出典: Heart of the Machine 画像ソース: Unbounded AIによって生成ビデオゲームは今日の現実世界のシミュレーションになり、可能性は無限大です。 たとえば、グランド・セフト・オート(GTA)というゲームでは、プレイヤーは一人称視点でロスサントス(ゲームの仮想都市)でのカラフルな生活を体験できます。 しかし、人間のプレイヤーがロスサントスを歩き回り、多くのミッションを完了できる場合、GTAキャラクターを操作してミッションの「プレイヤー」になるAIビジョンモデルも持つことができますか?現在の視覚言語モデル(VLM)は、マルチモーダルな知覚と推論において大きな進歩を遂げていますが、多くの場合、より単純な視覚的な質問応答(VQA)または視覚的な注釈(キャプション)タスクに基づいています。 明らかに、これらのタスクでは、VLMが実際のタスクを実際に実行することはできません。 実際のタスクでは、視覚情報の理解だけでなく、リアルタイムで更新された環境情報に基づいて計画推論とフィードバックを行うモデルの能力も必要だからです。 同時に、結果として得られる計画は、タスクを現実的に達成するために環境内のエンティティを操作できる必要もあります。既存の言語モデル(LLM)は、提供された情報に基づいてタスクを計画できますが、視覚的な入力を理解できないため、現実世界で特定のタスクを実行する際の言語モデルの適用範囲が大幅に制限され、特に一部の具体化された知能タスクでは、テキストベースの入力は詳細化が困難であったり、複雑すぎたりすることが多く、言語モデルはタスクを完了するためにそれらから情報を効率的に抽出できません。 現在の言語モデルでは、プログラム生成のための調査がいくつか行われていますが、視覚的な入力に基づいて構造化され、実行可能で、堅牢なコードを生成する方法はまだ検討されていません。大規模モデルをいかに具現化・知能化し、正確に計画を立てて命令を実行できる自律的・状況認識システムを作るかという問題を解決するために、シンガポールの南洋理工大学や清華大学などの学者がOctopusを提案しました。 Octopusは、視覚ベースのプログラマブルエージェントであり、その目的は、視覚入力を通じて学習し、現実世界を理解し、実行可能コードを生成する方法でさまざまな現実世界のタスクを実行することです。 多数の視覚入力と実行可能コードのペアでトレーニングを受けたOctopusは、ビデオゲームのキャラクターを操作してゲーム内のタスクを完了したり、複雑な家事をこなしたりする方法を学びました。 *住所:* プロジェクトページ:* オープンソースコード:## **データ収集とトレーニング**また、身体化された知能タスクを実行できる視覚言語モデルをトレーニングするために、研究者は、トレーニングデータを提供する2つのシミュレーションシステムとOctopusのトレーニング用のテスト環境で構成されるOctoVerseも開発しました。 これら2つのシミュレーション環境は、VLMの具現化されたインテリジェンスのための使用可能なトレーニングおよびテストシナリオを提供し、モデルの推論およびタスク計画機能に対するより高い要件を提示します。 詳細は次のとおりです。1. OctoGibson: スタンフォード大学が開発した OmniGibson に基づいており、合計 476 の実際の家庭活動が含まれています。 シミュレーション環境全体には、16 の異なるカテゴリのホーム シナリオが含まれており、155 の実際のホーム 環境の例をカバーしています。 モデルは、その中に存在する多数の対話可能なオブジェクトを操作して、最終的なタスクを実行できます。2. OctoGTA:グランド・セフト・オート(GTA)ゲームに基づいて、合計20のミッションが構築され、5つの異なるシナリオに一般化されています。 あらかじめ設定されたプログラムでプレイヤーを固定位置に設定し、ミッションを完了するために必要なアイテムとNPCを提供して、ミッションをスムーズに実行できるようにします。次の図は、OctoGibson のタスク分類と、OctoGibson と OctoGTA の統計の一部を示しています。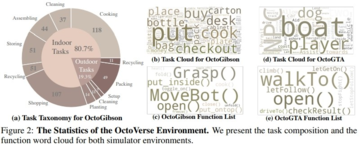 2つのシミュレーション環境でトレーニングデータを効率的に収集するために、研究者は完全なデータ収集システムを構築しました。 