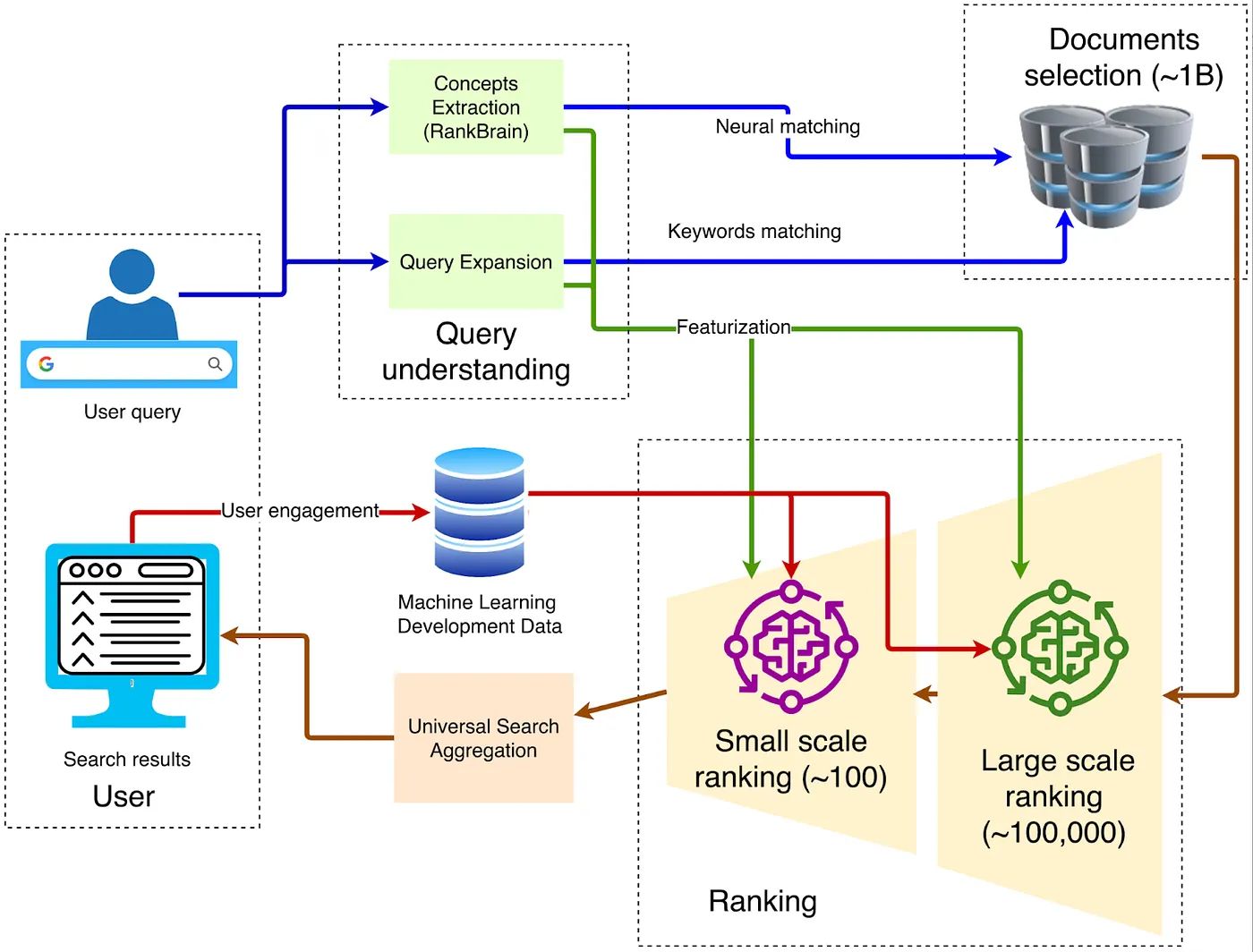
1. クライアント — フロントエンドエントリー
クエリはHTTPS経由で最寄りのGoogleフロントエンドに送信され、そこでTLS復号化、QoSサンプリング、地理的ルーティングが行われます。異常なトラフィックが検出された場合(DDoS攻撃や自動スクレイピングなど)、この層でレート制限やチャレンジが適用されることがあります。
2. クエリの理解
フロントエンドは、ユーザーが入力した言葉の意味を理解する必要があります。これには三つのステップが含まれます:
ニューラルスペル修正、例えば「recpie」を「recipe」に変えること。
同義語の拡張、例えば「自転車を修理する方法」を「自転車を修理する」に拡張すること。
意図解析は、クエリが情報型、ナビゲーション型、または取引型であるかを判断し、適切な縦型リクエストを割り当てます。
3. 候補者の取得
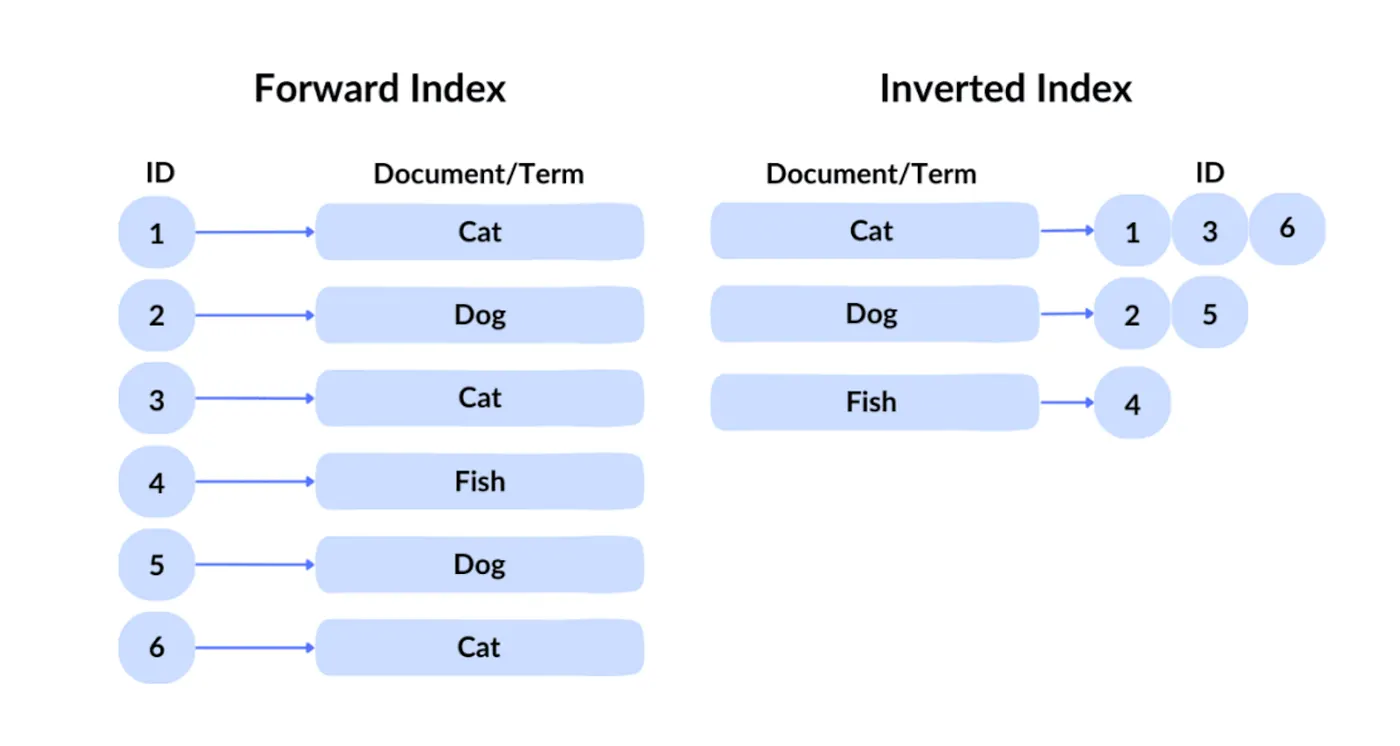
Googleのクエリ技術は逆インデックスとして知られています。フォワードインデックスでは、IDを指定してファイルを取得します。しかし、ユーザーは数千億のファイルの中から望ましいコンテンツの識別子を知ることができないため、Googleは従来の逆インデックスを使用し、コンテンツによってクエリを実行して対応するキーワードを含むファイルを特定します。
次に、Googleはベクトルインデックスを適用してセマンティック検索を処理します。つまり、クエリと意味的に類似したコンテンツを見つけます。テキスト、画像、その他のコンテンツを高次元ベクトル(埋め込み)に変換し、それらのベクトルの類似性に基づいて検索します。例えば、ユーザーが「ピザ生地の作り方」と検索すると、検索エンジンは「ピザ生地の準備ガイド」に関連する結果を返すことができます。なぜなら、両者は意味的に類似しているからです。
逆転インデックスとベクトルインデックスを通じて、初期スクリーニング段階でおおよそ数十万のウェブページがフィルタリングされます。
4. マルチステージランキング
システムは通常、BM25、TF-IDF、ページ品質スコアなどの数千の軽量機能を使用して、数十万の候補ページを約1,000に絞り込み、初期の候補セットを形成します。このようなシステムは総称してレコメンデーションエンジンと呼ばれます。これらは、ユーザーの行動、ページの属性、クエリの意図、コンテキスト信号など、さまざまなエンティティから生成される膨大な特徴に依存しています。たとえば、Googleはユーザーの履歴、他のユーザーからのフィードバック、ページの意味論、クエリの意味を組み合わせ、時間(1日の時間、週の日)や突発的なニュースのような外部イベントなどのコンテキスト要素も考慮します。
5. プライマリランキングのための深層学習
