記事のソース: Heart of the Machine> ChatGPTの成功は、RLHFの「秘密兵器」と切り離せないことがわかっています。 ただし、RLHFは完璧ではなく、対処するのが難しい最適化の課題があります。 この論文では、スタンフォード大学などの研究機関のチームが、「強化学習」を、速度と性能の点で優れた性能を持つ「コントラスト優先学習」に置き換えることを検討しています。 画像ソース: Unbounded AIによって生成人間のフィードバックに基づく強化学習 (RLHF) は、モデルを人間の意図に合わせるという点で一般的なパラダイムになっています。 通常、RLHF アルゴリズムは 2 つのフェーズで機能します: 1 つ目は、人間の好みを使用して報酬関数を学習し、2 つ目は、強化学習を使用して学習した報酬を最適化することでモデルを調整します。RLHFパラダイムは、人間の選好の分布が報酬に従うことを前提としていますが、最近の研究ではそうではなく、人間の選好は実際にはユーザーの最適戦略の後悔値に従うことが示唆されています。 このように、フィードバックに基づく報酬関数の学習は、人間の嗜好に関する誤った仮定に基づいているだけでなく、強化学習における方策勾配やブートストラップから生じる手に負えない最適化パズルにもつながります。これらの最適化の課題のため、今日のRLHF手法は、コンテキストベースのバンディット設定(大規模言語モデルなど)または独自の観察次元(状態ベースのロボット工学など)に限定されています。これらの課題を克服するために、スタンフォード大学と他の大学の研究者チームは、コミュニティに広く受け入れられ、報酬の合計のみを考慮する部分的な報酬モデルではなく、後悔に基づく人間の選好モデルを使用して、人間のフィードバックを使用する際の行動を最適化できる一連の新しいアルゴリズムを提案しました。 部分的リターンモデルとは異なり、後悔ベースのモデルは、最適な戦略に関する直接的な情報を提供します。このようなメカニズムは、強化学習が不要になったという幸運な結果をもたらしました。このように、RLHF問題は、高次元状態と行動空間を持つ汎用MDPフレームワークで解くことができます。研究者らは、後悔に基づく選好フレームワークと最大エントロピーの原理(MaxEnt)を組み合わせることで、支配的な関数と戦略の間の全単射を得ることができるという研究結果の核となる洞察を提案しました。 アドバンテージの最適化をストラテジーの最適化に置き換えることで、純粋な教師あり学習の目標を導き出すことができ、その最適値はエキスパート報酬の下での最適ストラテジーである。 研究チームは、このアプローチをコントラスティブ・プリファレンス・ラーニング(CPL)と名付けました。 *住所:* コードアドレス:CPLには、従来のアプローチに比べて3つの重要な利点があります。まず、CPLは、戦略的勾配や動的プログラミングを使用せずに、教師あり目標のみを使用して最適な強みを一致させるため、教師あり学習のようにスケーリングされます。第 2 に、CPL は完全にポリシーから外れたアプローチであるため、オフラインの最適でないデータ ソースを効果的に使用できます。第3に、CPLは任意のマルコフ決定プロセス(MDP)に適用できるため、配列データに対する選好クエリから学習することができます。研究チームによると、これまでのRLHF法はいずれもこれら3つの基準をすべて満たしていなかった。 CPL法が上記3つの記述に合致することを示すために、研究者らは実験を行い、その結果、この手法が準最適で高次元の解離戦略データを持つ逐次意思決定問題に効果的に対処できることを示しました。注目すべきは、CPLがMetaWorldベンチマークの会話モデルと同じRLHF微調整プロセスを使用して、時間の経過とともに拡張する運用戦略を効果的に学習できることがわかったことです。具体的には、教師あり学習アプローチを使用して、高次元画像観測に関する戦略を事前にトレーニングし、好みを使用して微調整します。 動的計画法や方策勾配を必要とせずに、CPLはアプリオリな強化学習ベースのアプローチと同じパフォーマンスを達成できます。 同時に、CPL法は1.6倍速く、パラメータ効率は4倍高速です。 より集中的な選好データを使用した場合、CPLのパフォーマンスは、6つのタスクのうち5つで強化学習を上回りました。## **対照的選好学習**このアプローチの核となる考え方は単純で、最大エントロピー強化学習フレームワークを使用すると、後悔選好モデルで使用される優位関数を戦略の対数確率に簡単に置き換えることができることを発見しました。 