元のソース: マシンの心臓部 画像ソース:無制限のAIによって生成OpenAI ChatGPT Plusサブスクリプションは強力で、日常生活の重要な生産性ツールとして使用できる高度な「高度なデータ分析」、「プラグイン」、「Bingで閲覧」を実装できます。 ただし、商業上の理由から、クローズドソースが選択されており、研究者や開発者は、調査や改善を行う手段なしでのみ使用できます。これに基づき、香港大学、XLang Lab、Sea AI Lab、Salesforceの研究者は、研究者から開発者、ユーザーまで、すべての人のニーズを満たすために、実際の生産性ツール用のオープンソースエージェントフレームワークであるOpenAgentsと、オープンソースのフルスタックコード(完全なフロントエンド、バックエンド、研究コード)を共同で作成しました。OpenAgentsは、ChatGPT Plusの機能を「ビッグランゲージモデル」(LLM)とフルスタックエンジニアリングコードに基づくテクノロジーで近似しようとします。 エージェントは、Python / SQLコードを実行し、ツールを巧みに呼び出し、研究コードの実装からバックエンドのフロントエンドに至るまで、インターネット上の地図や投稿を見つけることができ、誰もが使用できるランディングレベルのアプリケーションになります。 OpenAgentsは、採用しているテクノロジーと遭遇する困難を完全に開示し、科学研究からロジックコード、フロントエンドコードまですべてをカバーするコードを完全にオープンソース化します。 コードは完璧で拡張が簡単で、ワンクリックでローカルに直接デプロイでき、豊富なユースケースを含むサポートドキュメントが提供され、研究者や開発者がモデル上に独自のエージェントやアプリケーションを構築するのに役立ちます。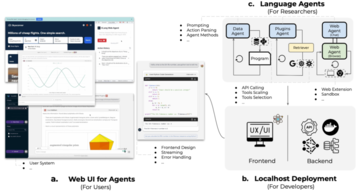 *OpenAgents の概要マップ、ユーザー向け Web インターフェイス、開発者向けのローカル展開、研究者向けの言語エージェント。 * * コードリンク:* 論文リンク:*デモリンク:* ドキュメントリンク:**ChatGPT Plusと同じ」および「同じではない」左側はOpenAgentsの実装で、右側はChatGPT Plusです。 「データ分析」機能を見てみましょう。 株価を分析するという同じタスクで、OpenAgentsとChatGPTは、株価と取引に対するユーザーの要件を分析するのに良い仕事をすることができます。 OpenAgents は Kaggle データセットを自動的に検索してダウンロードできますが、ChatGPT ではユーザーがローカルにアップロードする必要があります。 OpenAIの最も初期の「プラグイン」機能をお試しください。 ユーザは八面体を描きたいと思い,どちらもWolframプラグインを呼び出して複数の八面体の絵を描くことに成功しました. 最後に、「Webブラウジング」をご覧ください。 ユーザーが10月20日に香港からニューヨークへの航空券を確認したい場合、OpenAgentsはユーザーの意図を認識してSkycannerに直接ジャンプし、Webサイトに情報を入力しながら「実在の人物」のように考え、最後にチャットページに戻って情報を要約します。 ChatGPTは、プラグインの呼び出し、クラウドでのWebブラウジング、最後に検索された情報を返すのと同様に、制御性を確保するためのセキュリティを備えています。OpenAgentsはオープンソースコードを提供するため、開発者や研究者は、カスタマイズしたり、数行のコードを目的のモデルに適合させたり、改善したり、必要な機能を作成したり、新しいエージェントを作成したりすることができます。 これは、この方向でのさらなる開発と研究に不可欠です。**簡単に思えますが、なぜ「生産性に使える」エージェントがこれほど多くのピットを踏むのですか? **エージェントには多くのオープンソースフレームワークがあり、大規模なモデルに基づくミドルウェアが無限の流れで出現しているため、他のエージェントフレームワークと比較して、本当に便利で使いやすいエージェントであるOpenAgentsを構築するのは簡単ではありません。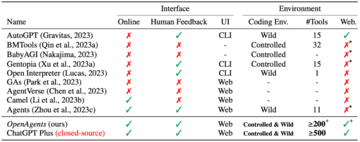 * OpenAgents を他のフレームワークと比較する。 *表からわかるように、「インターフェイス」と「環境」はOpenAgentsを際立たせる2つのものです。 LangChain、AutoGPT、BabyAGIなどの既存のオープンソースフレームワークは、開発者に初期の概念実証実装とコンソールインターフェイスを提供するように設計されていますが、現実の世界では十分に堅牢ではなく、より多くの聴衆、特にプログラミングやコンソールに精通していないユーザーへのアクセスを制限します。 クローズドソースアーキテクチャでは、OpenAIはChatGPT Plusに適切に設計された製品、特に高度なデータ分析(以前はコードインタープリターと呼ばれていました)、プラグイン、Bingブラウジングなどの機能を展開し、さらにトレーニングされたモデル、ビジネスロジックコード、育成されたソフトウェアコミュニティ(プラグインストアなど)を活用します。 しかし、クローズドソースはそれらを開発および研究プラットフォームとして使用することを困難にし、コミュニティは巨人の肩の上に立って調査、評価、および改善することはできません。 これらの側面に焦点を当てた後、OpenAgentsは、実際のシナリオのためのオープンソースエージェントフレームワークとして、ChatGPT Plusと競合できるプラットフォームをコミュニティに提供します。「インターフェイス」では、OpenAgentsはオンラインWebページのデモ(およびオープンソースコードのサポート)を提供し、プログラマー以外のバックグラウンドを持つ一般ユーザーはエージェントと簡単に対話できますが、以前の作業は通常、「コンソールコマンドインターフェイス」(CLI)の形式で対話を提供または提供しないため、エージェントの使用のしきい値が大幅に引き上げられます。 「サポート環境」では、OpenAgentsは現実世界の制御可能な環境をサポートし、毎日200 +以上のツールコールをサポートし、自動Webブラウジングをサポートします。これらの機能は、OpenAgents を一般ユーザーにとって選択の障壁として最小限に抑え、装備します。 また、研究や開発者などに、おそらく最良の直接ユーザーの機会を提供します。 ## ** 生産性エージェントの未来の第一歩として:「ユーザー」「開発者」「研究者」が利用できるエージェントプラットフォーム** 上記の問題に対処するために、OpenAgentsは、現在3つの主要なエージェントを含むエージェントの使用と展開のためのオープンソースプラットフォームとして機能するように動機付けられています。* Python および SQL 用のデータエージェント。* 200以上のツールで使用されるプラグインエージェント。*自動WebブラウジングのためのWebエージェント。OpenAgentsは、大規模な言語モデルがその潜在能力を最大限に発揮するためには、純粋に理論的または開発者指向のツールから、幅広いユーザーベース向けの動的でインタラクティブなシステムに変換する必要があると考えています。 「一般ユーザー」は、コーディングの専門知識がなくても、オンラインWeb UIを介してエージェント機能を簡単に探索できます。 さらに、OpenAgentsは「開発者」に完全なビジネスロジックとリサーチコードを提供し、ローカルに簡単にデプロイでき、「研究者」は言語エージェントをさらに構築できます。 最後に、OpenAgentsは、人間と対話できるエージェントを評価するための現実的で包括的なプラットフォームを目指しています:実際のニーズに基づいて、実際のユーザーはエージェントと対話してタスクを完了し、ユーザーとエージェントの対話プロセス全体とユーザーフィードバックを記録してさらに評価します。 既存のベンチマークやプラットフォームと比較して、OpenAgentsは、エージェントがさまざまな実際のユーザーのニーズを満たすことができる実際の環境を提供します。 ## **直面する課題と克服する課題** **課題1:ヒントに基づいて実世界言語モデルを構築することのデメリット**実際のユーザー向けのプロンプトベースのアプリケーションを構築する場合は、プロンプトの指示に従って特定の要件を設定します。 これらの命令はさまざまな目的を果たしますが、大規模な言語モデルの出力がバックエンドロジックによって処理される特定の形式(特定のキーのディクショナリとして出力)に準拠していることを確認するためのものもあります。 