初期の取得段階では、GoogleはRankBrainやNeural Matchingなどの技術を使用して、クエリの意味を理解し、大量のドキュメントコレクションから最も関連性の高い結果をフィルタリングします。
RankBrainは、2015年にGoogleによって導入された機械学習システムで、特にこれまでに見たことのないユーザーのクエリの意味をよりよく理解するために設計されています。それはクエリとドキュメントをベクトル表現に変換し、それらの類似性を計算して最も関連性の高い結果を見つけます。たとえば、「ピザ生地の作り方」というクエリの場合、正確なキーワードの一致を含むドキュメントがなくても、RankBrainは「ピザの基本」や「生地の準備」に関連するコンテンツを特定できます。
ニューラルマッチングは2018年に開始され、クエリと文書の間の意味的関係をさらに捉えることを目的としています。ニューラルネットワークモデルを使用して、単語間のあいまいな関係を特定し、クエリとウェブコンテンツをより適切にマッチングします。例えば、「なぜ私のノートパソコンのファンはこんなにうるさいのか」というクエリに対して、ニューラルマッチングは、ユーザーが過熱、ほこりの蓄積、または高いCPU使用率に関するトラブルシューティング情報を求めている可能性があることを理解できます—たとえそれらの用語がクエリに明示的に表示されていなくても。
6. ディープ再ランキング:BERTの応用
関連文書の初期フィルタリングの後、GoogleはBERT(Bidirectional Encoder Representations from Transformers)を適用してランキングを洗練させ、最も関連性の高い結果が上位に表示されることを保証します。BERTは、文の中の単語の文脈的関係を理解できるTransformerに基づく事前訓練された言語モデルです。
検索では、BERTは前の段階で取得した文書の再ランキングに使用されます。クエリと文書を共同でエンコードし、関連性スコアを計算し、文書を再整理します。たとえば、「縁石のない丘に駐車する」というクエリに対して、BERTは「縁石のない」という意味を正しく解釈し、ドライバーに対して車輪を路肩に向けるようにアドバイスする結果を返すことができます。縁石がある状況として誤解することはありません。
SEOエンジニアにとって、これは彼らがGoogleのランキングおよび機械学習推薦アルゴリズムを慎重に研究し、ターゲットを絞った方法でウェブコンテンツを最適化する必要があることを意味し、その結果、検索ランキングでの可視性を高めることができるということです。
AIがブラウザを再形成する理由
まず、明確にする必要があります: なぜブラウザという形がまだ存在する必要があるのか? AIエージェントとブラウザの他に第三のパラダイムは存在するのでしょうか?
