> 大型モデルで本を読むのは、かつてないほど速くなりました。 画像ソース: Unbounded AIによって生成国内の大型モデルスタートアップは、テクノロジーの最前線で新記録を創出しています。10 月 30 日、Baichuan Intelligence は、大規模言語モデル (LLM) コンテキスト ウィンドウの長さを **192K トークン** に増やした Baichuan2-192K ロング ウィンドウ ラージ モデルを正式にリリースしました。これは、大規模モデルで一度に約35万文字の漢字を処理することに相当し、GPT-4(32Kトークン、約25,000文字)の14倍、Claude 2.0(100Kトークン、約80,000文字)の4.4倍の長さです。言い換えれば、Baichuan2-192K は Three-Body Problem 2 のコピーを一度に読み取ることができ、世界で最も長い処理コンテキスト ウィンドウを持つ最大のモデルになります。 さらに、テキスト生成品質、文脈理解、Q&A機能など、多面的に競合他社を大幅に上回っています。一度に非常に長いテキストを理解できる大規模なモデルで何ができますか? Baichuan Intelligent は簡単なデモンストレーションを行いました。「三体問題2:暗い森」全体のPDFファイルをアップロードすると、白川モデルは30万語になります。 次に、小説について質問すると、モデルは簡潔で正確な答えを与えることができます。 私たちは、想像力を働かせるのではなく、正確な情報を抽出するために、AIに助けを求めることがあります。 Baichuan2-192Kを使用すると、数十ページまたは数百ページの契約文書をすばやく解読し、AIに簡潔な要約をすばやく提供させることができます。 では、突然新しい課題が出てきて、読みたいファイルが山ほどある場合はどうすればよいでしょうか?直接パッケージ化してアップロードでき、白川モデルは5つのニュース記事を1つに簡単に統合できます。 大きなモデルが理解できる内容が長くなればなるほど、適用される方向がどんどん増えていきます。 ご存知のように、長いテキストをモデル化する機能は、多くのシナリオを適用するための前提条件です。 今回、白川は業界をリードしました。**数万語から数十万語まで、大手スタートアップは「長い窓」をつかもうと急いでいます**テキスト理解の方向で大規模なモデルの適用に注意を払うと、現象に気付くかもしれません:最初に、モデルの能力を評価するために使用されるテキストは、通常数十ページから数十ページの範囲の財務報告書と技術報告書であり、単語数は通常数万語です。 しかし、その後、テストテキストは徐々に数時間の会議時間、または数十万語の小説に発展し、競争はますます激しく困難になりました。 同時に、より長い文脈を理解できると主張する大手モデル企業が勢いを増しています。 例えば、少し前に、100Kトークンのコンテキストウィンドウを実現できると主張したClaudeの背後にある会社であるAnthropicは、MicrosoftとGoogleから数十億ドルの資金提供を受け、大規模なモデルの軍拡競争を新たなレベルに押し上げました。なぜこれらの企業は長文に挑戦しているのでしょうか?まず、アプリケーションの観点から見ると、生産性向上のために大きなモデルを使う多くの労働者は、弁護士、アナリスト、コンサルタントなど、必然的に長い文章を扱わなければならず、コンテキストウィンドウが大きくなればなるほど、これらの人々が大きなモデルでできることの範囲が広がります。 第2に、技術的な観点からは、ウィンドウが保持できる情報が多ければ多いほど、モデルが次の単語を生成する際に参照できる情報が増えれば増えるほど、「幻覚」が起こりにくくなり、情報がより正確になるという、大規模モデル技術の実装に必要な条件となります。 