記事のソース: 量子ビット *画像出典:Unbounded AIによって生成*Nvidia Lao Huang は、新世代の GPU チップ**H200** で再び爆発的に成長しました。公式サイトには、「AIとスーパーコンピューティングのために構築された世界で最も強力なGPU」とさりげなく書かれています。 すべてのAI企業がメモリ不足について不満を漏らしていると聞いたことがありますか?今回は、**141GB**の大容量メモリが、H100の80GBと比較して76%直接増加しています。HBM3eメモリを搭載した最初のGPUとして、メモリ帯域幅も3.35TB/sから4.8TB/sに増加し、43%増加しました。 AIにとっての意味とは?HBM3eのサポートにより、H200はLlama-70Bの推論性能をほぼ2倍にし、GPT3-175Bも60%向上させることができます。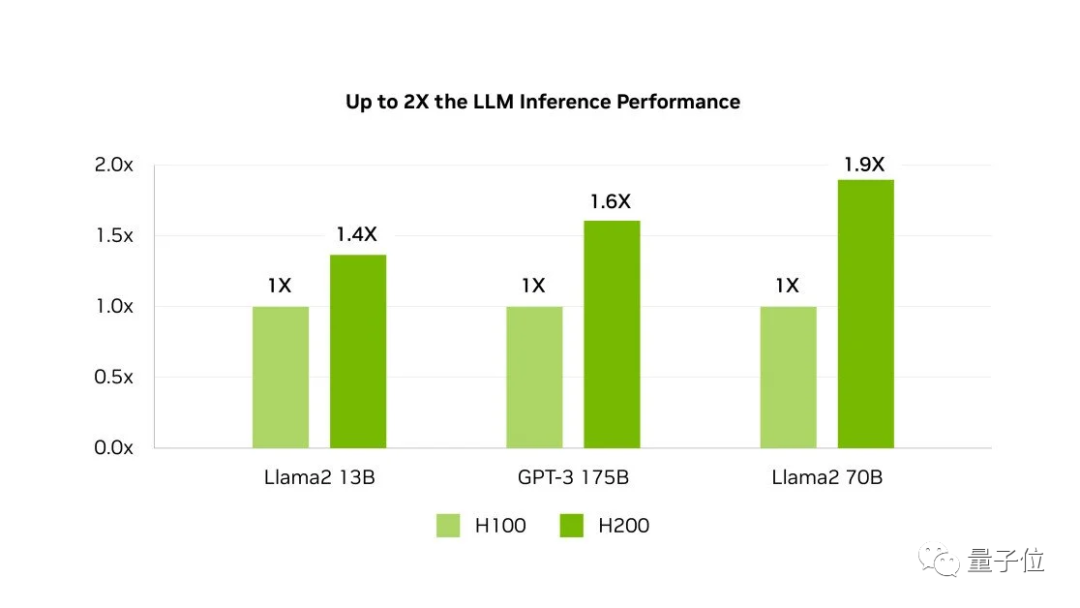 AI企業にとってもう一つ朗報があります。H200はH100と完全に互換性があるため、H200を既存のシステムに追加する際に調整は必要ありません。## **最強のAIチップは半年しか使えない**メモリのアップグレードを除けば、H200は基本的にH100と同じで、H100もHopperアーキテクチャに属しています。TSMCの4nmプロセス、800億個のトランジスタ、NVLink 4 900GB/秒の高速相互接続はすべて完全に継承されています。ピーク時の計算能力も変わらず、FP64 Vector 33.5TFlopsとFP64 Tensor 66.9TFlopsでデータも馴染みがあります。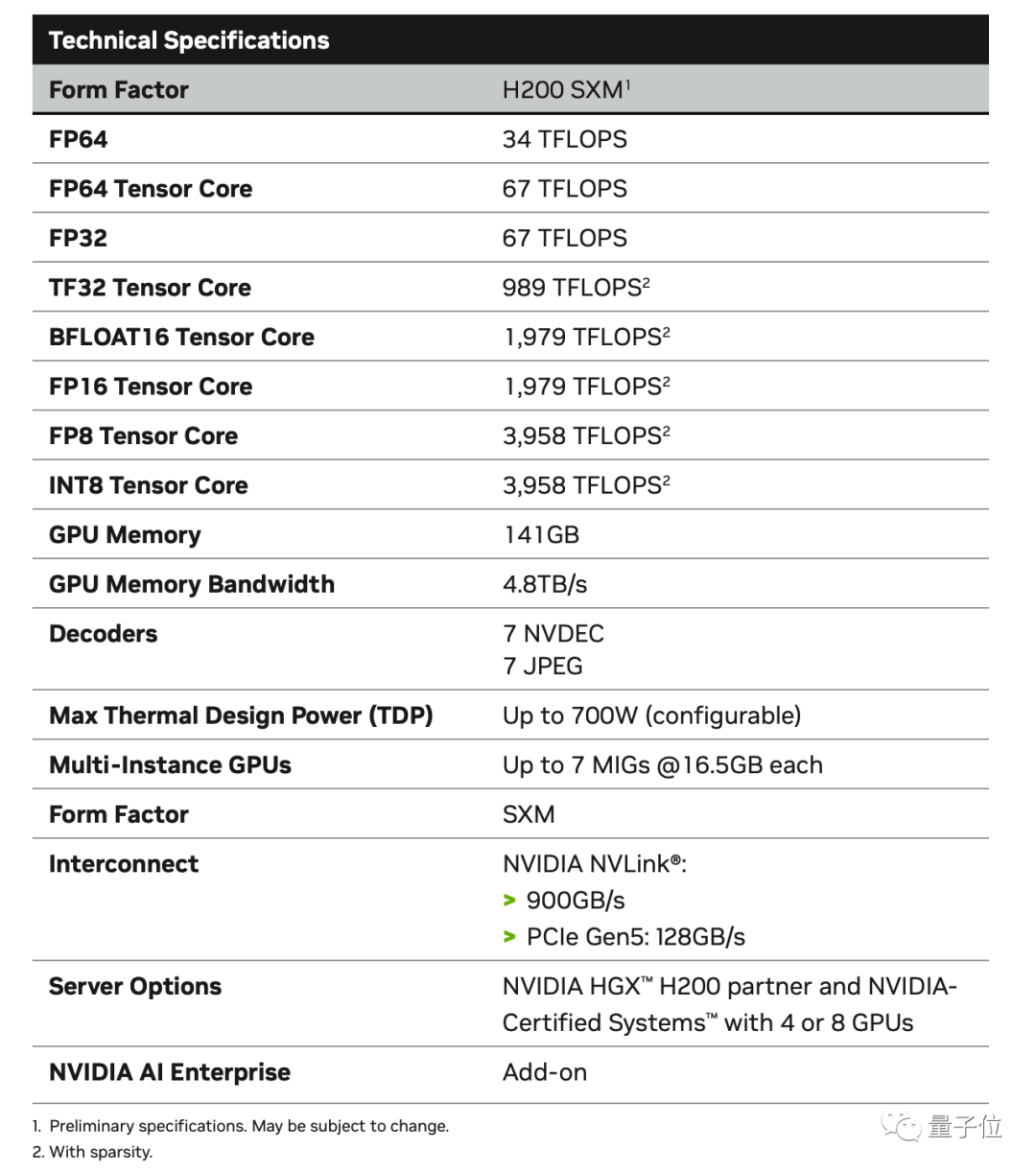 メモリが141GBである理由について、AnandTechは**HBM3eメモリ自体の物理容量は144GBで、24GBのスタックを6スタック**構成していると分析しています。大量生産の理由から、Nvidia**は歩留まりを向上させるために冗長性**としてごく一部を保持しています。2020年に発売されたA100と比較すると、H200はメモリをアップグレードするだけでGPT-3 175Bの推論の18倍も高速になっています。H200は2024年第2四半期に発売される予定ですが、最強のAIチップであるH200という名前は半年間しか所有できません。また、2024年第4四半期には、次世代のBlackwellアーキテクチャに基づくB100も発売される予定ですが、正確な性能はまだ不明であり、チャートは指数関数的な成長を示唆しています。 ## **複数のスーパーコンピューティングセンターがGH200スーパーコンピューティングノードを配備**今回、NvidiaはH200チップ自体に加えて、H200チップで構成された一連のクラスター製品もリリースしました。1つ目は**HGX H200**プラットフォームで、HGXキャリアボードに8つのH200を搭載し、合計ビデオメモリは1.1TB、8ビット浮動小数点動作速度は32P(10^15)FLOPS以上で、H100のデータと一致しています。