私たちは、存在が置き換え不可能であることを意味すると信じています。なぜ人工知能はブラウザを使用できるのに、完全に置き換えることができないのでしょうか?それは、ブラウザが普遍的なプラットフォームだからです。それは、データを読むための入り口であるだけでなく、データを入力するための一般的な入り口でもあります。世界は情報を消費するだけではなく、データを生産し、ウェブサイトと相互作用しなければなりません。したがって、個人化されたユーザー情報を統合したブラウザは、引き続き広く存在し続けるでしょう。
重要なポイントは、ブラウザが普遍的なゲートウェイとして、単にデータを読むためだけのものではないということです。ユーザーはしばしばデータと対話する必要があります。ブラウザ自体は、ユーザーフィンガープリントを保存するための優れたリポジトリです。より複雑なユーザーの行動や自動化されたアクションは、ブラウザを通じて行う必要があります。ブラウザはすべてのユーザー行動フィンガープリント、認証情報、その他のプライベート情報を保存でき、自動化中の信頼不要な呼び出しを可能にします。データとの対話は、このパターンに進化する可能性があります:
ユーザー → AIエージェントを呼ぶ → ブラウザ。
言い換えれば、置き換えられる可能性があるのは、世界の自然なトレンド—より高い知能、パーソナライズ、そして自動化—の部分だけです。確かに、この部分はAIエージェントによって扱われることができます。しかし、AIエージェント自体はパーソナライズされたユーザーコンテンツを持ち運ぶのには適していません。なぜなら、データセキュリティや使いやすさに関する複数の課題に直面しているからです。具体的には:
ブラウザはパーソナライズされたコンテンツのリポジトリです。
ほとんどの大規模モデルはクラウドにホストされており、セッションコンテキストはサーバーのストレージに依存しているため、ローカルのパスワード、ウォレット、クッキー、その他の機密データに直接アクセスすることが難しくなっています。
すべての閲覧および支払いデータを第三者モデルに送信するには、ユーザーの再認証が必要です。EUのDMAおよび米国の州レベルのプライバシー法は、国境を越えたデータ最小化を要求します。
二要素認証コードの自動入力、カメラの呼び出し、またはWebGPU推論のためのGPUの使用は、すべてブラウザのサンドボックス内で行う必要があります。
データコンテキストはブラウザに大きく依存しています。タブ、クッキー、IndexedDB、Service Worker Cache、パスキー資格情報、および拡張データはすべてブラウザ内に保存されます。
相互作用の形態における深い変化
最初の話題に戻ると、ブラウザを使用する際の私たちの行動は一般的に3つのカテゴリに分けられます:データを読むこと、データを入力すること、データと対話することです。大規模言語モデル(LLM)は、私たちがデータを読む効率と方法を既に深く変えました。ユーザーがキーワードを通してウェブページを検索するという古い手法は、今では時代遅れで非効率的に思えます。
ユーザーの検索行動の進化に関しては、要約された回答を得ることを目的とするのか、ウェブページにクリックして移動することを目的とするのかにかかわらず、この変化を分析した研究が多数存在します。
ユーザー行動パターンに関する2024年の研究によると、アメリカでは、1,000件のGoogle検索のうち、わずか374件がウェブページのクリックで終わりました。言い換えれば、約63%が「ゼロクリック」行動でした。ユーザーは、天気、為替レート、知識カードなどの情報を検索結果ページから直接取得することに慣れています。
しかし、ブラウザの大規模な変革を真に引き起こす可能性があるのは、データインタラクションレイヤーです。これまで、人々は主にキーワードを入力することでブラウザと対話してきました。これは、ブラウザ自体が処理できる理解の最大レベルでした。現在、ユーザーはますます複雑なタスクを説明するために自然言語をフルに使用することを好むようになっています。たとえば:
「一定の期間中にニューヨークからロサンゼルスへの直行便を探してください。」
「ニューヨークから上海、そしてロサンゼルスへのフライトを探して。」