タスクの実行者としてGPT-4を導入することで、あらかじめ実装された機能を用いて、シミュレーション環境で収集した視覚入力をテキスト情報に加工してGPT-4に提供し、GPT-4が現在のステップのタスク計画と実行コードを返した後、シミュレーション環境でコードを実行し、現在のステップのタスクが完了したか否かを判定します。 成功した場合は、次の視覚入力の収集に進みます。 失敗した場合は、前のステップの開始位置に戻り、データを再収集します。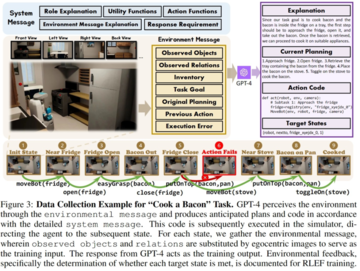 上の図は、OctoGibson 環境で Cook a Bacon タスクを例にとったデータ収集プロセス全体を示しています。 なお、データ収集の過程では、タスク実行時の視覚情報やGPT-4が返す実行コードなどを記録するだけでなく、各サブタスクの成功も記録し、より効率的なVLMを構築するための強化学習の導入の基礎として活用しています。 GPT-4は強力ですが、不死身ではありません。 エラーは、構文エラーやシミュレーターでの物理的な問題など、さまざまな形で現れる可能性があります。 たとえば、図 3 に示すように、状態 #5 と #6 の間では、エージェントがベーコンを鍋から離しすぎているため、「ベーコンを鍋に入れる」アクションは失敗します。 このような挫折により、タスクは以前の状態にリセットされます。 タスクが 10 ステップ後に完了しなかった場合、そのタスクは失敗したと見なされ、予算上の理由でタスクは終了し、タスクのサブタスクのすべてのデータ ペアは失敗したと見なされます。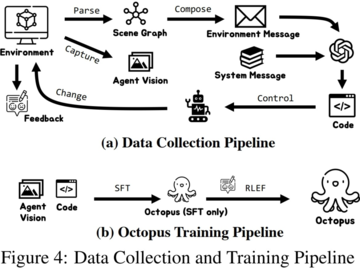 研究者たちは、一定規模のトレーニングデータを収集した後、このデータを使用して、具体化されたインテリジェントな視覚言語モデルであるOctopusをトレーニングしました。 上の図は、完全なデータ収集とトレーニングのプロセスを示しています。 第1段階では、収集したデータを教師あり微調整に用いることで、視覚情報を入力とし、一定のフォーマットに従って出力できるVLMモデルを構築しました。 この段階で、モデルは、タスク計画と実行可能コードへの視覚的な入力情報のマッピングを完了できます。 第2段階では、研究者はRLEFを導入しました(Reinforcement Learning with Environmental Feedback)は、以前に収集したサブタスクの成功を報酬信号とし、強化学習アルゴリズムを用いてVLMのタスク計画能力をさらに向上させることで、タスクの全体的な成功率を向上させます。## **実験結果**研究者らは、OctoGibson環境で現在主流のVLMとLLMをテストし、次の表に主な実験結果を示します。 異なるテストモデルの場合、ビジョンモデルは異なるモデルで使用されるビジュアルモデルを列挙し、LLMの場合、研究者はLLMへの入力として視覚情報をテキストとして処理します。 ここで、O はシーン内の対話可能なオブジェクトに関する情報を提供することを意味し、R はシーン内のオブジェクトの相対的な関係に関する情報を提供することを意味し、GT は検出のための追加の視覚モデルを導入することなく、実際の正確な情報を使用することを表します。すべてのテストタスクについて、研究者は完全なテスト統合能力を報告し、さらに4つのカテゴリに分類し、トレーニングセットに存在するシナリオで新しいタスクを完了する能力、トレーニングセットに存在しないシナリオで新しいタスクを完了する汎化能力、および単純なフォロータスクと複雑な推論タスクを完了する汎化能力を記録しました。 統計の各カテゴリーについて、研究者は2つの評価指標を報告し、そのうちの1つはタスクの完了率であり、具体化された知能タスクを完了する際のモデルの成功率を測定しました。 2つ目は、タスクを計画するモデルの能力を反映するために使用されるタスク計画の精度です。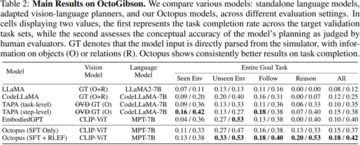 さらに、研究者らは、OctoGibsonシミュレーション環境で取得した視覚データに対して、さまざまなモデルがどのように反応するかの例を示しています。 下の画像は、OctoGibsonで生成された視覚入力に対するTAPA+CodeLLaMA、Octopus、およびGPT-4Vの応答を示しています。 