出典: Heart of the Machine 画像ソース: Unbounded AIによって生成人工知能の分野における最新の開発では、人間が生成したプロンプトの品質が、大規模言語モデル(LLM)の応答精度に決定的な影響を与えます。 OpenAI の推奨事項では、正確で詳細かつ具体的な質問が、これらの大規模言語モデルのパフォーマンスにとって重要であると述べています。 しかし、平均的なユーザーは、自分の質問がLLMにとって十分に明確であることを確認できるでしょうか?人間の自然な理解能力と、特定の状況での機械の解釈との間には明確な違いがあることに注意することが重要です。 例えば、「偶数月」という概念は、人間には2月や4月などの月を指しているように見えるかもしれませんが、GPT-4では日数が偶数の月と誤解される可能性があります。 これは、日常的な文脈を理解する上でのAIの限界を明らかにするだけでなく、これらの大規模言語モデルでより効果的にコミュニケーションする方法について考えるきっかけにもなります。 人工知能技術の継続的な進歩に伴い、言語理解における人間と機械のギャップをどのように埋めるかは、今後の研究にとって重要なトピックです。これを受けて、カリフォルニア大学ロサンゼルス校(UCLA)のGu Quanquan教授が率いるArtificial General Intelligence Labは、問題理解における大規模言語モデル(GPT-4など)の曖昧さに対する革新的な解決策を提案する研究レポートを発表しました。 この研究は、博士課程の学生であるYihe Deng氏、Weitong Zhang氏、Zixiang Chen氏によって行われました。 *住所:* プロジェクトの住所:このスキームの中核となるのは、大規模な言語モデルで、提起された質問を繰り返して拡張し、回答の精度を向上させることです。 この調査では、GPT-4によって再定式化された質問がより詳細になり、質問形式がより明確になったことがわかりました。 この言い換えと展開の方法により、モデルの回答の精度が大幅に向上します。 実験によると、質問をうまく言い直すと、回答の精度が50%からほぼ100%に向上することが示されています。 このパフォーマンスの向上は、大規模言語モデルが自己改善する可能性を示すだけでなく、AIが人間の言語をより効率的に処理し、理解する方法について新しい視点を提供します。 ## **メソッド** これらの知見に基づいて、研究者らは「質問を言い換えて拡張し、応答する」(RaR)という、シンプルだが効果的なプロンプト()を提案しています。 このプロンプトは、質問に対するLLMの回答の質を直接向上させ、問題処理の大幅な改善を示します。 研究チームは、GPT-4のような大規模モデルが問題を再認識する能力を最大限に活用するために、「2段階RaR」と呼ばれるRaRの変種も提案しています。 このアプローチは 2 つのステップに従います: まず、特定の問題に対して、特殊な言い換え LLM を使用して言い換えの問題が生成されます。 次に、元の質問と再話した質問を組み合わせて、応答LLMに回答を求めます。 ## **結果** 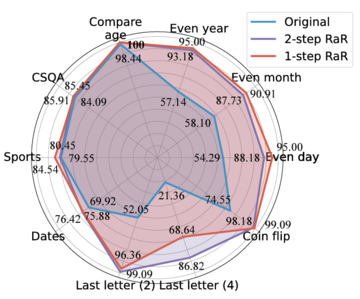 さまざまなタスクの実験では、GPT4の応答の精度を向上させる上で、(1ステップ)RaRと2ステップの両方で一貫した有効性が示されています。 特に、RaRはGPT-4では困難なタスクを大幅に改善しており、場合によっては100%に近い精度を示しています。 これに基づいて、研究チームは次の2つの重要な結論をまとめました。1. Repeat and Expand(RaR)は、プラグアンドプレイのブラックボックスアプローチでプロンプトを提供し、さまざまなタスクでLLMのパフォーマンスを効果的に向上させることができます。2. Q&A(QA)タスクにおけるLLMのパフォーマンスを評価する場合、質問の質をチェックすることが重要です。 さらに、研究者らは2段階のRaRを使用して、GPT-4、GPT-3.5、Vicuna-13b-v.15などのさまざまなモデルのパフォーマンスを調査しました。 実験結果によると、GPT-4など、より複雑なアーキテクチャとより強力な処理能力を持つモデルでは、RaR法によって問題処理の精度と効率が大幅に向上することが示されています。 