人間にとっても、そのようなタスクは複数のウェブサイトを訪れ、情報を集め、結果を比較するのに多くの時間を要します。しかし、これらのエージェンティックタスクは徐々にAIエージェントに引き継がれています。
これは歴史の軌跡とも一致しています:自動化と知性。人々は手を自由にしたいと望んでおり、AIエージェントは間違いなくブラウザに深く組み込まれることになります。将来のブラウザは、特に以下を考慮して、完全自動化を念頭に置いて設計される必要があります:
人間の読書体験とAIエージェントの機械解釈可能性をどのようにバランスさせるか。
エンドユーザーとエージェントモデルの両方に対応する単一のウェブページをどのように確保するか。
これらのデザイン要件の両方を満たすことによってのみ、ブラウザはAIエージェントがタスクを実行するための真の安定したキャリアとなることができます。
次に、私たちは5つの注目すべきプロジェクト—Browser Use、Arc(The Browser Company)、Perplexity、Brave、Donutに焦点を当てます。これらのプロジェクトは、AIブラウザの進化の将来の方向性を示すだけでなく、Web3および暗号の文脈内でのネイティブ統合の可能性を示しています。
ユーザー心理の観点から、2023年の調査では、回答者の44%が、フィーチャーされたスニペットよりも通常のオーガニック結果をより信頼できると考えていることが示されました。学術研究でも、論争がある場合や単一の権威ある真実がない場合、ユーザーは複数のソースからのリンクを含む結果ページを好むことがわかっています。
言い換えれば、一部のユーザーはAI生成の要約を完全に信頼していないものの、行動のかなりの割合は「ゼロクリック」にシフトしています。したがって、AIブラウザは、特にデータ読み取りの分野において、適切なインタラクションパラダイムを探る必要があります。大規模モデルにおける幻覚問題はまだ完全には解決されていないため、多くのユーザーは自動生成されたコンテンツ要約を完全に信頼するのに苦労しています。この点において、大規模モデルをブラウザに組み込むことは必ずしも破壊的な変革を必要としません。むしろ、精度と制御性の漸進的な改善が必要であり、それはすでに進行中のプロセスです。
ブラウザ使用
これは、PerplexityとBrowser Useが受けた大規模な資金調達の背後にある核心的な論理です。特に、Browser Useは2025年初頭の最も有望なイノベーション機会の第2位として浮上しており、確実性と強い成長の可能性を兼ね備えています。

Browser Useは、次世代ブラウザのためのセマンティック認識アーキテクチャの構築に核心を置いた真のセマンティックレイヤーを構築しました。
Browser Useは、従来の「DOM = 人間が見るためのノードツリー」を「Semantic DOM = LLMが読むための命令ツリー」と再解釈します。これにより、エージェントは「ピクセル座標」に頼ることなく、正確にクリック、入力、およびアップロードすることができます。視覚的OCRや座標ベースのSeleniumを使用する代わりに、このアプローチは「構造化テキスト → 関数呼び出し」のルートを取り、実行を迅速にし、トークンを節約し、エラーを減らします。TechCrunchはこれを「AIがウェブページを真に理解できるようにする接着層」と表現しました。3月に、Browser Useは1700万ドルのシードラウンドを閉じ、この基盤となる革新に賭けました。
こちらがその仕組みです:
HTMLがレンダリングされると、標準のDOMツリーが形成されます。その後、ブラウザはアクセシビリティツリーを導出し、スクリーンリーダー向けにより豊かな「役割」や「状態」のラベルを提供します。
各インタラクティブ要素(ボタン、入力など)は、役割、可視性、座標、実行可能なアクションなどのメタデータを持つJSONスニペットに抽象化されています。
ページ全体がフラット化された意味的ノードのリストに翻訳され、LLMはこれを単一のシステムプロンプトで読み取ることができます。
LLMは高レベルの指示(たとえば、click(node_id="btn-Checkout"))を出力し、それが実際のブラウザで再生されます。
公式ブログではこのプロセスを「ウェブサイトのインターフェースをLLMが解析できる構造化されたテキストに変換する」と説明しています。