TAPA+CodeLLaMAや教師あり微調整のみのOctopusモデルと比較して、RLEFで学習したOctopusモデルはより合理的なタスク計画を持ち、より曖昧なタスク指示(カーボーイを見つける)に対してもより完全な計画を提供できることがわかります。 これらのパフォーマンスは、モデルのタスク計画能力と推論能力を向上させる上でのRLEFトレーニング戦略の有効性をさらに示しています。 一般に、シミュレーション環境における既存のモデルの実際のタスク完了機能とタスク計画機能には、まだ改善の余地があります。 研究者は、いくつかの重要な調査結果をまとめました。**1.CodeLLaMAは、モデルのコード生成能力を向上させることができますが、タスク計画能力を向上させることはできません。 **研究者らは、CodeLLaMAがモデルのコード生成能力を大幅に向上させることができることを実験結果が示していると指摘しました。 従来のLLMと比較して、CodeLLaMAはより高い実行速度でより良いコードを可能にします。 ただし、一部のモデルではコード生成に CodeLLaMA を使用しますが、タスクの全体的な成功率は、タスク計画能力によって制限されます。 一方、Octopusは、CodeLLaMAの不足によりコードの実行率は低下していますが、タスク計画能力が強いため、全体的なタスク成功率は他のモデルよりも優れています。**2.LLMは、大量のテキスト入力に直面して処理するのが難しいです。 **実際のテストプロセスでは、TAPAとCodeLLaMAの実験結果を比較し、言語モデルが長いテキスト入力をうまく処理することは困難であるという結論に達しました。 研究者はTAPAのアプローチに従い、ミッション計画に実際の物体情報を使用し、CodeLLaMAは物体間の相対的な位置関係を使用してより完全な情報を提供しました。 しかし、実験の過程で、環境内の冗長な情報量が多いため、環境が複雑になるとテキスト入力が大幅に増加し、LLMが大量の冗長な情報から貴重な手がかりを抽出することが困難になり、タスクの成功率が低下することを発見しました。 これは、複雑なシナリオを表すためにテキスト情報を使用すると、冗長で価値のない入力が大量に発生する可能性があるというLLMの限界も反映しています。3.タコは優れたタスク一般化能力を示しています。 **実験結果から、Octopusはタスクを一般化する強力な能力を持っていると結論付けることができます。 トレーニング セットに表示されない新しいシナリオでのタスク完了とタスク計画の成功率は、既存のモデルの成功率よりも優れています。 これはまた、同じクラスのタスクに対して従来のLLMよりも一般化できるビジュアル言語モデルの固有の利点のいくつかを示しています。4. RLEFは、モデルのタスク計画機能を強化します。 **実験結果では、教師あり微調整の第1段階のみを行ったモデルと、RLEFによってトレーニングされたモデルのパフォーマンスを比較しました。 RLEFのトレーニング後、強力な推論能力とタスク計画能力を必要とするタスクについて、モデルの全体的な成功率と計画能力が大幅に向上したことがわかります。 また、RLEFは既存のVLMトレーニング戦略よりもはるかに効率的です。 上の図に示した例は、RLEFトレーニング後のモデルのタスク計画能力の向上も示すことができます。 RLEFでトレーニングされたモデルは、より複雑なタスクに直面したときに環境をナビゲートする方法を理解でき、モデルはタスク計画の観点からシミュレーション環境の実際の要件により準拠しているため(たとえば、モデルは対話を開始する前にオブジェクトに移動して対話する必要があるため)、タスク計画の失敗率が低下します。## **ディスカッション****アブレーション実験**モデルの実際の機能を評価した後、研究者はモデルのパフォーマンスに影響を与える可能性のあるいくつかの要因を詳しく調べました。 下図のように、3つの側面から実験を行いました。1. トレーニングパラメータの重み研究者らは、言語モデルのみで学習した接続層、学習済みの接続層と言語モデル、および完全に学習したモデルのパフォーマンスを比較しました。 トレーニングパラメータの増加に伴い、モデルのパフォーマンスが徐々に向上していることがわかります。 これは、トレーニング パラメーターの数が、一部の固定シナリオでモデルがタスクを完了できるかどうかにとって重要であることを示しています。2.