Vicuna などの単純なモデルでは、程度は低いものの、RaR 戦略の有効性が実証されています。 これに基づいて、研究者は、さまざまなモデルを再話した後、質問の質をさらに調査しました。 より小さなモデルのリテリング問題では、質問の意図が乱れることがあります。 GPT-4などの高度なモデルが提供する言い換えの質問は、人間の意図とより一致し、他のモデルの応答を強化する傾向があります。 この発見は、言語モデルのリテリングの問題の質と有効性にレベルによって違いがあるという重要な現象を明らかにしています。 特にGPT-4のような高度なモデルは、問題をより明確に理解するために問題を再話すことができるだけでなく、他の小さなモデルのパフォーマンスを向上させるための効果的な入力としても機能します。 ## **思考の連鎖(CoT)との違い** RaRと思考の連鎖(CoT)の違いを理解するために、研究者たちは数学的定式化を考案し、RaRがCoTと数学的にどのように異なるか、そしてそれらをどのように簡単に組み合わせることができるかに光を当てました。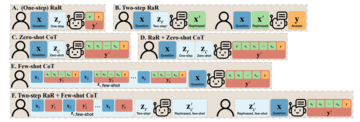 また、本研究は、モデルの推論能力を適切に評価するために、質問の質を向上させる必要があることを示唆しています。 例えば、「コイン投げ」の場合、GPT-4は人間の意図とは異なり、「投げる」という言葉をランダムなトスとして理解していることがわかりました。 この誤解は、ガイド付きモデルが推論に "段階的に考えよう" を使用する場合の推論プロセスに根強く残ります。 質問が明確になって初めて、大規模言語モデルは予想される質問に応答します。 さらに、研究者たちは、質問文に加えて、少数ショットのCoTに使われたQ&Aの例も人間によって書かれていることに気付きました。 ここで疑問が湧いてきます:大規模言語モデル(LLM)は、これらの人工的に構築された例に欠陥がある場合、どのように反応するのでしょうか? この研究は興味深い例を示しており、少数ショットのCoTの悪い例がLLMに悪影響を与える可能性があることを発見しました。 たとえば、Last Letter Concatenation タスクの場合、前に使用した問題の例では、モデルのパフォーマンスの向上に肯定的な結果が得られました。 しかし、最後の文字を見つけるから最初の文字を見つけるなど、プロンプトのロジックが変わると、GPT-4は間違った答えを出してしまいます。 この現象は、人間の例に対するモデルの感度を浮き彫りにしています。 研究者らは、RaRを使用することで、GPT-4が特定の例の論理的欠陥を修正し、それによってfew-shot CoTの品質と堅牢性を向上させることができることを発見しました。**結論**人間と大規模言語モデル(LLM)の間のコミュニケーションには誤解が生じる可能性があり、人間には明らかに見える質問が、大規模言語モデルでは他の質問として理解されることがあります。 UCLAの研究チームは、この質問に基づいて新しいアプローチとしてRaRを開発し、LLMが答える前に質問を繰り返して明確にするよう促しました。一連のベンチマークデータセットでのRaRの実験的評価により、そのアプローチの有効性が確認されました。 さらなる分析により、再話によって得られた問題の質の向上は、モデル間で転用できることがわかった。今後、RaRのような手法は今後も改善され続けると予想され、CoTなどの他の手法との統合により、人間と大規模言語モデル間のより正確で効果的な相互作用への道が開かれ、最終的にはAIの解釈と推論能力の限界を押し広げることになります。


GPT-4は、あなたよりも質問をすることが得意で、大規模なモデルに自律的に語り直してもらい、人間との対話の障壁を打ち破ります
出典: Heart of the Machine
人工知能の分野における最新の開発では、人間が生成したプロンプトの品質が、大規模言語モデル(LLM)の応答精度に決定的な影響を与えます。 OpenAI の推奨事項では、正確で詳細かつ具体的な質問が、これらの大規模言語モデルのパフォーマンスにとって重要であると述べています。 しかし、平均的なユーザーは、自分の質問がLLMにとって十分に明確であることを確認できるでしょうか?
