オリジナルソース: AIGCオープンコミュニティ 画像ソース:無制限のAIによって生成長いテキストのシナリオでは、ChatGPT などの大規模な言語モデルは、多くの場合、コンピューティング能力のコストが高くなり、待機時間が長くなり、パフォーマンスが低下します。 これら 3 つの課題を解決するために、マイクロソフトは LongLLMLinga をオープンソース化しました。LongLLMLinguaのコア技術原則は、「テキストプロンプト」の最大20倍の制限圧縮を達成すると同時に、プロンプト内のコンテンツの問題への関連性を正確に評価し、無関係なコンテンツを排除し、重要な情報を保持し、コストを削減し、効率を高めるという目的を達成できることが報告されています。実験結果から、LongLLMLinguaで圧縮された**プロンプトのパフォーマンスは、元のプロンプトよりも17.1%向上し、GPT-3.5-Turboに入力されたトークンは4倍**削減されました。 LongBenchとZeroScrollsのテストでは、1,000サンプルあたり28.5ドルと27.4ドルのコスト削減が示されました。約10kトークンのヒントが圧縮され、圧縮率が2〜10倍の範囲にある場合、エンドツーエンドのレイテンシーを1.4〜3.8倍短縮でき、推論速度を大幅に加速できます。論文住所:オープンソースアドレス:入門論文から、LongLLMLinguaは主に4つのモジュールで構成されています:問題認識の粗い細粒度の圧縮、ドキュメントの並べ替え、動的圧縮率、圧縮後のサブシーケンスの回復。 ## **問題認識型の粒度の粗い圧縮モジュール** このモジュールのアイデアは、質問テキストを条件付きで使用し、各段落が質問にどの程度関連しているかを評価し、より関連性の高い段落を保持することです。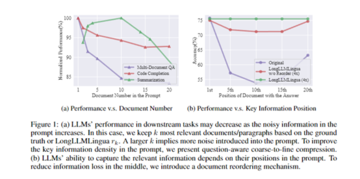 具体的には、問題文と各段落の条件付き混同度を算出することにより、両者の論理的な相関度合いを判断し、条件混同度が低いほど関連性が高くなる。これに基づいて、混乱の少ない段落を維持するためのしきい値を設定し、問題に関係のない段落を除外します。 これにより、粒度の粗い圧縮により、問題に基づいて大量の冗長情報をすばやく削除できます。 ## **ドキュメント並べ替えモジュール** 調査によると、プロンプトの中で、開始位置と終了位置に近いコンテンツが言語モデルに最も大きな影響を与えることが示されています。 したがって、モジュールは関連性に応じて各段落を並べ替えるため、重要な情報がモデルに対してより機密性の高い位置に表示され、中間位置の情報の損失が減少します。粒度の粗い圧縮モジュールを使用して、問題に対する各段落の関連性を計算することにより、関連性が最も高い段落が最初にランク付けされるように段落が並べ替えられます。 これにより、重要な情報に対するモデルの認識がさらに向上します。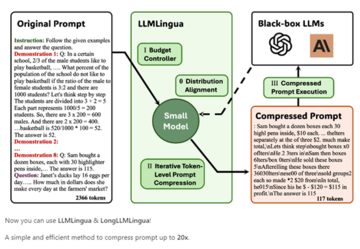 並べ替えられた関連段落を取得した後、各段落内の単語量をさらに圧縮する必要があります。 この時点で、動的圧縮率モジュールはプロンプトを微調整します。 ## **動的圧縮比モジュール** 関連性の高い段落には低い圧縮率を使用し、予約語にはより多くの予算を割り当て、関連性の低い段落には高い圧縮率を使用します。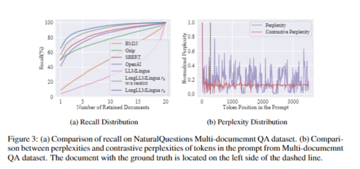 各段落の圧縮率は、粗粒度の圧縮結果の段落の結合率を利用して動的に決定されます。 最も関連性の高い段落の圧縮率が最も低くなります。適応性のあるきめ細かな圧縮制御を実現し、重要な情報を効果的に保持します。 圧縮後、結果の信頼性を向上させる必要もあり、これには以下の圧縮された部分配列回復モジュールが必要である。 ## **圧縮後のサブシーケンス回復モジュール** 圧縮プロセス中に、一部のキーワードが過度に削除され、情報の整合性に影響を与える可能性があり、モジュールはこれらのキーワードを検出して復元できます。動作原理は、ソーステキスト、圧縮テキスト、および生成されたテキストの間のサブシーケンス関係を使用して、生成された結果から完全なキー名詞句を回復し、圧縮によってもたらされる情報の不足を修復し、結果の精度を向上させることです。 全体のプロセスは、記事をすばやく閲覧したり、情報をふるいにかけたり、重要なポイントを統合したりするワークフローに少し似ているため、モデルはテキストの重要な情報をすばやくキャプチャし、高品質の要約を生成します。 ## **LongLLMLingua 実験データ** 研究者は、自然な質問に基づいて複数文書の質問と回答のデータセットを構築し、各例には質問と回答が必要な20の関連文書が含まれていました。このデータセットは、実際の検索エンジンと Q&A シナリオをシミュレートして、長いドキュメント内のモデルの Q&A パフォーマンスを評価します。さらに、研究者は、LongBenchやZeroSCROLLSなどのより一般的なロングテキスト理解ベンチマークのセットを使用して、より幅広いシナリオでのメソッドの有効性を評価しました。その中で、LongBenchは、単一文書のQ&A、複数文書のQ&A、テキストの要約、英語のデータセットを含む少数のサンプル学習などのタスクをカバーしています。 ZeroSCROLLSには、テキストの要約、質問応答の理解、感情分析などの一般的な言語理解タスクが含まれています。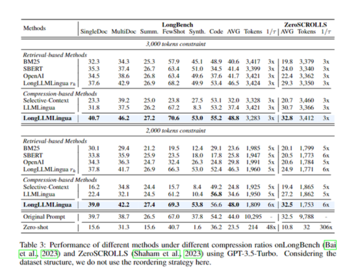 これらのデータセットで、研究者はLongLLMLingaの圧縮プロンプトのパフォーマンスを、大規模な言語モデルでの元のプロンプトと比較しました。 同時に,LongLLMLinguaの有効性を,パズルベースのLLMLinguaや検索ベースの方法など,他のプロンプト圧縮手法との比較により評価した.実験結果は、LongLLMLinguaの圧縮プロンプトが、Q&Aの精度と生成されたテキスト品質の点で、一般的に元のプロンプトよりも優れていることを示しています。たとえば、NaturalQuestionsでは、プロンプトを4倍圧縮すると、Q&Aの精度が17.1%向上しました。 約10kトークンのヒントを圧縮する場合、圧縮率は2〜10倍の範囲であり、エンドツーエンドの遅延を1.4〜3.8倍削減できます。 これは、LongLLMLinguaがヒントを圧縮しながら重要な情報の抽出を改善できることを完全に証明しています。


最大20回まで! ChatGPTなどのモデルテキストプロンプトを圧縮して、AIコンピューティングパワーを大幅に節約します
オリジナルソース: AIGCオープンコミュニティ
長いテキストのシナリオでは、ChatGPT などの大規模な言語モデルは、多くの場合、コンピューティング能力のコストが高くなり、待機時間が長くなり、パフォーマンスが低下します。 これら 3 つの課題を解決するために、マイクロソフトは LongLLMLinga をオープンソース化しました。
LongLLMLinguaのコア技術原則は、「テキストプロンプト」の最大20倍の制限圧縮を達成すると同時に、プロンプト内のコンテンツの問題への関連性を正確に評価し、無関係なコンテンツを排除し、重要な情報を保持し、コストを削減し、効率を高めるという目的を達成できることが報告されています。
実験結果から、LongLLMLinguaで圧縮されたプロンプトのパフォーマンスは、元のプロンプトよりも17.1%向上し、GPT-3.5-Turboに入力されたトークンは4倍削減されました。 LongBenchとZeroScrollsのテストでは、1,000サンプルあたり28.5ドルと27.4ドルのコスト削減が示されました。