HGX は、NVIDIA の NVLink および NVSwitch 高速相互接続テクノロジを使用して、175B 大規模モデルのトレーニングと推論など、幅広いアプリケーション ワークロードを最高のパフォーマンスで実行します。HGXボードはスタンドアロンであるため、適切なホストシステムに接続できるため、ユーザーはハイエンドサーバーの非GPU部分をカスタマイズできます。 次は、4つのGH200で構成され、GH200はH200とGrace CPUを組み合わせたQuad GH200スーパーコンピューティングノードです。 Quad GH200ノードは、288個のArm CPUコアと合計2.3TBの高速メモリを提供します。H200は、多数のスーパーコンピューティングノードを組み合わせることで、最終的に巨大なスーパーコンピュータを形成することになり、一部のスーパーコンピューティングセンターでは、GH200システムをスーパーコンピューティング機器に統合することが発表されています。NVIDIAの公式発表によると、ドイツのUlich Supercomputing Centerは、24,000個のGH200ノードと18.2メガワットの電力(毎時18,000キロワット以上の電力に相当する)を含むJupiterスーパーコンピューターにGH200スーパーチップを使用します。このシステムは2024年に導入される予定で、稼働すれば、Jupiterはこれまでに発表された中で最大のHopperベースのスーパーコンピューターになります。Jupiterは、約93(10^18)のFLOPSのAI計算能力、FP64の計算速度のFLOPSの1E、毎秒1.2 PBの帯域幅、10.9 PBのLPDDR5X、さらに2.2 PBのHBM3メモリを備えています。 Jupiterのほか、Japan Joint Center for Advanced High Performance Computing、Texas Advanced Computing Center、イリノイ大学アーバナ・シャンペーン校のNational Supercomputing Application Centerなどのスーパーコンピューティングセンターも、スーパーコンピューティング機器のアップグレードにGH200を使用することを発表しています。では、AI実務家がGH200を体験する初期の方法は何でしょうか?また、オラクルとCoreWeaveは来年GH200インスタンスを提供する計画を発表しており、Amazon、Google Cloud、Microsoft AzureもGH200インスタンスを展開する最初のクラウドサービスプロバイダーとなる予定です。また、Nvidia自身もNVIDIA LaunchPadプラットフォームを通じてGH200へのアクセスを提供します。ハードウェアメーカーでは、ASUSやGIGABYTEなどが年内にGH200搭載サーバー機器の販売を開始する予定です。参考リンク: [1] [2] [3]


最強のモデル学習チップH200がリリース!141Gの大容量メモリ、AI推論が最大90%向上、H100にも対応
記事のソース: 量子ビット
Nvidia Lao Huang は、新世代の GPU チップH200 で再び爆発的に成長しました。
公式サイトには、「AIとスーパーコンピューティングのために構築された世界で最も強力なGPU」とさりげなく書かれています。