したがって、モデルのパフォーマンスを向上させようとする一方で、企業はコンテキストウィンドウを大きくして、より多くのアプリケーションシナリオに投入できるユーザーを競い合っています。前に示したいくつかの例からわかるように、Baichuan2-192Kはテキスト生成の品質と文脈の理解の両方に優れています。 そして、これらの定性的な結果に加えて、いくつかの定量的な評価データにもそれが見られます。**Baichuan2-192K:ファイルが長いほど、利点はより明白になります**テキスト生成の品質評価において、人間の自然言語の習慣に合致した高品質な文書をテストセットとすると、モデルが中国語版のテストセットを生成する確率が高くなるほど、モデルの混乱は小さくなり、より良いモデルになるという、非常に重要な指標があります。白川大規模モデルのパープレキリティをテストするために使用されるテストセットは、PG-19と呼ばれます。 このデータセットはDeepMindの研究者によって作成され、プロジェクト・グーテンベルクの書籍の資料を使用して作成されたため、PG-19は書籍品質の品質を備えています。テスト結果を下図に示します。 ご覧のとおり、初期段階(横軸の左側、コンテキストの長さが短い場合)では、Baichuan2-192Kの混同レベルは低いレベルにあります。 コンテキストの長さが長くなるにつれて、その利点がより明らかになり、混乱さえも減少し続けます。 このことは、Baichuan2-192Kが長い文脈でブックレベルのテキスト生成品質をよりよく維持できることを示唆しています。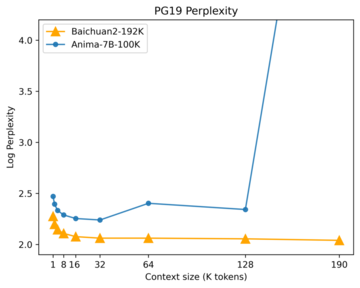 文脈の理解という点では、Baichuan2-192Kのパフォーマンスも非常に印象的です。このコンピテンシーは、権威あるロングウィンドウテキスト理解ベンチマークであるLongを使用して評価されます。 ロングは、カリフォルニア大学バークレー校などがロングウィンドウモデルの評価のために公開しているリストで、主にロングウィンドウの内容を記憶して理解するモデルの能力を測定し、モデルのスコアが高いほど良いとされています。下のグラフの評価結果からわかるように、Baichuan2-192Kは、ウィンドウ長が100Kを超えた後も、コンテキスト長が長くなっても一貫して高いパフォーマンスを維持できています。 対照的に、Claude 2 の全体的なパフォーマンスは、ウィンドウの長さが 80K を超えると劇的に低下します。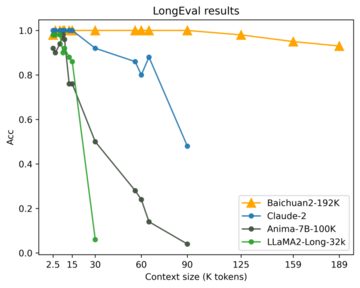 さらに、このモデルは、Dureader、NarrativeQA、TriviaQA、LSHT、および中国語と英語の長文Q&Aと抄録のその他の評価セットでテストされています。 その結果、Baichuan 2-192Kも優れた性能を発揮し、ほとんどの長文評価タスクで他のモデルよりも優れていることが示されました。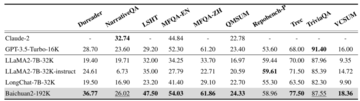 要するに、コンテンツの処理時間が長ければ長いほど、Baichuan の大規模モデルの相対的なパフォーマンスは向上します。**192Kの超長いコンテキスト、白川はどのようにそれを行いましたか? **AI 業界では、コンテキスト ウィンドウを拡張すると大規模なモデルのパフォーマンスを効果的に向上させることができるというのがコンセンサスですが、コンテキスト ウィンドウが超長くなると、コンピューティング能力の要件が高くなり、メモリの負荷が大きくなります。このプレッシャーを軽減するために、モデルを小さくするなど、いくつかの妥協的な方法が業界で登場しています。 ウィンドウをスライドさせるなどして、モデルが前のテキストを積極的に放棄し、最新の入力に対してのみアテンションメカニズムを保持できるようにします。 