来源:量子位 *画像出典:Unbounded AIによって生成*> 意外なことに、OpenAIは「競合」のStable Diffusionを利用しました。ホットな「AI Spring Festival Gala」で、OpenAIは2つの作品を一度にオープンソース化し、そのうちの1つはSDのVAEモデル専用の**Consistency Decoder**です。これにより、複数の顔、テキストを含む画像、線制御など、より高品質で安定した画像生成が可能になります。 Big Vブロガーは、このデコーダーは**Dall· 同じモデル**のE 3では、GitHubプロジェクトページでOpenAIはDall· E 3 論文。  特にサポートされているバージョンは Stable Diffusion 1.4/1.5 です。プロジェクトページには例が1つしかなく、具体的なトレーニングは書かれておらず、「あまり話さない人によるオープンソース」と呼ばれています。> 読み込んで使用するだけです。 そして、このコヒーレントなデコーダーには多くの魅力があります。これは、OpenAIの共同開発者兼チーフサイエンティストであるIlya氏と、OpenAIの中国の新星であるSong Yang氏が提案した一貫性モデルから来ています。このモデルがオープンソース化された上半期には業界に衝撃を与え、「エンドディフュージョンモデル」と評価されました。少し前に、Song Yang らはモデル トレーニング方法も最適化し、画像生成の品質をさらに向上させることができました。 開発者の日のもう一つの大きなオープンソースは、Whisper 3音声モデルです。 また、アレック・ラドフォードがGPTシリーズの構築に重要な役割を果たした伝説の作品でもあります。ネチズンはため息をつかずにはいられません:私は今でもOpenAIがオープンソースになるのを見るのが大好きで、より多くのモデルを公開し続けることを楽しみにしています。 ## **整合性モデルが再進化を完了**まず、コンシステンシ・モデルの最初のバージョンから見ていきましょう。これは、拡散モデルの段階的な反復によって引き起こされる画像生成の遅延の問題を解決するように設計されています。 約 256×256 の 64 枚の画像を生成するのに 3.5 秒しかかかりません。 拡散モデルに比べて、主に2つの利点があります。第 1 に、敵対的トレーニングなしで高品質の画像サンプルを直接生成できます。第 2 に、数百回または数千回の反復を必要とする拡散モデルと比較して、一貫性モデルは 1 つまたは 2 つのステップでさまざまな画像タスクを完了します。カラーリング、ノイズ除去、超解像などはすべて、これらのタスクのための明示的なトレーニングを必要とせずに、いくつかのステップで行うことができます。 (勿論、少ないショット数で学習した方が生成効果は良いです)原理的には、一貫性モデルはランダムノイズを複素画像に直接マッピングし、出力は同じ軌跡上の同じ点であるため、ワンステップ生成を実現します。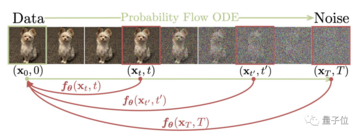 この論文では、2つの学習方法を提案しており、1つは、事前に学習された拡散モデルを使用して隣接するデータペアを生成する一貫性蒸留に基づく方法と、モデル出力間の差を最小限に抑えることで一貫性のあるモデルを学習する方法です。もう 1 つのアプローチは、一貫性のあるモデルが独立して生成されたモデルとしてトレーニングされる独立トレーニングです。実験結果によると、コンシステンシーモデルは、ワンステップおよびローステップサンプリングの点で、プログレッシブ蒸留などの既存の蒸留技術よりも優れていることが示されています。スタンドアロンのジェネレーティブモデルとしてトレーニングした場合、CIFAR-10、ImageNet 64×64、LSUN 256×256などの標準的なベンチマーク集計の既存のワンステップ非敵対的ジェネレーティブモデルと一貫性のあるモデルを比較できます。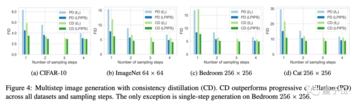 半年後に発表された論文の第2版では、**トレーニング方法が最適化されています**。重み関数、ノイズ埋め込み、ドロップアウトを最適化することで、学習した特徴量に依存することなく、一貫性のあるモデルで良好な生成品質を実現できます。これにより、ノイズレベルが増加するにつれて重み関数の選択が減少し、その結果、ノイズレベルが小さいほど一貫性の損失の重みが大きくなり、サンプルの品質が向上します。同時に、ノイズ埋め込み層の感度を調整して、小さなノイズ差に対する感度を低下させ、連続時間整合性トレーニングの安定性を向上させるのに役立ちます。コンセンサスモデルでは、大きなドロップアウトを使用し、教師ネットワークからEMAを除去し、Pseudo-Huber損失関数を学習した特徴距離(LPIPSなど)に置き換えることで、画質をさらに向上させることができることがわかりました。 ## **もう1つ**最新のオープンソースデコーダーに話を戻すと、測定されたエクスペリエンスの最初の波がやってきました。現在、見られる効果のいくつかは明白ではなく、多くの人が走行速度が遅いと報告しています。しかし、これはまだ最も初期のテストであり、将来的にはさらに改善される可能性があります。 特筆すべきは、コンシステンシーモデルの立ち上げを主導したSong Yang氏は若いが、拡散モデル界隈ではOG(ベテラン)と評価されていることだ。 **△**Nvidia の AI サイエンティスト、Jim Fan の Twitter より今年は、一貫性モデルで、ソンヤンも有名です。 この大男は、16歳で清華大学に科学のトップの学生として入学し、彼に関するより多くの話を突くことができます:OpenAIの人気新星Song Yang:最新の研究は「終末拡散モデル」を受賞し、彼は16歳で清華大学に行きました住所: [1] [2]