モデルのサイズ研究者らは、2つのトレーニングフェーズで、より小さい3Bパラメータモデルとベースライン7Bモデルのパフォーマンスを比較しました。 比較により、モデルの全体的なパラメータが大きい場合、モデルのパフォーマンスも大幅に向上することがわかります。 モデルが対応するタスクを完了する能力を持つと同時に、モデルの軽量で高速な推論速度を確保できるように、適切なモデルトレーニングパラメータを選択する方法は、VLM分野の将来の研究の重要なポイントになります。3. 視覚入力の連続性さまざまな視覚入力が実際のVLMの性能に与える影響を調べるために、研究者らは視覚情報の入力順序を実験しました。 テスト中、モデルはシミュレーション環境内で順番に回転し、一人称視点と2つの鳥瞰図をキャプチャし、VLMに順次入力します。 この実験では、研究者が視覚画像の順序をランダムにシャッフルしてVLMに入力すると、VLMによって性能が大幅に低下しました。 これは、VLMにとって完全で構造化された視覚情報の重要性を示す一方で、VLMが視覚入力に応答する視覚イメージの内部接続に依存しており、この視覚的接続が壊れるとVLMのパフォーマンスに大きな影響を与えることをある程度反映しています。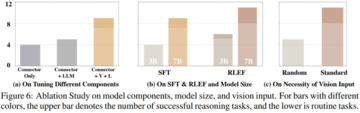 **GPT-4**さらに、研究者らは、シミュレートされた環境でGPT-4とGPT-4Vのパフォーマンスをテストおよび計算しました。1.GPT-4(英語)GPT-4の場合、研究者は、トレーニングデータを収集するためにGPT-4を使用する場合とまったく同じテキスト情報をテスト中に入力として提供します。 GPT-4はテストタスクの半分をこなすことができ、GPT-4のような言語モデルと比較して、既存のVLMにはまだまだ性能改善の余地があることを示しており、一方で、GPT-4のような強力なパフォーマンスを持つ言語モデルであっても、具体化された知能タスクに直面した場合、タスク計画とタスク実行能力をさらに向上させる必要があることも示しています。2.GPT-4VGPT-4Vは直接呼び出せるAPIをリリースしたばかりなので、研究者はまだ試す時間がありませんでしたが、研究者はGPT-4Vの性能を実証するために、いくつかの例を手動でテストしています。 研究者らは、いくつかの例を通じて、GPT-4Vはシミュレーション環境のタスクに対して強力なゼロショット汎化能力を持ち、視覚的な入力に基づいて対応する実行可能コードを生成することもできますが、一部のタスク計画ではシミュレーション環境で収集されたデータに基づいて微調整されたモデルよりもわずかに劣ると考えています。## **まとめ**研究者らは、現在の研究のいくつかの限界を指摘している。1.現在のOctopusモデルは、より複雑なタスクには不十分です。 複雑なタスクに直面すると、Octopusはしばしば誤った計画を立て、環境からのフィードバックに大きく依存し、タスク全体を完了するのに苦労することがよくあります。2.Octopusモデルはシミュレーション環境でしか学習しておらず、それらを現実世界にどのように移行するかは一連の問題に直面します。 例えば、現実環境では、物体の相対的な位置について、モデルがより正確な情報を得ることが難しくなり、物体の理解をシーンにどう組み込んでいくかが難しくなります。3. Octopusは現在、離散的な静止画の視覚入力であり、連続した動画をいかに扱えるようにするかが今後の課題となる。 連続映像は、タスクを完了するためのモデルのパフォーマンスをさらに向上させることができますが、連続的な視覚入力をいかに効率的に処理し、理解するかが、VLMの性能をさらに向上させる鍵となります。


AIモデルをGTAの5つ星プレーヤーにするために、ビジョンベースのプログラム可能なエージェントOctopusが登場しました
出典: Heart of the Machine
ビデオゲームは今日の現実世界のシミュレーションになり、可能性は無限大です。 たとえば、グランド・セフト・オート(GTA)というゲームでは、プレイヤーは一人称視点でロスサントス(ゲームの仮想都市)でのカラフルな生活を体験できます。 しかし、人間のプレイヤーがロスサントスを歩き回り、多くのミッションを完了できる場合、GTAキャラクターを操作してミッションの「プレイヤー」になるAIビジョンモデルも持つことができますか?