いくつかは、出力の美学を改善することです(アイテムを可能な限り1つずつ個別にリストします)。 一部は、潜在的な攻撃を防ぐために使用されます(悪意を持って構築されたプログラムの無限ループをユーザーに拒否して実行します)。言語モデルを制約する制約目的のプロンプトを伴うこれらの制約は、開発者と研究者がいくつかの使用可能な命令を繰り返しデバッグする必要があり、それらは通常数百の「トークン」または数千のトークンであり、これらの命令はプレフィックスとしてモデルに繰り返し入力され、グラフィックカードリソースを大量に消費します。 一方、トークンが多いほど、LLMへの依存度が高くなり、パフォーマンスが向上するため、この技術ルートでは、大規模な言語モデルの命令追跡機能とサポートされるコンテキスト長に特定の要件が提示されます。現在のオープンソースモデルはこれらの分野で大幅な改善を行っていますが、実験での実用化にはまだ十分ではなく、この方向での研究は継続できます。 さらに、エージェントモデルの基礎開発と研究、および特定のドメインと要件専用のエージェントモデルのトレーニングにさらに注意を払う必要があります。 このアプローチは、遺伝的に強力であるが固定されたモデルのプロンプトだけに依存するよりも効率的で制御しやすい場合があります。課題2:制御不能な現実実世界の言語インテリジェンスを実装するには、ユーザーの行動、インターネットのインフラストラクチャ、ビジネスロジックなど、過去の研究では適切にモデル化されていない多くの制御不能な現実世界の要因に直面する必要があります。 これには、過去の研究で使用された多くの仮定と方法を再評価し、さらには覆す必要があります。 考慮すべきことの1つは、APIが呼び出されているサーバーがクラッシュする可能性があることです。 この状況では、過去のツール使用調査で仮定されているように、ユーザーコマンドを監視して着実に完了する必要があります。 ユーザーは、応答の生成プロセス中に不満を感じる可能性があり、生成プロセス中に言語モデルが中断される可能性があります。さらに、CAPTCHAポップアップやWebページへの広告変更などの予測不可能なイベントは、Webブラウジングを自動化するための以前の取り組みでは考慮されていなかった、比較的安定したWebページ構造にある程度のランダム性をもたらす可能性があります。 エージェントが反応して考えるのにかかる時間(今では数秒かかることが多い)で環境が変化するなど、このような問題は他にもたくさんあります。課題 3: 実際のシナリオからの追加メトリック**特定の研究では、多くの場合、パフォーマンス メトリックに重点が置かれすぎ、実際のシナリオでの基本的なニーズが無視されます。 たとえば、生成された各トークンができるだけ早くユーザーに表示されるストリーミングを使用すると、ユーザーは長いテキストが生成されるのを待たずにシステムからのフィードバックをすばやく感知してから一緒に見ることができます。 特別に設計されたプロンプトは、エージェントの応答形式をより美しくすることができ、ユーザーエクスペリエンスに大きな影響を与えます。 しかし、既存の方法では、これらの影響を十分に考慮していません。 その結果、精度のパフォーマンス指標は優れていますが、実際には、応答時間が長く、テキストの読みやすさが低く、ユーザーエクスペリエンスの低下につながるその他の問題につながる可能性があり、次の研究では、パフォーマンスとユーザーエクスペリエンスのトレードオフをさらに検討する必要があります。**課題 4: システムの問題による評価の複雑さ**アプリケーション固有のエージェントを直接構築することで、より多くのユーザーニーズを満たすと同時に、より多くの評価上の課題を明らかにすることができます。 ただし、LLMベースのアプリケーション構築では複雑さが増し、障害ケースがLLMアプリケーションの制限によるものなのか、ロジックコードの不十分なものなのかを判断するのが難しくなります。 たとえば、ユーザーがアップロードされたファイルをインターフェイスから直接ドラッグアンドドロップできず、ユーザーが望む操作を完了できないため、エージェントの能力を判断するのは不合理です。 