コンテキストやRAG(Retrieval Enhanced Generation)をダウンサンプリングすることで、入力の一部のみを保持するアテンションメカニズムなど。これらの方法ではコンテキスト ウィンドウの長さが長くなる可能性がありますが、程度の差こそあれ、モデルのパフォーマンスが損なわれます。 言い換えれば、コンテキスト ウィンドウの長さと引き換えに、モデルの他の側面のパフォーマンスを犠牲にします (たとえば、モデルが全文情報に基づいて複雑な質問に答えられないことや、複数のテキストにまたがって回答を検討することの難しさなど)。今回白川が発売したBaichaun2-192K**は、アルゴリズムとエンジニアリングの究極の最適化により、ウィンドウ長とモデル性能のバランスを実現し、ウィンドウ長とモデル性能の同時向上**を実現しました。アルゴリズムに関しては、Baichuan Intelligentは、RoPEとALiBiの動的位置コーディングのための外挿スキームを提案し、異なる解像度のALiBi\_maskのさまざまな程度のアテンションマスク動的補間を実行でき、解像度を確保しながら長いシーケンスに依存するモデルのモデリング能力を高めることができます。エンジニアリングの面では、自社開発の分散トレーニングフレームワークに基づいて、Baichuan Intelligentは、テンソル並列性、フロー並列性、シーケンス並列性、再計算およびオフロード機能など、市場に出回っているすべての高度な最適化技術を統合して、4D並列分散ソリューションの包括的なセットを作成します。 このソリューションは、特定の負荷状況に応じて最適な分散戦略を自動的に見つけることができるため、長いウィンドウ推論プロセスでのメモリ占有率が大幅に削減されます。**大型モデルの戦いを戦い、速くあれ**今年4月に設立されたBaichuan Intelligenceは、業界最速のテクノロジーイテレーションを備えた大規模なモデルスタートアップといえるでしょう。 設立からわずか半年で、同社は4つのオープンソースおよび無料の商用モデル、Baichuan-7B/13BとBaichuan2-7B/13B、および2つのクローズドソースモデル、Baichuan-53BとBaichuan2-53Bをリリースしました。平均して、毎月新しい大型モデルがリリースされます。Baichuanシリーズの大規模モデルは、意図理解、情報検索、強化学習技術を統合し、教師あり微調整と人間の意図の整列と組み合わせ、知識の質問応答とテキスト作成の分野で優れたパフォーマンスを発揮します。 これらの大規模モデルは、その機能から業界でも好まれており、主要なオープンソースコミュニティにおけるBaichuanシリーズのオープンソースモデルの累積ダウンロード数は600万を超えています。 Baichuan 2 はあらゆる面で Llama 2 を凌駕しており、中国のオープンソース エコシステムの発展をリードしています。8月31日、白川インテリジェントは「生成人工知能サービス管理のための暫定措置」を先導して可決し、8社の第1陣の中で今年設立された唯一の大規模モデル企業となった。 9月25日、Baichuan Intelligent は Baichuan API インターフェースを開設し、To B 分野に正式に参入し、商品化プロセスを開始しました。技術の研究開発から着陸まで、白川の速度は十分に速いと言えます。リリースされたばかりのBaichuan2-192Kは、クローズドベータテストを正式に開始し、API呼び出しの形でコアパートナーに公開されます。 Baichuanは、金融メディアや法律事務所との協力関係に達し、Baichuan2-192Kの優れたロングコンテキスト機能をメディア、金融、法律などの特定のシナリオに適用し、まもなくAPI呼び出しと民営化された展開の形で企業ユーザーに提供されると述べた。