人間の自然な理解能力と、特定の状況での機械の解釈との間には明確な違いがあることに注意することが重要です。 例えば、「偶数月」という概念は、人間には2月や4月などの月を指しているように見えるかもしれませんが、GPT-4では日数が偶数の月と誤解される可能性があります。 これは、日常的な文脈を理解する上でのAIの限界を明らかにするだけでなく、これらの大規模言語モデルでより効果的にコミュニケーションする方法について考えるきっかけにもなります。 人工知能技術の継続的な進歩に伴い、言語理解における人間と機械のギャップをどのように埋めるかは、今後の研究にとって重要なトピックです。
これを受けて、カリフォルニア大学ロサンゼルス校(UCLA)のGu Quanquan教授が率いるArtificial General Intelligence Labは、問題理解における大規模言語モデル(GPT-4など)の曖昧さに対する革新的な解決策を提案する研究レポートを発表しました。 この研究は、博士課程の学生であるYihe Deng氏、Weitong Zhang氏、Zixiang Chen氏によって行われました。
このスキームの中核となるのは、大規模な言語モデルで、提起された質問を繰り返して拡張し、回答の精度を向上させることです。 この調査では、GPT-4によって再定式化された質問がより詳細になり、質問形式がより明確になったことがわかりました。 この言い換えと展開の方法により、モデルの回答の精度が大幅に向上します。 実験によると、質問をうまく言い直すと、回答の精度が50%からほぼ100%に向上することが示されています。 このパフォーマンスの向上は、大規模言語モデルが自己改善する可能性を示すだけでなく、AIが人間の言語をより効率的に処理し、理解する方法について新しい視点を提供します。
メソッド
これらの知見に基づいて、研究者らは「質問を言い換えて拡張し、応答する」(RaR)という、シンプルだが効果的なプロンプト()を提案しています。 このプロンプトは、質問に対するLLMの回答の質を直接向上させ、問題処理の大幅な改善を示します。
結果
Repeat and Expand(RaR)は、プラグアンドプレイのブラックボックスアプローチでプロンプトを提供し、さまざまなタスクでLLMのパフォーマンスを効果的に向上させることができます。
Q&A(QA)タスクにおけるLLMのパフォーマンスを評価する場合、質問の質をチェックすることが重要です。
思考の連鎖(CoT)との違い
RaRと思考の連鎖(CoT)の違いを理解するために、研究者たちは数学的定式化を考案し、RaRがCoTと数学的にどのように異なるか、そしてそれらをどのように簡単に組み合わせることができるかに光を当てました。
結論
人間と大規模言語モデル(LLM)の間のコミュニケーションには誤解が生じる可能性があり、人間には明らかに見える質問が、大規模言語モデルでは他の質問として理解されることがあります。 UCLAの研究チームは、この質問に基づいて新しいアプローチとしてRaRを開発し、LLMが答える前に質問を繰り返して明確にするよう促しました。
一連のベンチマークデータセットでのRaRの実験的評価により、そのアプローチの有効性が確認されました。 さらなる分析により、再話によって得られた問題の質の向上は、モデル間で転用できることがわかった。
今後、RaRのような手法は今後も改善され続けると予想され、CoTなどの他の手法との統合により、人間と大規模言語モデル間のより正確で効果的な相互作用への道が開かれ、最終的にはAIの解釈と推論能力の限界を押し広げることになります。