さらに、この標準がW3Cによって採用される場合、ブラウザの入力問題を大いに解決できる可能性があります。次に、The Browser Companyからの公開書簡とケーススタディを見て、彼らのアプローチがなぜ欠陥があるのかをさらに説明します。
弧
ブラウザ会社(Arcの親会社)は、オープンレターでArcブラウザが定期メンテナンスモードに入ることを発表し、チームはAIに完全に特化したブラウザであるDIAの開発に焦点を移すと述べました。レターの中で、彼らはまたDIAの具体的な実装方法がまだ決まっていないことを認めました。同時に、チームはブラウザ市場の未来に関するいくつかの予測を示しました。
これらの予測に基づいて、現在のブラウザの状況が本当に変革されるのであれば、鍵はインタラクションの出力側を変更することにあると私たちはさらに信じています。
以下は、Arcチームが共有した未来のブラウザ市場についての3つの予測です。
https://browsercompany.substack.com/p/letter-to-arc-members-2025
まず、Arcチームはウェブページが対話の主要なインターフェースではなくなると考えています。確かに、これは大胆で挑戦的な主張であり、私たちが彼らの創設者の考えに懐疑的であり続ける主な理由でもあります。私たちの見解では、この視点はブラウザの役割を大幅に過小評価しており、AIブラウザの道を探る際にチームが見落とした重要な問題を浮き彫りにしています。
大規模モデルは、意図を捉える点で優れたパフォーマンスを発揮します。たとえば、「フライトを予約するのを手伝って」という指示を理解することです。しかし、情報密度を持つ場合には依然として不十分です。ユーザーがダッシュボード、ブルームバーグターミナルスタイルのノートブック、またはFigmaのようなビジュアルキャンバスを必要とする場合、ピクセル単位の精度を持ったきめ細かなウェブページを上回るものはありません。各製品のエルゴノミクス—チャート、ドラッグアンドドロップ機能、ホットキー—は表面的な装飾ではなく、認知を圧縮するための重要な機能です。これらの機能は、単純な会話的インタラクションでは再現できません。Gate.comを例に取ると、ユーザーが投資アクションを実行したい場合、AIの会話だけに頼るのは全く不十分です。ユーザーは構造化された入力、正確さ、情報の明確な提示に大きく依存しています。
Arcチームのロードマップには根本的な欠陥があります。それは、「インタラクション」が入力と出力の2次元から成り立っていることを明確に区別していない点です。入力側において、AIがコマンドスタイルのインタラクションの効率を確実に改善できるため、彼らの見解には特定のシナリオで一定の妥当性があります。しかし出力側において、彼らの仮定は明らかに不均衡であり、情報の提示とパーソナライズされた体験におけるブラウザーの核心的な役割を見落としています。例えば、Redditは独自のレイアウトと情報アーキテクチャを持つ一方で、AAVEは全く異なるインターフェースと構造を持っています。高度にプライベートなデータを同時に保存し、多様な製品インターフェースを提供するプラットフォームとして、ブラウザーは入力側で限られた代替可能性しか持たず、出力側の複雑さと非標準化された性質がそれをさらに妨げています。
対照的に、現在のAIブラウザは主に「出力要約」層に集中しています:ページの要約、情報の抽出、結論の生成です。これは、Googleのような主流のブラウザや検索システムに根本的な挑戦をもたらすには不十分であり、検索要約の市場シェアを少しずつ削っているに過ぎません。
したがって、Chromeの66%の市場シェアを真に揺るがすことができる技術は、「次のChrome」になる運命ではありません。本当の破壊的変化を達成するためには、ブラウザのレンダリングモデルを根本的に再構築し、AIエージェント時代のインタラクションニーズに適応する必要があります。特に、入力側のアーキテクチャ設計においてです。だからこそ、私たちはBrowser Useが取った技術的な道筋をはるかに納得のいくものと見なしています。それは、ブラウザの基盤メカニズムにおける構造的変化に焦点を当てています。いかなるシステムが「原子」または「モジュール」デザインを達成すると、そこから生まれるプログラマビリティとコンポーザビリティが破壊的な可能性を解き放ちます。これが、Browser Useが今日追求している方向性です。
