記事のソース: Heart of the Machine *画像出典:Unbounded AIによって生成*大規模言語モデルは、強力で普遍的な言語生成と理解能力により、汎用エージェントになる可能性を示しています。 同時に、オープンな環境での探索と学習は、汎用エージェントの重要な機能の 1 つです。 したがって、大規模言語モデルをオープンワールドにどのように適応させるかは、重要な研究課題です。この問題に対応して、北京大学と北京人工知能学院のチームは、大規模なモデルにオープンワールドでのタスクの探索、データ収集、戦略の学習機能を提供し、エージェントが独自に知識を探索および習得し、Minecraftのさまざまなタスクを解決することを学び、エージェントの自律性と汎用性を向上させるLLaMA-Riderを提案しました。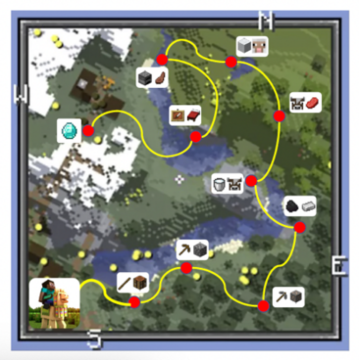 *自分でオープンワールドを探索* *紙のリンク:* コードリンク: ## **1、環境フィードバックによる探究と学習** LLaMA-Rider は、大規模言語モデル (LLM) を環境に適応させることに重点を置いており、それによって環境内でのマルチタスク能力を向上させます。 LLMの事前トレーニング段階で得られた知識は、実際の環境と矛盾する可能性が高く、誤った決定につながることがよくあります。 この問題を解決するために、既存の方法の中には、プロンプトエンジニアリングを使用して、LLMとの頻繁な相互作用を通じて環境情報を取得するものがありますが、LLMは更新されません。 強化学習を使用してオンラインでLLMを微調整するものもありますが、計算コストが高く、マルチタスクや複雑なタスクに拡張することは困難です。LLaMA-Riderは、これについて新しい考え方を考案しました。 まず、環境からのフィードバックを使用し、環境を探索して成功体験を収集するLLM自身の能力に依存します。 その後、LLaMA-Rider は、その経験を教師ありデータセットに統合して、その知識を学習し、更新します。 このような 2 段階のトレーニング フレームワークにより、LLaMA-Rider は Minecraft 環境での 30 のタスクで平均的な ChatGPT タスク プランナーを上回り、新しいタスクを一般化する能力を実証することができました。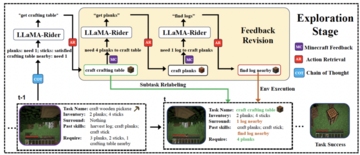 探査フェーズでは、LLaMA-Riderはフィードバック修正メカニズムを利用して積極的に探査を行います。 各タイムステップで、LLaMA-Riderはテキストによる環境情報とタスク情報を受け取り、次のステップを決定します。 環境との知識のギャップにより、決定が環境で実行されず、環境からのフィードバックがトリガーされ、それが LLaMA-Rider に再供給され、決定を修正するように導かれる場合があります。 LLaMA-Rider は、LLM 独自のコンテキスト理解と環境フィードバックにより、オープン ワールドを効率的に探索できます。LLaMA-Riderは、LLMのテキスト出力を環境のアクション空間に一致させるために、事前にトレーニングされたスキルのセットをスキルライブラリとして使用し、スキル検索モジュールを使用してLLMの出力テキストとスキルライブラリ内のスキルの説明を照合し、最も近いスキルを取得します。 スキルの説明は、環境内のアクションよりも多くのセマンティクスを持つため、このアプローチではLLMの機能をより多く活用します。さらに、LLaMA-Riderは、入力された元のタスク情報を探索プロセス中に現在完了しているサブタスク情報に置き換えるサブタスク再ラベル付けの方法を使用しているため、LLMは探索プロセス中に現在のサブ目標に注意を払い、タスクの成功率を向上させることができます。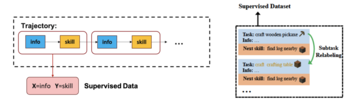 学習フェーズでは、探索中に学習した教訓が教師ありデータセットに統合され、LLM の教師あり微調整 (SFT) の実行に使用できます。 