元のソース: 量子ビット 画像ソース:無制限のAIによって生成Appleによる最近の研究では、高解像度画像での拡散モデルのパフォーマンスが劇的に向上しました。この方法を使用すると、同じ解像度の画像でトレーニング ステップの数が 70% 以上削減されます。1024×1024の解像度では、画質は直接フルになり、細部がはっきりと見えます。 Appleはこの成果をMDMと名付け、DMは拡散モデルの略で、最初のMはマトリョーシカの略です。本物のマトリョーシカ人形のように、MDMは高解像度プロセスに低解像度プロセスを入れ子にし、複数のレイヤーに入れ子にします。高解像度と低解像度の拡散プロセスが同時に実行されるため、高解像度プロセスにおける従来の拡散モデルのリソース消費が大幅に削減されます。 解像度が256×256の画像の場合、バッチサイズが1024の環境では、従来の拡散モデルでは150万ステップをトレーニングする必要がありますが、MDMでは390,000ステップしか必要とせず、70%以上削減されます。さらに、MDMはエンドツーエンドのトレーニングを採用し、特定のデータセットや事前トレーニング済みモデルに依存せず、高速化しながら生成品質を保証し、柔軟に使用できます。 高解像度の画像を描くことができるだけでなく、16×256²のビデオも作成できます。 一部のネチズンは、Appleが最終的にテキストを画像に接続したとコメントしました。 では、MDMの「マトリョーシカ人形」技術はどのようにそれを行うのでしょうか? ## **ホリスティックとプログレッシブの組み合わせ** 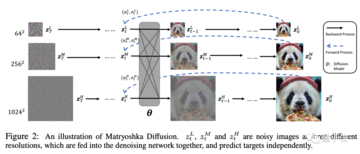 トレーニングを開始する前に、データを前処理する必要があり、高解像度の画像を特定のアルゴリズムでリサンプリングして、さまざまな解像度バージョンを取得します。次に、異なる解像度のこのデータをジョイントUNetモデリングに使用し、小さなUNet処理を低解像度で、大きなUNet処理を高解像度にネストします。クロス解像度接続を使用すると、異なるサイズの UNet 間でフィーチャとパラメーターを共有できます。 MDMトレーニングは段階的なプロセスです。モデリングは共同ですが、トレーニングプロセスは高解像度で開始するのではなく、低解像度から徐々にスケールアップします。これにより、膨大な量の計算が回避され、低解像度のUNetの事前トレーニングが可能になり、高解像度のトレーニングプロセスが高速化されます。トレーニングプロセス中に、高解像度のトレーニングデータがプロセス全体に徐々に追加されるため、モデルは徐々に増加する解像度に適応し、最終的な高解像度プロセスにスムーズに移行できます。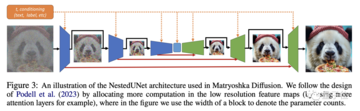 ただし、全体として、高解像度プロセスを徐々に追加した後も、MDMトレーニングはエンドツーエンドの共同プロセスです。異なる解像度での合同トレーニングでは、複数の解像度の損失関数がパラメータの更新に一緒に関与し、多段階トレーニングによって引き起こされるエラーの蓄積を回避します。各解像度には、データ項目の対応する再構成損失があり、異なる解像度の損失は重み付けされてマージされ、その中で低解像度の損失の重みは、生成品質を確保するために大きくなります。推論フェーズでは、MDMは並列戦略とプログレッシブ戦略の組み合わせも採用します。さらに、MDMは事前トレーニング済みの画像分類モデル(CFG)を使用して、生成されたサンプルをより合理的な方向に最適化するように導き、低解像度のサンプルにノイズを追加して高解像度サンプルの分布に近づけます。では、MDMはどのくらい効果的ですか? ## **SOTAに一致するパラメータが少ない** 画像に関しては、ImageNetおよびCC12Mデータセットでは、MDMのFID(値が小さいほど良い)とCLIPのパフォーマンスが通常の拡散モデルよりも大幅に優れています。FIDは画像自体の品質を評価するために使用され、CLIPは画像とテキスト命令の間の一致の程度を表します。 