APIの形で完全に開かれた後、Baichuan2-192Kは多数の垂直シナリオと深く統合でき、人々の仕事、生活、学習に役割を果たし、業界ユーザーの効率を大幅に向上させるのに役立ちます。 Baichuan2-192Kは、一度に数百ページの資料を処理および分析できるため、長文のドキュメントの要約、長文のドキュメントレビュー、長文の記事やレポートの作成、複雑なプログラミング支援などの実際のシナリオで非常に役立ちます。  以前、Baichuan Intelligenceの創業者兼最高経営責任者(CEO)であるWang Xiaochuan氏は、今年下半期にBaichuanが1000億レベルの大規模モデルを立ち上げ、来年にはCエンドのスーパーアプリケーション展開が行われると予想されていることを明らかにしていた。OpenAIとのギャップに直面して、Wang Xiaochuan氏は、私たちとOpenAIの間には確かに理想のギャップがあることを認め、OpenAIの目標はインテリジェンスの天井を探ることであり、1,000万個のGPUを接続するテクノロジーを設計したいとさえ思っています。 しかし、応用の面では、米国よりも速く進んでおり、インターネット時代に蓄積された応用と生態学的経験は、私たちをどんどん遠くに進めることができるため、大きな模型を作る白川の概念は、「**理想では1歩遅く、地上では3歩速く**」と呼ばれています。この観点から、Baichuan2-192Kはこのコンセプトの延長線上にあり、世界最長のコンテキストウィンドウは間違いなくBaichuanインテリジェントラージモデルテクノロジーのプロセスを加速します。


一度に350,000文字の漢字を読むことができる世界最強のロングテキストモデル:Baichuan2-192Kがオンラインになりました
国内の大型モデルスタートアップは、テクノロジーの最前線で新記録を創出しています。
10 月 30 日、Baichuan Intelligence は、大規模言語モデル (LLM) コンテキスト ウィンドウの長さを 192K トークン に増やした Baichuan2-192K ロング ウィンドウ ラージ モデルを正式にリリースしました。
これは、大規模モデルで一度に約35万文字の漢字を処理することに相当し、GPT-4(32Kトークン、約25,000文字)の14倍、Claude 2.0(100Kトークン、約80,000文字)の4.4倍の長さです。
言い換えれば、Baichuan2-192K は Three-Body Problem 2 のコピーを一度に読み取ることができ、世界で最も長い処理コンテキスト ウィンドウを持つ最大のモデルになります。 さらに、テキスト生成品質、文脈理解、Q&A機能など、多面的に競合他社を大幅に上回っています。
一度に非常に長いテキストを理解できる大規模なモデルで何ができますか? Baichuan Intelligent は簡単なデモンストレーションを行いました。
「三体問題2:暗い森」全体のPDFファイルをアップロードすると、白川モデルは30万語になります。 次に、小説について質問すると、モデルは簡潔で正確な答えを与えることができます。
直接パッケージ化してアップロードでき、白川モデルは5つのニュース記事を1つに簡単に統合できます。
数万語から数十万語まで、大手スタートアップは「長い窓」をつかもうと急いでいます
テキスト理解の方向で大規模なモデルの適用に注意を払うと、現象に気付くかもしれません:最初に、モデルの能力を評価するために使用されるテキストは、通常数十ページから数十ページの範囲の財務報告書と技術報告書であり、単語数は通常数万語です。 しかし、その後、テストテキストは徐々に数時間の会議時間、または数十万語の小説に発展し、競争はますます激しく困難になりました。
なぜこれらの企業は長文に挑戦しているのでしょうか?