現在の視覚言語モデル(VLM)は、マルチモーダルな知覚と推論において大きな進歩を遂げていますが、多くの場合、より単純な視覚的な質問応答(VQA)または視覚的な注釈(キャプション)タスクに基づいています。 明らかに、これらのタスクでは、VLMが実際のタスクを実際に実行することはできません。 実際のタスクでは、視覚情報の理解だけでなく、リアルタイムで更新された環境情報に基づいて計画推論とフィードバックを行うモデルの能力も必要だからです。 同時に、結果として得られる計画は、タスクを現実的に達成するために環境内のエンティティを操作できる必要もあります。
既存の言語モデル(LLM)は、提供された情報に基づいてタスクを計画できますが、視覚的な入力を理解できないため、現実世界で特定のタスクを実行する際の言語モデルの適用範囲が大幅に制限され、特に一部の具体化された知能タスクでは、テキストベースの入力は詳細化が困難であったり、複雑すぎたりすることが多く、言語モデルはタスクを完了するためにそれらから情報を効率的に抽出できません。 現在の言語モデルでは、プログラム生成のための調査がいくつか行われていますが、視覚的な入力に基づいて構造化され、実行可能で、堅牢なコードを生成する方法はまだ検討されていません。
大規模モデルをいかに具現化・知能化し、正確に計画を立てて命令を実行できる自律的・状況認識システムを作るかという問題を解決するために、シンガポールの南洋理工大学や清華大学などの学者がOctopusを提案しました。 Octopusは、視覚ベースのプログラマブルエージェントであり、その目的は、視覚入力を通じて学習し、現実世界を理解し、実行可能コードを生成する方法でさまざまな現実世界のタスクを実行することです。 多数の視覚入力と実行可能コードのペアでトレーニングを受けたOctopusは、ビデオゲームのキャラクターを操作してゲーム内のタスクを完了したり、複雑な家事をこなしたりする方法を学びました。
データ収集とトレーニング
また、身体化された知能タスクを実行できる視覚言語モデルをトレーニングするために、研究者は、トレーニングデータを提供する2つのシミュレーションシステムとOctopusのトレーニング用のテスト環境で構成されるOctoVerseも開発しました。 これら2つのシミュレーション環境は、VLMの具現化されたインテリジェンスのための使用可能なトレーニングおよびテストシナリオを提供し、モデルの推論およびタスク計画機能に対するより高い要件を提示します。 詳細は次のとおりです。
OctoGibson: スタンフォード大学が開発した OmniGibson に基づいており、合計 476 の実際の家庭活動が含まれています。 シミュレーション環境全体には、16 の異なるカテゴリのホーム シナリオが含まれており、155 の実際のホーム 環境の例をカバーしています。 モデルは、その中に存在する多数の対話可能なオブジェクトを操作して、最終的なタスクを実行できます。
OctoGTA:グランド・セフト・オート(GTA)ゲームに基づいて、合計20のミッションが構築され、5つの異なるシナリオに一般化されています。 あらかじめ設定されたプログラムでプレイヤーを固定位置に設定し、ミッションを完了するために必要なアイテムとNPCを提供して、ミッションをスムーズに実行できるようにします。
次の図は、OctoGibson のタスク分類と、OctoGibson と OctoGTA の統計の一部を示しています。
(Reinforcement Learning with Environmental Feedback)は、以前に収集したサブタスクの成功を報酬信号とし、強化学習アルゴリズムを用いてVLMのタスク計画能力をさらに向上させることで、タスクの全体的な成功率を向上させます。
実験結果