OpenAIが安定した拡散を救う! 同じデコーダーを備えたE3、Ilya Song Yangなど
来源:量子位
ホットな「AI Spring Festival Gala」で、OpenAIは2つの作品を一度にオープンソース化し、そのうちの1つはSDのVAEモデル専用のConsistency Decoderです。
これにより、複数の顔、テキストを含む画像、線制御など、より高品質で安定した画像生成が可能になります。
プロジェクトページには例が1つしかなく、具体的なトレーニングは書かれておらず、「あまり話さない人によるオープンソース」と呼ばれています。
これは、OpenAIの共同開発者兼チーフサイエンティストであるIlya氏と、OpenAIの中国の新星であるSong Yang氏が提案した一貫性モデルから来ています。
このモデルがオープンソース化された上半期には業界に衝撃を与え、「エンドディフュージョンモデル」と評価されました。
少し前に、Song Yang らはモデル トレーニング方法も最適化し、画像生成の品質をさらに向上させることができました。
ネチズンはため息をつかずにはいられません:私は今でもOpenAIがオープンソースになるのを見るのが大好きで、より多くのモデルを公開し続けることを楽しみにしています。
整合性モデルが再進化を完了
まず、コンシステンシ・モデルの最初のバージョンから見ていきましょう。
これは、拡散モデルの段階的な反復によって引き起こされる画像生成の遅延の問題を解決するように設計されています。 約 256×256 の 64 枚の画像を生成するのに 3.5 秒しかかかりません。
第 1 に、敵対的トレーニングなしで高品質の画像サンプルを直接生成できます。
第 2 に、数百回または数千回の反復を必要とする拡散モデルと比較して、一貫性モデルは 1 つまたは 2 つのステップでさまざまな画像タスクを完了します。
カラーリング、ノイズ除去、超解像などはすべて、これらのタスクのための明示的なトレーニングを必要とせずに、いくつかのステップで行うことができます。 (勿論、少ないショット数で学習した方が生成効果は良いです)
原理的には、一貫性モデルはランダムノイズを複素画像に直接マッピングし、出力は同じ軌跡上の同じ点であるため、ワンステップ生成を実現します。
もう 1 つのアプローチは、一貫性のあるモデルが独立して生成されたモデルとしてトレーニングされる独立トレーニングです。
実験結果によると、コンシステンシーモデルは、ワンステップおよびローステップサンプリングの点で、プログレッシブ蒸留などの既存の蒸留技術よりも優れていることが示されています。
スタンドアロンのジェネレーティブモデルとしてトレーニングした場合、CIFAR-10、ImageNet 64×64、LSUN 256×256などの標準的なベンチマーク集計の既存のワンステップ非敵対的ジェネレーティブモデルと一貫性のあるモデルを比較できます。
重み関数、ノイズ埋め込み、ドロップアウトを最適化することで、学習した特徴量に依存することなく、一貫性のあるモデルで良好な生成品質を実現できます。
これにより、ノイズレベルが増加するにつれて重み関数の選択が減少し、その結果、ノイズレベルが小さいほど一貫性の損失の重みが大きくなり、サンプルの品質が向上します。
同時に、ノイズ埋め込み層の感度を調整して、小さなノイズ差に対する感度を低下させ、連続時間整合性トレーニングの安定性を向上させるのに役立ちます。
コンセンサスモデルでは、大きなドロップアウトを使用し、教師ネットワークからEMAを除去し、Pseudo-Huber損失関数を学習した特徴距離(LPIPSなど)に置き換えることで、画質をさらに向上させることができることがわかりました。
もう1つ
最新のオープンソースデコーダーに話を戻すと、測定されたエクスペリエンスの最初の波がやってきました。
現在、見られる効果のいくつかは明白ではなく、多くの人が走行速度が遅いと報告しています。
しかし、これはまだ最も初期のテストであり、将来的にはさらに改善される可能性があります。
今年は、一貫性モデルで、ソンヤンも有名です。 この大男は、16歳で清華大学に科学のトップの学生として入学し、彼に関するより多くの話を突くことができます:OpenAIの人気新星Song Yang:最新の研究は「終末拡散モデル」を受賞し、彼は16歳で清華大学に行きました
住所:
[1] [2]