ただし、この単純な交換は大きなメリットをもたらします。 ストラテジーの対数確率を使用する場合、アドバンテージ関数を学習したり、強化型学習アルゴリズムに関連する最適化問題に対処したりする必要はありません。これにより、より緊密に連携した後悔選好モデルが作成されるだけでなく、人間のフィードバックから学習するための教師あり学習に完全に依存することもできると研究者は述べています。CPLターゲットが最初に導出され、有界データを持つエキスパートユーザー報酬関数r\_Eに対して、メソッドが最適な戦略に収束することが示されています。 次に、CPLと他の教師あり学習方法との関連性について説明します。 最後に、調査員はCPLを実際にどのように使用できるかを説明します。 これらのアルゴリズムは、逐次的な意思決定問題を解くための新しいカテゴリーに属しており、強化学習を必要とせずに後悔に基づく選好から直接戦略を学習できるため、非常に効率的であるとのことです。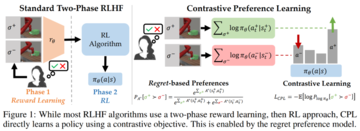 **最適なアドバンテージから最適な戦略へ**後悔選好モデルを使用する場合、選好データセット D\_pref には、最適優位関数 A^∗ (s, a) に関する情報が含まれます。 この関数は、状態 s の最適戦略によって生成されたアクションよりも、特定のアクションに対して a がどの程度悪いかを測定すると直感的に考えることができます。したがって、定義上、最適優位を最大化する行動が最適行動であり、その選好から最適優位関数を学習することで、直感的に最適な戦略を抽出できるはずです。具体的には、以下の定理を証明しました。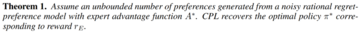 直接学習戦略の利点: この方法でπを直接学ぶことには、多くの実用的および理論的な利点があります。 最も明白なのは、戦略を直接学ぶ場合、報酬関数や価値関数などの他の関数を学ぶ必要がないことです。 これにより、CPLは以前の方法よりもはるかに簡単になります。コントラスティブ学習への接続。 CPLアプローチは、戦略学習に比較目標を直接使用します。 研究者らは、大規模なデータセットとニューラルネットワークによるコントラスティブ学習目標の成功が実証されていることから、CPLは従来の強化学習アルゴリズムを使用した強化学習手法よりも優れた拡張性を発揮することを期待していると述べています。**実用上の考慮事項**コントラスティブ選好学習フレームワークは、強度ベースの選好から戦略を学習するために使用できる汎用的な損失関数を提供し、そこから多くのアルゴリズムを導き出すことができます。 以下は、適切に機能する特定のCPLフレームワークの実際の例です。オフライン データが限られている CPL。 CPLは、無制限の選好データを使用して最適な戦略に収束できますが、実際には、一般的に、限られたオフラインデータセットからの学習に関心があります。 この設定では、データセットのサポートをはるかに超えて推定するポリシーは、実行されるアクションによって分散状態になるため、パフォーマンスが低下します。本格化。 有限の設定では、CPL損失関数を最小化し、そのデータセット内のアクションにより高い確率を与える戦略を選択します。 これを行うために、研究者は保守的な正則化器を使用して、次の損失関数を取得します:戦略がD\_prefでアクションの確率が高い場合、より低い損失が割り当てられ、分布内に収まるようにします。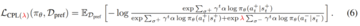 事前トレーニング。 研究チームは、より良い結果を得るために、ポリシー π\_θが行動クローニング(BC)アプローチを使用して事前にトレーニングされていることを発見しました。 そこで、CPL損失の使用設定を微調整する前に、チームは標準的な最尤クローニングターゲットを使用して戦略をトレーニングしました。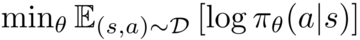 ## **実験と結果**このセクションでは、CPLに関する次の質問に回答します: 1. CPLは後悔に基づく選好に基づいてポリシーを効果的に微調整できますか?2. CPLは、高次元の制御問題や大規模なネットワークに合わせて拡張できますか?3. 高いパフォーマンスを達成するために重要なCPLのコンポーネントは何ですか?嗜好データ。 研究者らは、最適ではない解離性ロールアウトデータと選好を用いて、CPLがジェネリックMDPの戦略を学習する能力を評価した。ベンチマーク手法。 