要約すると、AIエージェントの運用は依然としてブラウザの存在に大きく依存しています。ブラウザは複雑な個別データの主要なリポジトリであるだけでなく、多様なアプリケーションの普遍的なレンダリングインターフェースでもあり、したがって将来的にもインタラクションの中核となるゲートウェイとして機能し続けるでしょう。AIエージェントが固定タスクを完了するためにブラウザに深く組み込まれるにつれて、ユーザーデータや特定のアプリケーションと主に入力側を通じてインタラクションします。この理由から、現在のブラウザのレンダリングモデルは革新され、AIエージェントとの最大の互換性と適応性を達成する必要があります。最終的には、アプリケーションをより効果的にキャッチすることを可能にします。
混乱
Perplexityは、その推薦システムで知られるAI検索エンジンです。最新の評価額は140億ドルに急騰し、2024年6月の30億ドルからほぼ5倍の増加となりました。現在、月間で4億件以上の検索クエリを処理しています。2024年9月だけで、約2.5億件のクエリを処理し、ユーザーの検索ボリュームは前年同期比で8倍の増加を記録し、月間のアクティブユーザーは3000万人を超えました。
その主な機能は、ページをリアルタイムで要約する能力であり、最新の情報にアクセスする上で強力な利点を提供します。今年の初め、Perplexityは独自のネイティブブラウザであるCometの開発を開始しました。同社はCometを、単にウェブページを「表示」するだけでなく、それについて「考える」ブラウザだと説明しています。公式には、Perplexityの回答エンジンをブラウザ自体に深く埋め込むことを主張しており、Steve Jobsの哲学を思い起こさせる「全機械」アプローチに従っています。つまり、サイドバーのプラグインを単に構築するのではなく、AIタスクをブラウザの基盤レベルで深く統合することを目指しています。
簡潔な回答と引用をもとに、Cometは従来の「十の青いリンク」を置き換え、Chromeと直接競争することを目指しています。
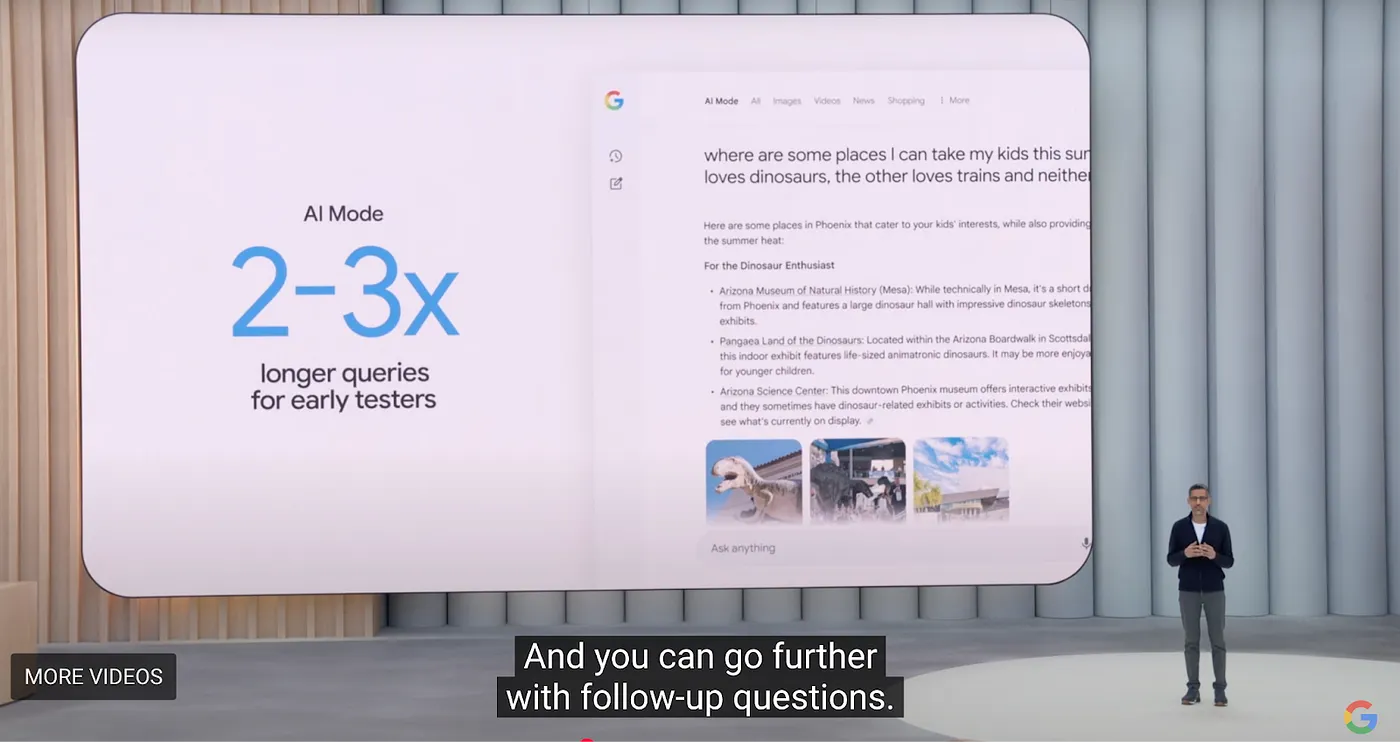
しかし、Perplexityはまだ2つのコア問題を解決する必要があります:高い検索コストとマージナルユーザーからの低い利益率です。現在、PerplexityはAI検索分野でリードしていますが、Googleは2025年のI/Oカンファレンスで、コア製品の大規模なインテリジェントな改修を発表しました。ブラウザ向けに、Googleは「AI Model」と呼ばれる新しいブラウザタブ体験を立ち上げ、Overview、Deep Research、未来のAgentic機能を統合しています。この全体の取り組みは「Project Mariner」と呼ばれています。
GoogleはAI変革を積極的に進めており、Overview、Deep Research、Agenticsなどの表面的な機能模倣は、実際の脅威とはほとんどならないということです。混乱の中で新しい秩序を確立するためには、ブラウザのアーキテクチャをゼロから再構築し、大規模言語モデル(LLM)をブラウザカーネルに深く埋め込み、インタラクション方法を根本的に変革することが必要です。
ブレイブ
Braveは、暗号業界内で最も早く、成功したブラウザの一つです。Chromiumアーキテクチャに基づいて構築されており、Googleストアの拡張機能と互換性があります。Braveは、プライバシーを基盤とし、ブラウジングを通じてトークンを獲得するモデルでユーザーを惹きつけています。その開発の道筋は、一定の成長可能性を示しています。しかし、製品の観点から見ると、プライバシーは確かに重要ですが、需要は特定のユーザーグループに集中しています。一般の人々にとって、プライバシー意識はまだ主流の意思決定要因にはなっていません。したがって、この機能だけに頼って既存の巨人を破壊しようとするのは成功する可能性が低いでしょう。