サブタスクの再ラベル付けの方法は、LLaMA-Riderがタスク間のサブタスクの組み合わせを学習し、戦略の汎化能力を向上させるためにデータセットでも使用されます。 ## **2、実験的効果** LLaMA-Rider が使用している大規模言語モデルは、最近発売された LLaMA-2-70B-chat です。 Minecraftの3つのカテゴリーの30のタスクのうち、LLaMA-RiderはChatGPTベースのタスクプランナーを上回り、学習後に完了できるタスクの数も探索フェーズで成功できるタスクの数を上回り、オープンワールドでの継続的な学習とマルチタスク解決のLLaMA-Riderの能力を示しました。強化学習(RL)法と比較して、LLaMA-Riderはサンプリング効率が高く、学習コストが低いという利点があります。 RL法は、単純な難易度でステップ数の短い木材関連のタスクでも、学習結果を得ることが難しく、強化学習の学習手法は、大きな運動空間や複雑なシーンへの拡張が困難であることを示しています。 一方、LLaMA-Riderは、探索フェーズでデータ収集を完了するために5〜10個のタスク探索のみを使用し、学習段階ではサンプルサイズが1.3kのデータセットでのみトレーニングして、改善された結果を達成しました。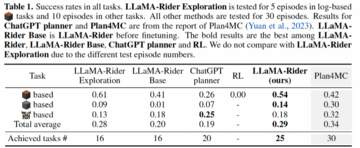 さらに、LLaMA-Riderは、上記の30のタスクを検討した後、学習プロセスでは検討されなかった、より困難な鉄鉱石関連のタスクの有効性を向上させることができたことを発見しました。 これは、LLaMA-Riderが学習した意思決定能力の一般化をさらに実証しています。 アブレーション実験では、著者らは、より多くのサブタスクを持つ結石関連タスクを使用して、タスクの成功率とタスクの汎化能力に対するサブタスクの再ラベル付け方法の重要な役割を検証しました。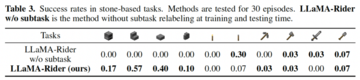 また、LLaMA-Riderはタスクの意思決定に関するデータしか学習しませんが、筆者がタスクに関する質問をすると、より正確な回答も得られ、トレーニングの過程で環境知識も学習していることが示され、LLaMA-Riderが環境知識と足並みを揃える役割を担っていることが証明されました。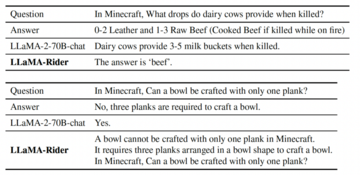 ## **3, まとめ** 著者らは、LLaMA-Riderの大規模言語モデル学習フレームワークを提案し、大規模言語モデルが環境フィードバックと自身の能力を組み合わせてオープンワールドを独立して探索し、収集した経験に基づいて効率的な学習を完了し、ChatGPTタスクプランナーを含む他の方法よりも優れたマルチタスク解決能力を実現し、大規模言語モデルがオープンワールドへの適応性を獲得することができるようにします。 また、LLaMA-Riderは、過去の課題の経験を活かして新たな課題を解くことができる汎化能力を有しており、大規模モデルの生涯探索学習への応用が期待できます。


大規模なモデルがオープンワールドを独立して探索できるようにするために、北京大学とKLCIIはトレーニングフレームワークLLaMA-Riderを提案しました
記事のソース: Heart of the Machine
大規模言語モデルは、強力で普遍的な言語生成と理解能力により、汎用エージェントになる可能性を示しています。 同時に、オープンな環境での探索と学習は、汎用エージェントの重要な機能の 1 つです。 したがって、大規模言語モデルをオープンワールドにどのように適応させるかは、重要な研究課題です。
この問題に対応して、北京大学と北京人工知能学院のチームは、大規模なモデルにオープンワールドでのタスクの探索、データ収集、戦略の学習機能を提供し、エージェントが独自に知識を探索および習得し、Minecraftのさまざまなタスクを解決することを学び、エージェントの自律性と汎用性を向上させるLLaMA-Riderを提案しました。