実験では、教師あり微調整 (SFT)、選好暗黙的 Q 学習 (P-IQL)、% BC (ロールアウトの上位 X% の行動クローニングによるポリシーのトレーニング) の 3 つのベンチマーク手法が考慮されました。CPLのパフォーマンスはどうですか?状態ベースの観測値を使用する場合、CPLはどのように機能しますか? 状態ベースの実験結果については、表 1 の行 1 と 3 が主に表示されます。よりまばらな比較データ(行3)を使用した場合、CPLは6つの環境のうち5つで以前のアプローチよりも優れており、P-IQLに対する利点は、特にボタン押下、ビンピッキング、およびスイープインの環境でほぼ明らかでした。 より集中的な比較を行うデータセットに適用すると、CPL は P-IQL (行 1) よりもさらに有利であり、すべてのコンテキストで有意です。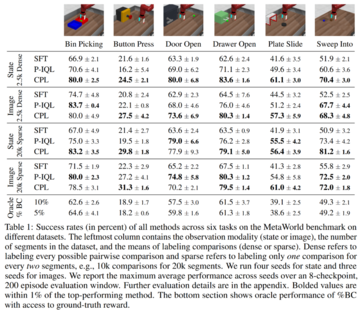 CPLの監視対象を高次元の連続制御問題に拡張できるかどうかをテストするために、チームはMetaWorldデータセットを64×64の画像にレンダリングしました。表 1 の 2 行目と 4 行目は、画像ベースの実験の結果を示しています。 その結果、SFTではパフォーマンスがわずかに向上しましたが、P-IQLの改善が顕著でした。 より集中的な選好データを学習した場合(行2)、CPLは6つの環境のうち4つでP-IQLを上回り、スイープインの両方で同等でした。 よりまばらな比較データを学習する場合(行4)、CPLとP-IQLはほとんどのタスクで同等に実行されました。これは、CPLの複雑さが大幅に低いことを考えると、さらに印象的です。 P-IQLは、報酬関数、Q関数、価値関数、および戦略を学習する必要があります。 CPLはそれらのどれも必要とせず、単一の戦略を学習するだけでよいため、トレーニング時間とパラメータの数が大幅に削減されます。以下の表 2 に示すように、CPL は画像タスクで P-IQL の 1.62 倍の速度で実行され、パラメーター数は 4 分の 1 未満です。 ネットワークが成長するにつれて、CPLの使用によるパフォーマンスの向上は向上する一方です。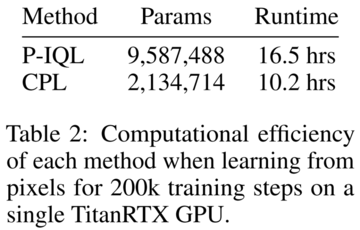 CPLのパフォーマンスに寄与するコンポーネントは何ですか?実験結果からわかるように、CPLとベンチマーク法のギャップは、より集中的に比較するデータセットを使用する場合に大きくなります。 これは、コントラスティブ学習におけるこれまでの研究結果と一致しています。この効果を調査するために、5,000フラグメントの固定サイズのデータセットに基づいて、フラグメントごとにサンプリングされる比較の数を増やすことによってCPLのパフォーマンスを評価しました。 下の図2は、状態ベースの観測値のドロワーオープンタスクの結果を示しています。全体として、CPLは、プレートスライドタスクを除いて、クリップごとにサンプリングされる比較の数が増えると有利になります。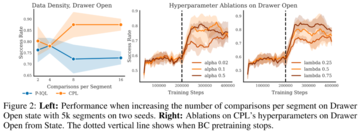 最後に、CPL(温度値αとバイアス正則化器λ)のハイパーパラメータのアブレーション研究も行いましたが、これもオープンドロワータスクに基づいており、その結果を図2の右側に示します。 CPLはこれらの値でうまく機能しますが、実験では、ハイパーパラメータ、特にλを適切に調整することでさらに優れたパフォーマンスを発揮できることがわかっています。


スタンフォード大学が提案する対照選好学習:強化学習を伴わない人間のフィードバックからの学習
記事のソース: Heart of the Machine
人間のフィードバックに基づく強化学習 (RLHF) は、モデルを人間の意図に合わせるという点で一般的なパラダイムになっています。 通常、RLHF アルゴリズムは 2 つのフェーズで機能します: 1 つ目は、人間の好みを使用して報酬関数を学習し、2 つ目は、強化学習を使用して学習した報酬を最適化することでモデルを調整します。
RLHFパラダイムは、人間の選好の分布が報酬に従うことを前提としていますが、最近の研究ではそうではなく、人間の選好は実際にはユーザーの最適戦略の後悔値に従うことが示唆されています。 このように、フィードバックに基づく報酬関数の学習は、人間の嗜好に関する誤った仮定に基づいているだけでなく、強化学習における方策勾配やブートストラップから生じる手に負えない最適化パズルにもつながります。
これらの最適化の課題のため、今日のRLHF手法は、コンテキストベースのバンディット設定(大規模言語モデルなど)または独自の観察次元(状態ベースのロボット工学など)に限定されています。