まず、アプリケーションの観点から見ると、生産性向上のために大きなモデルを使う多くの労働者は、弁護士、アナリスト、コンサルタントなど、必然的に長い文章を扱わなければならず、コンテキストウィンドウが大きくなればなるほど、これらの人々が大きなモデルでできることの範囲が広がります。 第2に、技術的な観点からは、ウィンドウが保持できる情報が多ければ多いほど、モデルが次の単語を生成する際に参照できる情報が増えれば増えるほど、「幻覚」が起こりにくくなり、情報がより正確になるという、大規模モデル技術の実装に必要な条件となります。 したがって、モデルのパフォーマンスを向上させようとする一方で、企業はコンテキストウィンドウを大きくして、より多くのアプリケーションシナリオに投入できるユーザーを競い合っています。
前に示したいくつかの例からわかるように、Baichuan2-192Kはテキスト生成の品質と文脈の理解の両方に優れています。 そして、これらの定性的な結果に加えて、いくつかの定量的な評価データにもそれが見られます。
Baichuan2-192K:ファイルが長いほど、利点はより明白になります
テキスト生成の品質評価において、人間の自然言語の習慣に合致した高品質な文書をテストセットとすると、モデルが中国語版のテストセットを生成する確率が高くなるほど、モデルの混乱は小さくなり、より良いモデルになるという、非常に重要な指標があります。
白川大規模モデルのパープレキリティをテストするために使用されるテストセットは、PG-19と呼ばれます。 このデータセットはDeepMindの研究者によって作成され、プロジェクト・グーテンベルクの書籍の資料を使用して作成されたため、PG-19は書籍品質の品質を備えています。
テスト結果を下図に示します。 ご覧のとおり、初期段階(横軸の左側、コンテキストの長さが短い場合)では、Baichuan2-192Kの混同レベルは低いレベルにあります。 コンテキストの長さが長くなるにつれて、その利点がより明らかになり、混乱さえも減少し続けます。 このことは、Baichuan2-192Kが長い文脈でブックレベルのテキスト生成品質をよりよく維持できることを示唆しています。
このコンピテンシーは、権威あるロングウィンドウテキスト理解ベンチマークであるLongを使用して評価されます。 ロングは、カリフォルニア大学バークレー校などがロングウィンドウモデルの評価のために公開しているリストで、主にロングウィンドウの内容を記憶して理解するモデルの能力を測定し、モデルのスコアが高いほど良いとされています。
下のグラフの評価結果からわかるように、Baichuan2-192Kは、ウィンドウ長が100Kを超えた後も、コンテキスト長が長くなっても一貫して高いパフォーマンスを維持できています。 対照的に、Claude 2 の全体的なパフォーマンスは、ウィンドウの長さが 80K を超えると劇的に低下します。
**192Kの超長いコンテキスト、白川はどのようにそれを行いましたか? **
AI 業界では、コンテキスト ウィンドウを拡張すると大規模なモデルのパフォーマンスを効果的に向上させることができるというのがコンセンサスですが、コンテキスト ウィンドウが超長くなると、コンピューティング能力の要件が高くなり、メモリの負荷が大きくなります。
このプレッシャーを軽減するために、モデルを小さくするなど、いくつかの妥協的な方法が業界で登場しています。 ウィンドウをスライドさせるなどして、モデルが前のテキストを積極的に放棄し、最新の入力に対してのみアテンションメカニズムを保持できるようにします。 コンテキストやRAG(Retrieval Enhanced Generation)をダウンサンプリングすることで、入力の一部のみを保持するアテンションメカニズムなど。
これらの方法ではコンテキスト ウィンドウの長さが長くなる可能性がありますが、程度の差こそあれ、モデルのパフォーマンスが損なわれます。 言い換えれば、コンテキスト ウィンドウの長さと引き換えに、モデルの他の側面のパフォーマンスを犠牲にします (たとえば、モデルが全文情報に基づいて複雑な質問に答えられないことや、複数のテキストにまたがって回答を検討することの難しさなど)。
今回白川が発売したBaichaun2-192Kは、アルゴリズムとエンジニアリングの究極の最適化により、ウィンドウ長とモデル性能のバランスを実現し、ウィンドウ長とモデル性能の同時向上を実現しました。