したがって、エージェントの設計と運用ロジックのシステムを改善し、エージェントプロセスとユーザー使用ロジックを簡素化するか、より完全な設計と実装ロジックを構築することが有望であり、必要です。 ## **今後の展望** OpenAgents は、研究開発の次のステップでコミュニティをどのように支援できますか? 彼らのビジョンには、少なくとも次のものがあります。**今後の作業 1: エージェント アプリケーションの追加**OpenAgents は、完全なアプリケーション・レベルの言語エージェント開発プロセスと必要なテクノロジーを開き、コードを開きます。 これにより、他の革新的なアプリケーションやエンドユーザーの可能性が開かれます。 開発者は、マルチモーダルダイアログ、音声ダイアログ、ライブラリレベルのコードアシスタントなど、必要な新しいアプリケーションを構築できます。**仕事の未来2:ツールとコンポーネントの統合**OpenAgents は、ユーティリティグレードのエージェントアプリケーションを構築するための基本的なニーズを調査して対処し、他のコンポーネントを統合することでコミュニティが水平方向に簡単に拡張するための強力な基盤を提供します。 同時に、最近の大規模なマルチモーダルモデルなど、より基本的なモデルを拡張して、新しいUIデザインに適合させることができます。**仕事の未来3:ヒューマンコンピュータインタラクション分野の研究**OpenAgentsプラットフォームに基づいて、開発者や研究者は大規模な言語モデルに基づいて新しいエージェントアプリケーションを簡単に構築できます。 したがって、OpenAgentsは、ヒューマンコンピュータインタラクション(HCI)研究者が、より直感的でユーザーフレンドリーなインターフェース設計を掘り下げるためのアプリケーションデモを構築するのに役立ちます。 これにより、ユーザーのエンゲージメントと満足度が向上します。**今後の作業4:適応型ユーザーインターフェイスの生成**ユーザーインターフェイスの作成を自動化することは、興味深く挑戦的な分野です。 これらのインターフェイスは、ユーザーのデバイス、設定、コンテキストなどの特定の基準に基づいて、自己適合またはカスタマイズできます。 研究者は、OpenAgentsベースの適応型UIで大きな言語モデルがどのように適用されるか、そしてそれらがユーザーエクスペリエンスに与える影響を掘り下げることができます。**今後の課題5:実世界のアプリケーションシナリオにおける大きな言語モデルの評価**大規模言語モデルの能力と性能を公正に評価するためには、大規模言語モデルの公平で堅牢な評価手法を確立することが不可欠です。 現在、エージェントは事前に収集されたデータと制御された環境を使用してベンチマークされています。 これらの評価は重要ですが、多くの場合、現実世界の動的な課題を完全には反映していません。 これらの評価指標とプラットフォームを拡張または改良するようコミュニティに奨励することで、この分野が大幅に進歩し、大規模な言語モデルの実際のパフォーマンスと機能に関するより正確な評価と洞察が提供されます。


「ChatGPT Plus」のオープンソース版が登場し、データ分析、プラグイン呼び出し、自動インターネットアクセス、および実際のエージェントの着陸を行うことができます
元のソース: マシンの心臓部
OpenAI ChatGPT Plusサブスクリプションは強力で、日常生活の重要な生産性ツールとして使用できる高度な「高度なデータ分析」、「プラグイン」、「Bingで閲覧」を実装できます。 ただし、商業上の理由から、クローズドソースが選択されており、研究者や開発者は、調査や改善を行う手段なしでのみ使用できます。
これに基づき、香港大学、XLang Lab、Sea AI Lab、Salesforceの研究者は、研究者から開発者、ユーザーまで、すべての人のニーズを満たすために、実際の生産性ツール用のオープンソースエージェントフレームワークであるOpenAgentsと、オープンソースのフルスタックコード(完全なフロントエンド、バックエンド、研究コード)を共同で作成しました。