これらの課題を克服するために、スタンフォード大学と他の大学の研究者チームは、コミュニティに広く受け入れられ、報酬の合計のみを考慮する部分的な報酬モデルではなく、後悔に基づく人間の選好モデルを使用して、人間のフィードバックを使用する際の行動を最適化できる一連の新しいアルゴリズムを提案しました。 部分的リターンモデルとは異なり、後悔ベースのモデルは、最適な戦略に関する直接的な情報を提供します。
このようなメカニズムは、強化学習が不要になったという幸運な結果をもたらしました。
このように、RLHF問題は、高次元状態と行動空間を持つ汎用MDPフレームワークで解くことができます。
研究者らは、後悔に基づく選好フレームワークと最大エントロピーの原理(MaxEnt)を組み合わせることで、支配的な関数と戦略の間の全単射を得ることができるという研究結果の核となる洞察を提案しました。 アドバンテージの最適化をストラテジーの最適化に置き換えることで、純粋な教師あり学習の目標を導き出すことができ、その最適値はエキスパート報酬の下での最適ストラテジーである。 研究チームは、このアプローチをコントラスティブ・プリファレンス・ラーニング(CPL)と名付けました。
CPLには、従来のアプローチに比べて3つの重要な利点があります。
まず、CPLは、戦略的勾配や動的プログラミングを使用せずに、教師あり目標のみを使用して最適な強みを一致させるため、教師あり学習のようにスケーリングされます。
第 2 に、CPL は完全にポリシーから外れたアプローチであるため、オフラインの最適でないデータ ソースを効果的に使用できます。
第3に、CPLは任意のマルコフ決定プロセス(MDP)に適用できるため、配列データに対する選好クエリから学習することができます。
研究チームによると、これまでのRLHF法はいずれもこれら3つの基準をすべて満たしていなかった。 CPL法が上記3つの記述に合致することを示すために、研究者らは実験を行い、その結果、この手法が準最適で高次元の解離戦略データを持つ逐次意思決定問題に効果的に対処できることを示しました。
注目すべきは、CPLがMetaWorldベンチマークの会話モデルと同じRLHF微調整プロセスを使用して、時間の経過とともに拡張する運用戦略を効果的に学習できることがわかったことです。
具体的には、教師あり学習アプローチを使用して、高次元画像観測に関する戦略を事前にトレーニングし、好みを使用して微調整します。 動的計画法や方策勾配を必要とせずに、CPLはアプリオリな強化学習ベースのアプローチと同じパフォーマンスを達成できます。 同時に、CPL法は1.6倍速く、パラメータ効率は4倍高速です。 より集中的な選好データを使用した場合、CPLのパフォーマンスは、6つのタスクのうち5つで強化学習を上回りました。
対照的選好学習
このアプローチの核となる考え方は単純で、最大エントロピー強化学習フレームワークを使用すると、後悔選好モデルで使用される優位関数を戦略の対数確率に簡単に置き換えることができることを発見しました。 ただし、この単純な交換は大きなメリットをもたらします。 ストラテジーの対数確率を使用する場合、アドバンテージ関数を学習したり、強化型学習アルゴリズムに関連する最適化問題に対処したりする必要はありません。
これにより、より緊密に連携した後悔選好モデルが作成されるだけでなく、人間のフィードバックから学習するための教師あり学習に完全に依存することもできると研究者は述べています。
CPLターゲットが最初に導出され、有界データを持つエキスパートユーザー報酬関数r_Eに対して、メソッドが最適な戦略に収束することが示されています。 次に、CPLと他の教師あり学習方法との関連性について説明します。 最後に、調査員はCPLを実際にどのように使用できるかを説明します。 これらのアルゴリズムは、逐次的な意思決定問題を解くための新しいカテゴリーに属しており、強化学習を必要とせずに後悔に基づく選好から直接戦略を学習できるため、非常に効率的であるとのことです。
後悔選好モデルを使用する場合、選好データセット D_pref には、最適優位関数 A^∗ (s, a) に関する情報が含まれます。 この関数は、状態 s の最適戦略によって生成されたアクションよりも、特定のアクションに対して a がどの程度悪いかを測定すると直感的に考えることができます。
したがって、定義上、最適優位を最大化する行動が最適行動であり、その選好から最適優位関数を学習することで、直感的に最適な戦略を抽出できるはずです。