約10kトークンのヒントが圧縮され、圧縮率が2〜10倍の範囲にある場合、エンドツーエンドのレイテンシーを1.4〜3.8倍短縮でき、推論速度を大幅に加速できます。
論文住所:
オープンソースアドレス:
入門論文から、LongLLMLinguaは主に4つのモジュールで構成されています:問題認識の粗い細粒度の圧縮、ドキュメントの並べ替え、動的圧縮率、圧縮後のサブシーケンスの回復。
問題認識型の粒度の粗い圧縮モジュール
このモジュールのアイデアは、質問テキストを条件付きで使用し、各段落が質問にどの程度関連しているかを評価し、より関連性の高い段落を保持することです。
これに基づいて、混乱の少ない段落を維持するためのしきい値を設定し、問題に関係のない段落を除外します。 これにより、粒度の粗い圧縮により、問題に基づいて大量の冗長情報をすばやく削除できます。
ドキュメント並べ替えモジュール
調査によると、プロンプトの中で、開始位置と終了位置に近いコンテンツが言語モデルに最も大きな影響を与えることが示されています。 したがって、モジュールは関連性に応じて各段落を並べ替えるため、重要な情報がモデルに対してより機密性の高い位置に表示され、中間位置の情報の損失が減少します。
粒度の粗い圧縮モジュールを使用して、問題に対する各段落の関連性を計算することにより、関連性が最も高い段落が最初にランク付けされるように段落が並べ替えられます。 これにより、重要な情報に対するモデルの認識がさらに向上します。
動的圧縮比モジュール
関連性の高い段落には低い圧縮率を使用し、予約語にはより多くの予算を割り当て、関連性の低い段落には高い圧縮率を使用します。
適応性のあるきめ細かな圧縮制御を実現し、重要な情報を効果的に保持します。 圧縮後、結果の信頼性を向上させる必要もあり、これには以下の圧縮された部分配列回復モジュールが必要である。
圧縮後のサブシーケンス回復モジュール
圧縮プロセス中に、一部のキーワードが過度に削除され、情報の整合性に影響を与える可能性があり、モジュールはこれらのキーワードを検出して復元できます。
動作原理は、ソーステキスト、圧縮テキスト、および生成されたテキストの間のサブシーケンス関係を使用して、生成された結果から完全なキー名詞句を回復し、圧縮によってもたらされる情報の不足を修復し、結果の精度を向上させることです。
LongLLMLingua 実験データ
研究者は、自然な質問に基づいて複数文書の質問と回答のデータセットを構築し、各例には質問と回答が必要な20の関連文書が含まれていました。
このデータセットは、実際の検索エンジンと Q&A シナリオをシミュレートして、長いドキュメント内のモデルの Q&A パフォーマンスを評価します。
さらに、研究者は、LongBenchやZeroSCROLLSなどのより一般的なロングテキスト理解ベンチマークのセットを使用して、より幅広いシナリオでのメソッドの有効性を評価しました。
その中で、LongBenchは、単一文書のQ&A、複数文書のQ&A、テキストの要約、英語のデータセットを含む少数のサンプル学習などのタスクをカバーしています。 ZeroSCROLLSには、テキストの要約、質問応答の理解、感情分析などの一般的な言語理解タスクが含まれています。
実験結果は、LongLLMLinguaの圧縮プロンプトが、Q&Aの精度と生成されたテキスト品質の点で、一般的に元のプロンプトよりも優れていることを示しています。
たとえば、NaturalQuestionsでは、プロンプトを4倍圧縮すると、Q&Aの精度が17.1%向上しました。 約10kトークンのヒントを圧縮する場合、圧縮率は2〜10倍の範囲であり、エンドツーエンドの遅延を1.4〜3.8倍削減できます。 これは、LongLLMLinguaがヒントを圧縮しながら重要な情報の抽出を改善できることを完全に証明しています。