OpenAgentsは、ChatGPT Plusの機能を「ビッグランゲージモデル」(LLM)とフルスタックエンジニアリングコードに基づくテクノロジーで近似しようとします。 エージェントは、Python / SQLコードを実行し、ツールを巧みに呼び出し、研究コードの実装からバックエンドのフロントエンドに至るまで、インターネット上の地図や投稿を見つけることができ、誰もが使用できるランディングレベルのアプリケーションになります。 OpenAgentsは、採用しているテクノロジーと遭遇する困難を完全に開示し、科学研究からロジックコード、フロントエンドコードまですべてをカバーするコードを完全にオープンソース化します。 コードは完璧で拡張が簡単で、ワンクリックでローカルに直接デプロイでき、豊富なユースケースを含むサポートドキュメントが提供され、研究者や開発者がモデル上に独自のエージェントやアプリケーションを構築するのに役立ちます。
**ChatGPT Plusと同じ」および「同じではない」
左側はOpenAgentsの実装で、右側はChatGPT Plusです。
OpenAgentsはオープンソースコードを提供するため、開発者や研究者は、カスタマイズしたり、数行のコードを目的のモデルに適合させたり、改善したり、必要な機能を作成したり、新しいエージェントを作成したりすることができます。 これは、この方向でのさらなる開発と研究に不可欠です。
**簡単に思えますが、なぜ「生産性に使える」エージェントがこれほど多くのピットを踏むのですか? **
エージェントには多くのオープンソースフレームワークがあり、大規模なモデルに基づくミドルウェアが無限の流れで出現しているため、他のエージェントフレームワークと比較して、本当に便利で使いやすいエージェントであるOpenAgentsを構築するのは簡単ではありません。
表からわかるように、「インターフェイス」と「環境」はOpenAgentsを際立たせる2つのものです。 LangChain、AutoGPT、BabyAGIなどの既存のオープンソースフレームワークは、開発者に初期の概念実証実装とコンソールインターフェイスを提供するように設計されていますが、現実の世界では十分に堅牢ではなく、より多くの聴衆、特にプログラミングやコンソールに精通していないユーザーへのアクセスを制限します。 クローズドソースアーキテクチャでは、OpenAIはChatGPT Plusに適切に設計された製品、特に高度なデータ分析(以前はコードインタープリターと呼ばれていました)、プラグイン、Bingブラウジングなどの機能を展開し、さらにトレーニングされたモデル、ビジネスロジックコード、育成されたソフトウェアコミュニティ(プラグインストアなど)を活用します。 しかし、クローズドソースはそれらを開発および研究プラットフォームとして使用することを困難にし、コミュニティは巨人の肩の上に立って調査、評価、および改善することはできません。 これらの側面に焦点を当てた後、OpenAgentsは、実際のシナリオのためのオープンソースエージェントフレームワークとして、ChatGPT Plusと競合できるプラットフォームをコミュニティに提供します。
「インターフェイス」では、OpenAgentsはオンラインWebページのデモ(およびオープンソースコードのサポート)を提供し、プログラマー以外のバックグラウンドを持つ一般ユーザーはエージェントと簡単に対話できますが、以前の作業は通常、「コンソールコマンドインターフェイス」(CLI)の形式で対話を提供または提供しないため、エージェントの使用のしきい値が大幅に引き上げられます。 「サポート環境」では、OpenAgentsは現実世界の制御可能な環境をサポートし、毎日200 +以上のツールコールをサポートし、自動Webブラウジングをサポートします。
これらの機能は、OpenAgents を一般ユーザーにとって選択の障壁として最小限に抑え、装備します。 また、研究や開発者などに、おそらく最良の直接ユーザーの機会を提供します。
** 生産性エージェントの未来の第一歩として:「ユーザー」「開発者」「研究者」が利用できるエージェントプラットフォーム**
上記の問題に対処するために、OpenAgentsは、現在3つの主要なエージェントを含むエージェントの使用と展開のためのオープンソースプラットフォームとして機能するように動機付けられています。