アルゴリズムに関しては、Baichuan Intelligentは、RoPEとALiBiの動的位置コーディングのための外挿スキームを提案し、異なる解像度のALiBi_maskのさまざまな程度のアテンションマスク動的補間を実行でき、解像度を確保しながら長いシーケンスに依存するモデルのモデリング能力を高めることができます。
エンジニアリングの面では、自社開発の分散トレーニングフレームワークに基づいて、Baichuan Intelligentは、テンソル並列性、フロー並列性、シーケンス並列性、再計算およびオフロード機能など、市場に出回っているすべての高度な最適化技術を統合して、4D並列分散ソリューションの包括的なセットを作成します。 このソリューションは、特定の負荷状況に応じて最適な分散戦略を自動的に見つけることができるため、長いウィンドウ推論プロセスでのメモリ占有率が大幅に削減されます。
大型モデルの戦いを戦い、速くあれ
今年4月に設立されたBaichuan Intelligenceは、業界最速のテクノロジーイテレーションを備えた大規模なモデルスタートアップといえるでしょう。 設立からわずか半年で、同社は4つのオープンソースおよび無料の商用モデル、Baichuan-7B/13BとBaichuan2-7B/13B、および2つのクローズドソースモデル、Baichuan-53BとBaichuan2-53Bをリリースしました。
平均して、毎月新しい大型モデルがリリースされます。
Baichuanシリーズの大規模モデルは、意図理解、情報検索、強化学習技術を統合し、教師あり微調整と人間の意図の整列と組み合わせ、知識の質問応答とテキスト作成の分野で優れたパフォーマンスを発揮します。 これらの大規模モデルは、その機能から業界でも好まれており、主要なオープンソースコミュニティにおけるBaichuanシリーズのオープンソースモデルの累積ダウンロード数は600万を超えています。 Baichuan 2 はあらゆる面で Llama 2 を凌駕しており、中国のオープンソース エコシステムの発展をリードしています。
8月31日、白川インテリジェントは「生成人工知能サービス管理のための暫定措置」を先導して可決し、8社の第1陣の中で今年設立された唯一の大規模モデル企業となった。 9月25日、Baichuan Intelligent は Baichuan API インターフェースを開設し、To B 分野に正式に参入し、商品化プロセスを開始しました。
技術の研究開発から着陸まで、白川の速度は十分に速いと言えます。
リリースされたばかりのBaichuan2-192Kは、クローズドベータテストを正式に開始し、API呼び出しの形でコアパートナーに公開されます。 Baichuanは、金融メディアや法律事務所との協力関係に達し、Baichuan2-192Kの優れたロングコンテキスト機能をメディア、金融、法律などの特定のシナリオに適用し、まもなくAPI呼び出しと民営化された展開の形で企業ユーザーに提供されると述べた。
APIの形で完全に開かれた後、Baichuan2-192Kは多数の垂直シナリオと深く統合でき、人々の仕事、生活、学習に役割を果たし、業界ユーザーの効率を大幅に向上させるのに役立ちます。 Baichuan2-192Kは、一度に数百ページの資料を処理および分析できるため、長文のドキュメントの要約、長文のドキュメントレビュー、長文の記事やレポートの作成、複雑なプログラミング支援などの実際のシナリオで非常に役立ちます。
OpenAIとのギャップに直面して、Wang Xiaochuan氏は、私たちとOpenAIの間には確かに理想のギャップがあることを認め、OpenAIの目標はインテリジェンスの天井を探ることであり、1,000万個のGPUを接続するテクノロジーを設計したいとさえ思っています。 しかし、応用の面では、米国よりも速く進んでおり、インターネット時代に蓄積された応用と生態学的経験は、私たちをどんどん遠くに進めることができるため、大きな模型を作る白川の概念は、「理想では1歩遅く、地上では3歩速く」と呼ばれています。
この観点から、Baichuan2-192Kはこのコンセプトの延長線上にあり、世界最長のコンテキストウィンドウは間違いなくBaichuanインテリジェントラージモデルテクノロジーのプロセスを加速します。