現在、Braveは月間アクティブユーザー(MAU)が8270万人、日間アクティブユーザー(DAU)が3560万人に達し、市場シェアは約1%–1.5%です。ユーザーベースは安定した成長を示しており、2019年7月の600万人から2021年1月の2500万人、2023年1月の5700万人、そして2025年2月には8200万人を超えました。その年間成長率は二桁のままです。
Braveは月に約13.4億件の検索クエリを処理しており、これはGoogleのボリュームの約0.3%です。
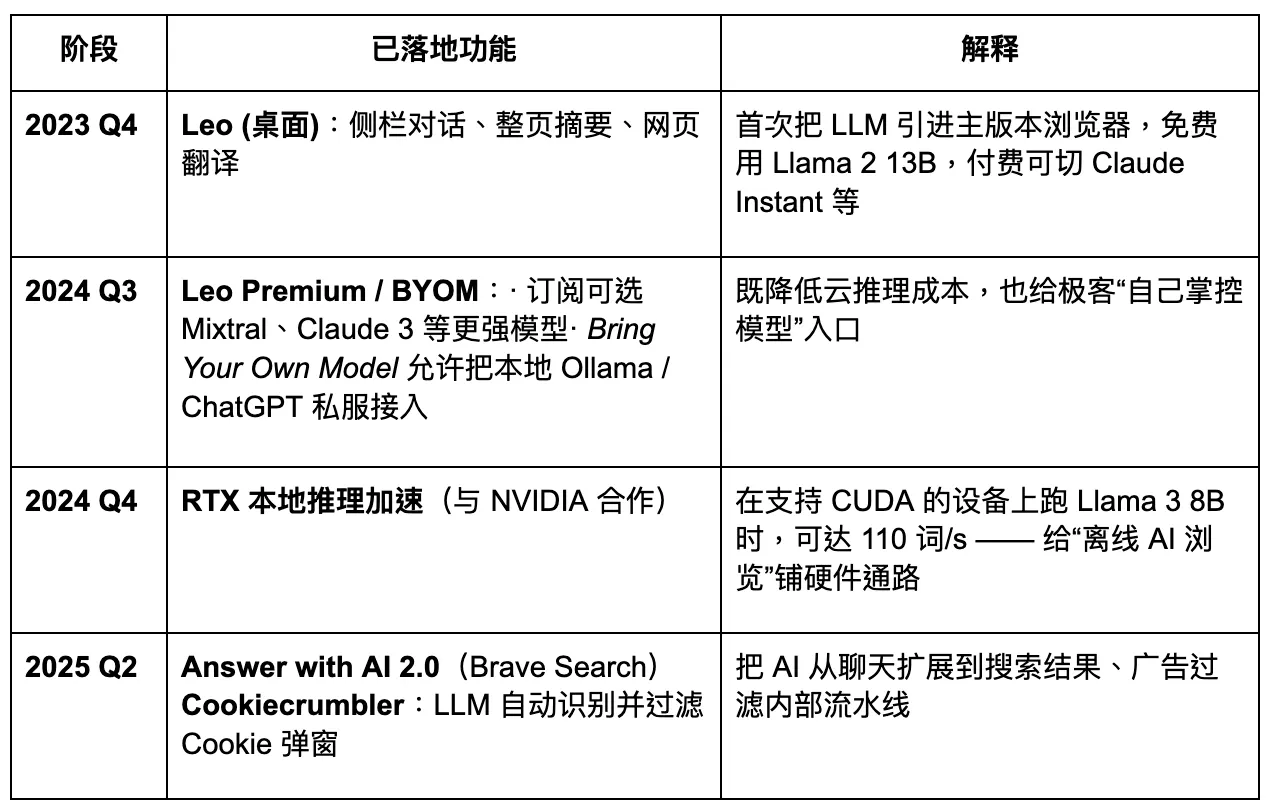
Braveはプライバシーを重視したAIブラウザへのアップグレードを計画しています。しかし、ユーザーデータへのアクセスが制限されているため、大規模モデルに対するカスタマイズのレベルが低下し、その結果、迅速で正確な製品の反復が妨げられています。今後のエージェントブラウザ時代において、Braveは特定のプライバシー重視のユーザーグループの中で安定したシェアを維持するかもしれませんが、支配的なプレーヤーになることは難しいでしょう。そのAIアシスタントであるLeoは、プラグインの強化のように機能しており、いくつかのコンテンツ要約機能を提供していますが、AIエージェントへの完全な移行に向けた明確な戦略は欠けています。インタラクションにおける革新は不十分なままです。
ドーナツ
最近、暗号業界はエージェンティックブラウザの分野でも進展を遂げています。初期段階のプロジェクトDonutは、香港山(セコイア・チャイナ)、HackVC、Bitkraft Venturesが主導するプレシードラウンドで700万ドルを調達しました。このプロジェクトはまだ初期の概念段階にあり、「発見 – 意思決定 – そして暗号ネイティブな実行」という統合能力を達成することを目指しています。
コアの方向性は、暗号ネイティブな自動化実行パスを組み合わせることです。a16zが予測したように、エージェントは将来的に主要なトラフィックゲートウェイとして検索エンジンに取って代わるかもしれません。起業家はもはやGoogleのランキングアルゴリズムを巡って競争するのではなく、エージェントの実行から得られるトラフィックとコンバージョンを巡って争うことになります。この業界はすでにこのトレンドを「AEO」(回答/エージェントエンジン最適化)と名付け、さらには「ATF」(エージェントタスクの履行)と呼ぶまでになっています。ここでの目標はもはや検索ランキングを最適化することではなく、ユーザーのためにタスクを完了できるインテリジェントモデルに直接サービスを提供することです。たとえば、注文を出したり、チケットを予約したり、手紙を書いたりすることです。
起業家のために
まず、認識されなければならないのは、ブラウザ自体がインターネットの世界で最大の未改造の「Gateway」であるということです。全世界で約21億のデスクトップユーザーと43億以上のモバイルユーザーがいるそれは、データ入力、インタラクティブな行動、およびパーソナライズされたフィンガープリントストレージのための共通のキャリアとして機能しています。その持続性の理由は慣性ではなく、ブラウザの本質的な二重性にあります:データを読むための入り口であり、アクションを書くための出口でもあるのです。
したがって、起業家にとって、真の破壊的な可能性は「ページ出力」層の最適化にはありません。たとえ新しいタブでGoogleのようなAI概要機能を再現できたとしても、それは依然としてプラグイン層でのイテレーションに過ぎず、根本的なパラダイムシフトではありません。本当のブレークスルーは「入力側」にあります。つまり、AIエージェントが特定のタスクを完了するためにどのようにあなたの製品を積極的に呼び出すかです。これが、製品がエージェントエコシステムに組み込まれ、トラフィックをキャッチし、価値分配に参加できるかどうかを決定します。
検索時代では、競争はクリックに関するものでした; エージェント時代では、競争はコールに関するものです。
もしあなたが起業家であれば、製品をAPIコンポーネントとして再考すべきです。つまり、インテリジェントエージェントが理解できるだけでなく、呼び出すこともできるものです。これには、製品設計の初めから3つの次元を考慮する必要があります:
1. インターフェース構造の標準化: あなたの製品は呼び出せますか?