具体的には、以下の定理を証明しました。
コントラスティブ学習への接続。 CPLアプローチは、戦略学習に比較目標を直接使用します。 研究者らは、大規模なデータセットとニューラルネットワークによるコントラスティブ学習目標の成功が実証されていることから、CPLは従来の強化学習アルゴリズムを使用した強化学習手法よりも優れた拡張性を発揮することを期待していると述べています。
実用上の考慮事項
コントラスティブ選好学習フレームワークは、強度ベースの選好から戦略を学習するために使用できる汎用的な損失関数を提供し、そこから多くのアルゴリズムを導き出すことができます。 以下は、適切に機能する特定のCPLフレームワークの実際の例です。
オフライン データが限られている CPL。 CPLは、無制限の選好データを使用して最適な戦略に収束できますが、実際には、一般的に、限られたオフラインデータセットからの学習に関心があります。 この設定では、データセットのサポートをはるかに超えて推定するポリシーは、実行されるアクションによって分散状態になるため、パフォーマンスが低下します。
本格化。 有限の設定では、CPL損失関数を最小化し、そのデータセット内のアクションにより高い確率を与える戦略を選択します。 これを行うために、研究者は保守的な正則化器を使用して、次の損失関数を取得します:戦略がD_prefでアクションの確率が高い場合、より低い損失が割り当てられ、分布内に収まるようにします。
実験と結果
このセクションでは、CPLに関する次の質問に回答します: 1. CPLは後悔に基づく選好に基づいてポリシーを効果的に微調整できますか?2. CPLは、高次元の制御問題や大規模なネットワークに合わせて拡張できますか?3. 高いパフォーマンスを達成するために重要なCPLのコンポーネントは何ですか?
嗜好データ。 研究者らは、最適ではない解離性ロールアウトデータと選好を用いて、CPLがジェネリックMDPの戦略を学習する能力を評価した。
ベンチマーク手法。 実験では、教師あり微調整 (SFT)、選好暗黙的 Q 学習 (P-IQL)、% BC (ロールアウトの上位 X% の行動クローニングによるポリシーのトレーニング) の 3 つのベンチマーク手法が考慮されました。
CPLのパフォーマンスはどうですか?
状態ベースの観測値を使用する場合、CPLはどのように機能しますか? 状態ベースの実験結果については、表 1 の行 1 と 3 が主に表示されます。
よりまばらな比較データ(行3)を使用した場合、CPLは6つの環境のうち5つで以前のアプローチよりも優れており、P-IQLに対する利点は、特にボタン押下、ビンピッキング、およびスイープインの環境でほぼ明らかでした。 より集中的な比較を行うデータセットに適用すると、CPL は P-IQL (行 1) よりもさらに有利であり、すべてのコンテキストで有意です。
表 1 の 2 行目と 4 行目は、画像ベースの実験の結果を示しています。 その結果、SFTではパフォーマンスがわずかに向上しましたが、P-IQLの改善が顕著でした。 より集中的な選好データを学習した場合(行2)、CPLは6つの環境のうち4つでP-IQLを上回り、スイープインの両方で同等でした。 よりまばらな比較データを学習する場合(行4)、CPLとP-IQLはほとんどのタスクで同等に実行されました。
これは、CPLの複雑さが大幅に低いことを考えると、さらに印象的です。 P-IQLは、報酬関数、Q関数、価値関数、および戦略を学習する必要があります。 CPLはそれらのどれも必要とせず、単一の戦略を学習するだけでよいため、トレーニング時間とパラメータの数が大幅に削減されます。
以下の表 2 に示すように、CPL は画像タスクで P-IQL の 1.62 倍の速度で実行され、パラメーター数は 4 分の 1 未満です。 ネットワークが成長するにつれて、CPLの使用によるパフォーマンスの向上は向上する一方です。
実験結果からわかるように、CPLとベンチマーク法のギャップは、より集中的に比較するデータセットを使用する場合に大きくなります。 これは、コントラスティブ学習におけるこれまでの研究結果と一致しています。
この効果を調査するために、5,000フラグメントの固定サイズのデータセットに基づいて、フラグメントごとにサンプリングされる比較の数を増やすことによってCPLのパフォーマンスを評価しました。 下の図2は、状態ベースの観測値のドロワーオープンタスクの結果を示しています。
全体として、CPLは、プレートスライドタスクを除いて、クリップごとにサンプリングされる比較の数が増えると有利になります。