DALL EやIMAGENなどのSOTAモデルと比較すると、MDMのパフォーマンスも近いですが、MDMのトレーニングパラメータはこれらのモデルよりもはるかに劣っています。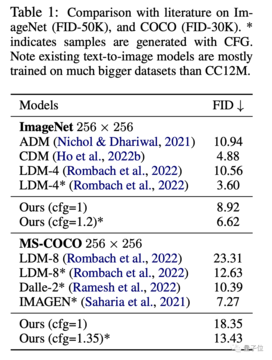 MDMは、通常の拡散モデルよりも優れているだけでなく、他のカスケード拡散モデルよりも優れています。 アブレーション実験の結果は、低解像度トレーニングのステップが多いほど、MDM効果の増強がより明白であることを示しています。 一方、ネストのレベルが高いほど、同じCLIPスコアを達成するために必要なトレーニングステップが少なくなります。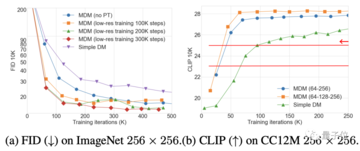 CFGパラメータの選択は、複数のテスト後のFIDとCLIPの間のトレードオフの結果です(CFG強度の増加に比べてCLIPスコアが高い)。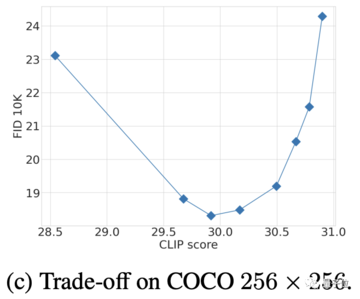 論文住所:


アップルの「マトリョーシカ人形」拡散モデル、トレーニングステップ数が70%削減!
元のソース: 量子ビット
Appleによる最近の研究では、高解像度画像での拡散モデルのパフォーマンスが劇的に向上しました。
この方法を使用すると、同じ解像度の画像でトレーニング ステップの数が 70% 以上削減されます。
1024×1024の解像度では、画質は直接フルになり、細部がはっきりと見えます。
本物のマトリョーシカ人形のように、MDMは高解像度プロセスに低解像度プロセスを入れ子にし、複数のレイヤーに入れ子にします。
高解像度と低解像度の拡散プロセスが同時に実行されるため、高解像度プロセスにおける従来の拡散モデルのリソース消費が大幅に削減されます。
さらに、MDMはエンドツーエンドのトレーニングを採用し、特定のデータセットや事前トレーニング済みモデルに依存せず、高速化しながら生成品質を保証し、柔軟に使用できます。
ホリスティックとプログレッシブの組み合わせ
次に、異なる解像度のこのデータをジョイントUNetモデリングに使用し、小さなUNet処理を低解像度で、大きなUNet処理を高解像度にネストします。
クロス解像度接続を使用すると、異なるサイズの UNet 間でフィーチャとパラメーターを共有できます。
モデリングは共同ですが、トレーニングプロセスは高解像度で開始するのではなく、低解像度から徐々にスケールアップします。
これにより、膨大な量の計算が回避され、低解像度のUNetの事前トレーニングが可能になり、高解像度のトレーニングプロセスが高速化されます。
トレーニングプロセス中に、高解像度のトレーニングデータがプロセス全体に徐々に追加されるため、モデルは徐々に増加する解像度に適応し、最終的な高解像度プロセスにスムーズに移行できます。
異なる解像度での合同トレーニングでは、複数の解像度の損失関数がパラメータの更新に一緒に関与し、多段階トレーニングによって引き起こされるエラーの蓄積を回避します。
各解像度には、データ項目の対応する再構成損失があり、異なる解像度の損失は重み付けされてマージされ、その中で低解像度の損失の重みは、生成品質を確保するために大きくなります。
推論フェーズでは、MDMは並列戦略とプログレッシブ戦略の組み合わせも採用します。
さらに、MDMは事前トレーニング済みの画像分類モデル(CFG)を使用して、生成されたサンプルをより合理的な方向に最適化するように導き、低解像度のサンプルにノイズを追加して高解像度サンプルの分布に近づけます。
では、MDMはどのくらい効果的ですか?
SOTAに一致するパラメータが少ない
画像に関しては、ImageNetおよびCC12Mデータセットでは、MDMのFID(値が小さいほど良い)とCLIPのパフォーマンスが通常の拡散モデルよりも大幅に優れています。
FIDは画像自体の品質を評価するために使用され、CLIPは画像とテキスト命令の間の一致の程度を表します。