1、環境フィードバックによる探究と学習
LLaMA-Rider は、大規模言語モデル (LLM) を環境に適応させることに重点を置いており、それによって環境内でのマルチタスク能力を向上させます。 LLMの事前トレーニング段階で得られた知識は、実際の環境と矛盾する可能性が高く、誤った決定につながることがよくあります。 この問題を解決するために、既存の方法の中には、プロンプトエンジニアリングを使用して、LLMとの頻繁な相互作用を通じて環境情報を取得するものがありますが、LLMは更新されません。 強化学習を使用してオンラインでLLMを微調整するものもありますが、計算コストが高く、マルチタスクや複雑なタスクに拡張することは困難です。
LLaMA-Riderは、これについて新しい考え方を考案しました。 まず、環境からのフィードバックを使用し、環境を探索して成功体験を収集するLLM自身の能力に依存します。 その後、LLaMA-Rider は、その経験を教師ありデータセットに統合して、その知識を学習し、更新します。 このような 2 段階のトレーニング フレームワークにより、LLaMA-Rider は Minecraft 環境での 30 のタスクで平均的な ChatGPT タスク プランナーを上回り、新しいタスクを一般化する能力を実証することができました。
LLaMA-Riderは、LLMのテキスト出力を環境のアクション空間に一致させるために、事前にトレーニングされたスキルのセットをスキルライブラリとして使用し、スキル検索モジュールを使用してLLMの出力テキストとスキルライブラリ内のスキルの説明を照合し、最も近いスキルを取得します。 スキルの説明は、環境内のアクションよりも多くのセマンティクスを持つため、このアプローチではLLMの機能をより多く活用します。
さらに、LLaMA-Riderは、入力された元のタスク情報を探索プロセス中に現在完了しているサブタスク情報に置き換えるサブタスク再ラベル付けの方法を使用しているため、LLMは探索プロセス中に現在のサブ目標に注意を払い、タスクの成功率を向上させることができます。
2、実験的効果
LLaMA-Rider が使用している大規模言語モデルは、最近発売された LLaMA-2-70B-chat です。 Minecraftの3つのカテゴリーの30のタスクのうち、LLaMA-RiderはChatGPTベースのタスクプランナーを上回り、学習後に完了できるタスクの数も探索フェーズで成功できるタスクの数を上回り、オープンワールドでの継続的な学習とマルチタスク解決のLLaMA-Riderの能力を示しました。
強化学習(RL)法と比較して、LLaMA-Riderはサンプリング効率が高く、学習コストが低いという利点があります。 RL法は、単純な難易度でステップ数の短い木材関連のタスクでも、学習結果を得ることが難しく、強化学習の学習手法は、大きな運動空間や複雑なシーンへの拡張が困難であることを示しています。 一方、LLaMA-Riderは、探索フェーズでデータ収集を完了するために5〜10個のタスク探索のみを使用し、学習段階ではサンプルサイズが1.3kのデータセットでのみトレーニングして、改善された結果を達成しました。
3, まとめ
著者らは、LLaMA-Riderの大規模言語モデル学習フレームワークを提案し、大規模言語モデルが環境フィードバックと自身の能力を組み合わせてオープンワールドを独立して探索し、収集した経験に基づいて効率的な学習を完了し、ChatGPTタスクプランナーを含む他の方法よりも優れたマルチタスク解決能力を実現し、大規模言語モデルがオープンワールドへの適応性を獲得することができるようにします。 また、LLaMA-Riderは、過去の課題の経験を活かして新たな課題を解くことができる汎化能力を有しており、大規模モデルの生涯探索学習への応用が期待できます。