研究者らは、OctoGibson環境で現在主流のVLMとLLMをテストし、次の表に主な実験結果を示します。 異なるテストモデルの場合、ビジョンモデルは異なるモデルで使用されるビジュアルモデルを列挙し、LLMの場合、研究者はLLMへの入力として視覚情報をテキストとして処理します。 ここで、O はシーン内の対話可能なオブジェクトに関する情報を提供することを意味し、R はシーン内のオブジェクトの相対的な関係に関する情報を提供することを意味し、GT は検出のための追加の視覚モデルを導入することなく、実際の正確な情報を使用することを表します。
すべてのテストタスクについて、研究者は完全なテスト統合能力を報告し、さらに4つのカテゴリに分類し、トレーニングセットに存在するシナリオで新しいタスクを完了する能力、トレーニングセットに存在しないシナリオで新しいタスクを完了する汎化能力、および単純なフォロータスクと複雑な推論タスクを完了する汎化能力を記録しました。 統計の各カテゴリーについて、研究者は2つの評価指標を報告し、そのうちの1つはタスクの完了率であり、具体化された知能タスクを完了する際のモデルの成功率を測定しました。 2つ目は、タスクを計画するモデルの能力を反映するために使用されるタスク計画の精度です。
**1.CodeLLaMAは、モデルのコード生成能力を向上させることができますが、タスク計画能力を向上させることはできません。 **
研究者らは、CodeLLaMAがモデルのコード生成能力を大幅に向上させることができることを実験結果が示していると指摘しました。 従来のLLMと比較して、CodeLLaMAはより高い実行速度でより良いコードを可能にします。 ただし、一部のモデルではコード生成に CodeLLaMA を使用しますが、タスクの全体的な成功率は、タスク計画能力によって制限されます。 一方、Octopusは、CodeLLaMAの不足によりコードの実行率は低下していますが、タスク計画能力が強いため、全体的なタスク成功率は他のモデルよりも優れています。
**2.LLMは、大量のテキスト入力に直面して処理するのが難しいです。 **
実際のテストプロセスでは、TAPAとCodeLLaMAの実験結果を比較し、言語モデルが長いテキスト入力をうまく処理することは困難であるという結論に達しました。 研究者はTAPAのアプローチに従い、ミッション計画に実際の物体情報を使用し、CodeLLaMAは物体間の相対的な位置関係を使用してより完全な情報を提供しました。 しかし、実験の過程で、環境内の冗長な情報量が多いため、環境が複雑になるとテキスト入力が大幅に増加し、LLMが大量の冗長な情報から貴重な手がかりを抽出することが困難になり、タスクの成功率が低下することを発見しました。 これは、複雑なシナリオを表すためにテキスト情報を使用すると、冗長で価値のない入力が大量に発生する可能性があるというLLMの限界も反映しています。
3.タコは優れたタスク一般化能力を示しています。 **
実験結果から、Octopusはタスクを一般化する強力な能力を持っていると結論付けることができます。 トレーニング セットに表示されない新しいシナリオでのタスク完了とタスク計画の成功率は、既存のモデルの成功率よりも優れています。 これはまた、同じクラスのタスクに対して従来のLLMよりも一般化できるビジュアル言語モデルの固有の利点のいくつかを示しています。
実験結果では、教師あり微調整の第1段階のみを行ったモデルと、RLEFによってトレーニングされたモデルのパフォーマンスを比較しました。 RLEFのトレーニング後、強力な推論能力とタスク計画能力を必要とするタスクについて、モデルの全体的な成功率と計画能力が大幅に向上したことがわかります。 また、RLEFは既存のVLMトレーニング戦略よりもはるかに効率的です。 上の図に示した例は、RLEFトレーニング後のモデルのタスク計画能力の向上も示すことができます。 RLEFでトレーニングされたモデルは、より複雑なタスクに直面したときに環境をナビゲートする方法を理解でき、モデルはタスク計画の観点からシミュレーション環境の実際の要件により準拠しているため(たとえば、モデルは対話を開始する前にオブジェクトに移動して対話する必要があるため)、タスク計画の失敗率が低下します。