OpenAgentsは、大規模な言語モデルがその潜在能力を最大限に発揮するためには、純粋に理論的または開発者指向のツールから、幅広いユーザーベース向けの動的でインタラクティブなシステムに変換する必要があると考えています。 「一般ユーザー」は、コーディングの専門知識がなくても、オンラインWeb UIを介してエージェント機能を簡単に探索できます。 さらに、OpenAgentsは「開発者」に完全なビジネスロジックとリサーチコードを提供し、ローカルに簡単にデプロイでき、「研究者」は言語エージェントをさらに構築できます。 最後に、OpenAgentsは、人間と対話できるエージェントを評価するための現実的で包括的なプラットフォームを目指しています:実際のニーズに基づいて、実際のユーザーはエージェントと対話してタスクを完了し、ユーザーとエージェントの対話プロセス全体とユーザーフィードバックを記録してさらに評価します。 既存のベンチマークやプラットフォームと比較して、OpenAgentsは、エージェントがさまざまな実際のユーザーのニーズを満たすことができる実際の環境を提供します。
直面する課題と克服する課題
課題1:ヒントに基づいて実世界言語モデルを構築することのデメリット
実際のユーザー向けのプロンプトベースのアプリケーションを構築する場合は、プロンプトの指示に従って特定の要件を設定します。 これらの命令はさまざまな目的を果たしますが、大規模な言語モデルの出力がバックエンドロジックによって処理される特定の形式(特定のキーのディクショナリとして出力)に準拠していることを確認するためのものもあります。 いくつかは、出力の美学を改善することです(アイテムを可能な限り1つずつ個別にリストします)。 一部は、潜在的な攻撃を防ぐために使用されます(悪意を持って構築されたプログラムの無限ループをユーザーに拒否して実行します)。
言語モデルを制約する制約目的のプロンプトを伴うこれらの制約は、開発者と研究者がいくつかの使用可能な命令を繰り返しデバッグする必要があり、それらは通常数百の「トークン」または数千のトークンであり、これらの命令はプレフィックスとしてモデルに繰り返し入力され、グラフィックカードリソースを大量に消費します。 一方、トークンが多いほど、LLMへの依存度が高くなり、パフォーマンスが向上するため、この技術ルートでは、大規模な言語モデルの命令追跡機能とサポートされるコンテキスト長に特定の要件が提示されます。
現在のオープンソースモデルはこれらの分野で大幅な改善を行っていますが、実験での実用化にはまだ十分ではなく、この方向での研究は継続できます。 さらに、エージェントモデルの基礎開発と研究、および特定のドメインと要件専用のエージェントモデルのトレーニングにさらに注意を払う必要があります。 このアプローチは、遺伝的に強力であるが固定されたモデルのプロンプトだけに依存するよりも効率的で制御しやすい場合があります。
課題2:制御不能な現実
実世界の言語インテリジェンスを実装するには、ユーザーの行動、インターネットのインフラストラクチャ、ビジネスロジックなど、過去の研究では適切にモデル化されていない多くの制御不能な現実世界の要因に直面する必要があります。 これには、過去の研究で使用された多くの仮定と方法を再評価し、さらには覆す必要があります。 考慮すべきことの1つは、APIが呼び出されているサーバーがクラッシュする可能性があることです。 この状況では、過去のツール使用調査で仮定されているように、ユーザーコマンドを監視して着実に完了する必要があります。 ユーザーは、応答の生成プロセス中に不満を感じる可能性があり、生成プロセス中に言語モデルが中断される可能性があります。
さらに、CAPTCHAポップアップやWebページへの広告変更などの予測不可能なイベントは、Webブラウジングを自動化するための以前の取り組みでは考慮されていなかった、比較的安定したWebページ構造にある程度のランダム性をもたらす可能性があります。 エージェントが反応して考えるのにかかる時間(今では数秒かかることが多い)で環境が変化するなど、このような問題は他にもたくさんあります。
課題 3: 実際のシナリオからの追加メトリック**