エージェントが製品を呼び出す能力は、その情報構造が標準化され、明確なスキーマに抽象化できるかどうかに依存します。たとえば、ユーザー登録、注文の配置、またはコメントの送信などの主要なアクションは、セマンティックDOM構造またはJSONマッピングを通じて記述できますか?システムは、エージェントがユーーワークフローを信頼性を持って再現できるように状態遷移機構を提供していますか?ページ上でのユーザーインタラクションはスクリプト化できますか?製品は安定したWebhookまたはAPIエンドポイントを提供していますか?
これがまさにBrowser Useが資金調達に成功した理由です。それは、ブラウザを平面的なHTMLレンダラーからLLMによって呼び出されるセマンティックツリーへと変革しました。起業家にとって、ウェブ製品において同様のデザイン哲学を採用することは、AIエージェント時代における構造化された適応に備えることを意味します。
2. アイデンティティとアクセス: エージェントが「信頼のバリアを越える」手助けをしてくれますか?
エージェントが取引を完了させたり、支払いおよび資産機能を呼び出したりするためには、信頼できる仲介者が必要です—あなたはその仲介者になれますか?ブラウザは自然にローカルストレージを読み取り、ウォレットにアクセスし、CAPTCHAを処理し、二要素認証を統合する能力を持っています。これにより、タスクを実行するためにクラウドホスティングモデルよりも適していると言えます。これは特にWeb3において当てはまり、資産の相互作用インターフェースは標準化されていません。「アイデンティティ」や「署名能力」がなければ、エージェントは前に進むことができません。
暗号起業家にとって、これは非常に想像力豊かなホワイトスペースを開きます:ブロックチェーンの世界の「MCP(マルチケイパビリティプラットフォーム)」。これは、エージェントがDappsを呼び出すことを可能にするユニバーサルコマンドレイヤー、標準化された契約インターフェースセット、または軽量のローカルウォレット + IDハブの形を取る可能性があります。
3. トラフィックメカニズムの再考: 未来はSEOではなく、AEO / ATFです。
過去には、Googleのアルゴリズムを勝ち取る必要がありましたが、今ではAIエージェントのタスクチェーンに埋め込まれる必要があります。これは、あなたの製品が明確なタスクの粒度を持っている必要があることを意味します:単なる「ページ」ではなく、呼び出し可能な能力ユニットの一連です。また、エージェントエンジン最適化(AEO)を最適化するか、エージェントタスクの実行(ATF)に適応し始めることも意味します。たとえば、登録プロセスを構造化されたステップに簡素化できるでしょうか?価格設定をAPIを通じて引き出すことはできますか?在庫はリアルタイムでアクセス可能ですか?
異なるLLMフレームワーク間で異なる呼び出し構文に適応する必要があるかもしれません。たとえば、OpenAIとClaudeは、関数呼び出しやツールの使用に異なる好みを持っています。Chromeは古い世界の端末であり、新しい世界へのゲートウェイではありません。未来のプロジェクトはブラウザを再構築するのではなく、ブラウザがエージェントにサービスを提供できるようにすること—新しい世代の「指示フロー」のための橋を構築することです。
あなたが構築する必要があるのは、エージェントがあなたの世界を呼び出すための「インターフェース言語」です。
あなたが得る必要があるのは、インテリジェントシステムの信頼チェーンの中の地位です。
次の検索パラダイムで構築する必要があるのは、「APIキャッスル」です。
もしWeb2がUIを通じてユーザーの注意を引いていたのなら、Web3 + AIエージェント時代はコールチェーンを通じてエージェントの実行意図を捉えるでしょう。
免責事項
この内容は、提案、勧誘、または推奨を構成するものではありません。投資判断を行う前に、常に独立した専門家の助言を求めるべきです。Gateおよび/またはGate Venturesは、制限された地域で一部またはすべてのサービスを制限または禁止する場合があります。詳細については、適用されるユーザー契約をお読みください。
Gate Venturesについて
Gate Venturesは、分散型インフラ、エコシステム、アプリケーションへの投資に焦点を当てたGateのベンチャーキャピタル部門であり、Web 3.0時代に世界を再形成する技術に取り組んでいます。Gate Venturesは、革新的な思考と能力を持つチームやスタートアップを支援するために、グローバルな業界リーダーと協力しています。
ウェブサイト: https://www.gate.com/ventures
共有
内容