ディスカッション
アブレーション実験
モデルの実際の機能を評価した後、研究者はモデルのパフォーマンスに影響を与える可能性のあるいくつかの要因を詳しく調べました。 下図のように、3つの側面から実験を行いました。
研究者らは、言語モデルのみで学習した接続層、学習済みの接続層と言語モデル、および完全に学習したモデルのパフォーマンスを比較しました。 トレーニングパラメータの増加に伴い、モデルのパフォーマンスが徐々に向上していることがわかります。 これは、トレーニング パラメーターの数が、一部の固定シナリオでモデルがタスクを完了できるかどうかにとって重要であることを示しています。
2.モデルのサイズ
研究者らは、2つのトレーニングフェーズで、より小さい3Bパラメータモデルとベースライン7Bモデルのパフォーマンスを比較しました。 比較により、モデルの全体的なパラメータが大きい場合、モデルのパフォーマンスも大幅に向上することがわかります。 モデルが対応するタスクを完了する能力を持つと同時に、モデルの軽量で高速な推論速度を確保できるように、適切なモデルトレーニングパラメータを選択する方法は、VLM分野の将来の研究の重要なポイントになります。
さまざまな視覚入力が実際のVLMの性能に与える影響を調べるために、研究者らは視覚情報の入力順序を実験しました。 テスト中、モデルはシミュレーション環境内で順番に回転し、一人称視点と2つの鳥瞰図をキャプチャし、VLMに順次入力します。 この実験では、研究者が視覚画像の順序をランダムにシャッフルしてVLMに入力すると、VLMによって性能が大幅に低下しました。 これは、VLMにとって完全で構造化された視覚情報の重要性を示す一方で、VLMが視覚入力に応答する視覚イメージの内部接続に依存しており、この視覚的接続が壊れるとVLMのパフォーマンスに大きな影響を与えることをある程度反映しています。
さらに、研究者らは、シミュレートされた環境でGPT-4とGPT-4Vのパフォーマンスをテストおよび計算しました。
1.GPT-4(英語)
GPT-4の場合、研究者は、トレーニングデータを収集するためにGPT-4を使用する場合とまったく同じテキスト情報をテスト中に入力として提供します。 GPT-4はテストタスクの半分をこなすことができ、GPT-4のような言語モデルと比較して、既存のVLMにはまだまだ性能改善の余地があることを示しており、一方で、GPT-4のような強力なパフォーマンスを持つ言語モデルであっても、具体化された知能タスクに直面した場合、タスク計画とタスク実行能力をさらに向上させる必要があることも示しています。
2.GPT-4V
GPT-4Vは直接呼び出せるAPIをリリースしたばかりなので、研究者はまだ試す時間がありませんでしたが、研究者はGPT-4Vの性能を実証するために、いくつかの例を手動でテストしています。 研究者らは、いくつかの例を通じて、GPT-4Vはシミュレーション環境のタスクに対して強力なゼロショット汎化能力を持ち、視覚的な入力に基づいて対応する実行可能コードを生成することもできますが、一部のタスク計画ではシミュレーション環境で収集されたデータに基づいて微調整されたモデルよりもわずかに劣ると考えています。
まとめ
研究者らは、現在の研究のいくつかの限界を指摘している。
1.現在のOctopusモデルは、より複雑なタスクには不十分です。 複雑なタスクに直面すると、Octopusはしばしば誤った計画を立て、環境からのフィードバックに大きく依存し、タスク全体を完了するのに苦労することがよくあります。
2.Octopusモデルはシミュレーション環境でしか学習しておらず、それらを現実世界にどのように移行するかは一連の問題に直面します。 例えば、現実環境では、物体の相対的な位置について、モデルがより正確な情報を得ることが難しくなり、物体の理解をシーンにどう組み込んでいくかが難しくなります。