特定の研究では、多くの場合、パフォーマンス メトリックに重点が置かれすぎ、実際のシナリオでの基本的なニーズが無視されます。 たとえば、生成された各トークンができるだけ早くユーザーに表示されるストリーミングを使用すると、ユーザーは長いテキストが生成されるのを待たずにシステムからのフィードバックをすばやく感知してから一緒に見ることができます。 特別に設計されたプロンプトは、エージェントの応答形式をより美しくすることができ、ユーザーエクスペリエンスに大きな影響を与えます。 しかし、既存の方法では、これらの影響を十分に考慮していません。 その結果、精度のパフォーマンス指標は優れていますが、実際には、応答時間が長く、テキストの読みやすさが低く、ユーザーエクスペリエンスの低下につながるその他の問題につながる可能性があり、次の研究では、パフォーマンスとユーザーエクスペリエンスのトレードオフをさらに検討する必要があります。
課題 4: システムの問題による評価の複雑さ
アプリケーション固有のエージェントを直接構築することで、より多くのユーザーニーズを満たすと同時に、より多くの評価上の課題を明らかにすることができます。 ただし、LLMベースのアプリケーション構築では複雑さが増し、障害ケースがLLMアプリケーションの制限によるものなのか、ロジックコードの不十分なものなのかを判断するのが難しくなります。 たとえば、ユーザーがアップロードされたファイルをインターフェイスから直接ドラッグアンドドロップできず、ユーザーが望む操作を完了できないため、エージェントの能力を判断するのは不合理です。 したがって、エージェントの設計と運用ロジックのシステムを改善し、エージェントプロセスとユーザー使用ロジックを簡素化するか、より完全な設計と実装ロジックを構築することが有望であり、必要です。
今後の展望
OpenAgents は、研究開発の次のステップでコミュニティをどのように支援できますか? 彼らのビジョンには、少なくとも次のものがあります。
今後の作業 1: エージェント アプリケーションの追加
OpenAgents は、完全なアプリケーション・レベルの言語エージェント開発プロセスと必要なテクノロジーを開き、コードを開きます。 これにより、他の革新的なアプリケーションやエンドユーザーの可能性が開かれます。 開発者は、マルチモーダルダイアログ、音声ダイアログ、ライブラリレベルのコードアシスタントなど、必要な新しいアプリケーションを構築できます。
仕事の未来2:ツールとコンポーネントの統合
OpenAgents は、ユーティリティグレードのエージェントアプリケーションを構築するための基本的なニーズを調査して対処し、他のコンポーネントを統合することでコミュニティが水平方向に簡単に拡張するための強力な基盤を提供します。 同時に、最近の大規模なマルチモーダルモデルなど、より基本的なモデルを拡張して、新しいUIデザインに適合させることができます。
仕事の未来3:ヒューマンコンピュータインタラクション分野の研究
OpenAgentsプラットフォームに基づいて、開発者や研究者は大規模な言語モデルに基づいて新しいエージェントアプリケーションを簡単に構築できます。 したがって、OpenAgentsは、ヒューマンコンピュータインタラクション(HCI)研究者が、より直感的でユーザーフレンドリーなインターフェース設計を掘り下げるためのアプリケーションデモを構築するのに役立ちます。 これにより、ユーザーのエンゲージメントと満足度が向上します。
今後の作業4:適応型ユーザーインターフェイスの生成
ユーザーインターフェイスの作成を自動化することは、興味深く挑戦的な分野です。 これらのインターフェイスは、ユーザーのデバイス、設定、コンテキストなどの特定の基準に基づいて、自己適合またはカスタマイズできます。 研究者は、OpenAgentsベースの適応型UIで大きな言語モデルがどのように適用されるか、そしてそれらがユーザーエクスペリエンスに与える影響を掘り下げることができます。
今後の課題5:実世界のアプリケーションシナリオにおける大きな言語モデルの評価
大規模言語モデルの能力と性能を公正に評価するためには、大規模言語モデルの公平で堅牢な評価手法を確立することが不可欠です。 現在、エージェントは事前に収集されたデータと制御された環境を使用してベンチマークされています。 これらの評価は重要ですが、多くの場合、現実世界の動的な課題を完全には反映していません。 これらの評価指標とプラットフォームを拡張または改良するようコミュニティに奨励することで、この分野が大幅に進歩し、大規模な言語モデルの実際のパフォーマンスと機能に関するより正確な評価と洞察が提供されます。