今回は、141GBの大容量メモリが、H100の80GBと比較して76%直接増加しています。
HBM3eメモリを搭載した最初のGPUとして、メモリ帯域幅も3.35TB/sから4.8TB/sに増加し、43%増加しました。
HBM3eのサポートにより、H200はLlama-70Bの推論性能をほぼ2倍にし、GPT3-175Bも60%向上させることができます。
H200はH100と完全に互換性があるため、H200を既存のシステムに追加する際に調整は必要ありません。
最強のAIチップは半年しか使えない
メモリのアップグレードを除けば、H200は基本的にH100と同じで、H100もHopperアーキテクチャに属しています。
TSMCの4nmプロセス、800億個のトランジスタ、NVLink 4 900GB/秒の高速相互接続はすべて完全に継承されています。
ピーク時の計算能力も変わらず、FP64 Vector 33.5TFlopsとFP64 Tensor 66.9TFlopsでデータも馴染みがあります。
大量生産の理由から、Nvidiaは歩留まりを向上させるために冗長性としてごく一部を保持しています。
2020年に発売されたA100と比較すると、H200はメモリをアップグレードするだけでGPT-3 175Bの推論の18倍も高速になっています。
H200は2024年第2四半期に発売される予定ですが、最強のAIチップであるH200という名前は半年間しか所有できません。
また、2024年第4四半期には、次世代のBlackwellアーキテクチャに基づくB100も発売される予定ですが、正確な性能はまだ不明であり、チャートは指数関数的な成長を示唆しています。
複数のスーパーコンピューティングセンターがGH200スーパーコンピューティングノードを配備
今回、NvidiaはH200チップ自体に加えて、H200チップで構成された一連のクラスター製品もリリースしました。
1つ目はHGX H200プラットフォームで、HGXキャリアボードに8つのH200を搭載し、合計ビデオメモリは1.1TB、8ビット浮動小数点動作速度は32P(10^15)FLOPS以上で、H100のデータと一致しています。
HGX は、NVIDIA の NVLink および NVSwitch 高速相互接続テクノロジを使用して、175B 大規模モデルのトレーニングと推論など、幅広いアプリケーション ワークロードを最高のパフォーマンスで実行します。
HGXボードはスタンドアロンであるため、適切なホストシステムに接続できるため、ユーザーはハイエンドサーバーの非GPU部分をカスタマイズできます。
H200は、多数のスーパーコンピューティングノードを組み合わせることで、最終的に巨大なスーパーコンピュータを形成することになり、一部のスーパーコンピューティングセンターでは、GH200システムをスーパーコンピューティング機器に統合することが発表されています。
NVIDIAの公式発表によると、ドイツのUlich Supercomputing Centerは、24,000個のGH200ノードと18.2メガワットの電力(毎時18,000キロワット以上の電力に相当する)を含むJupiterスーパーコンピューターにGH200スーパーチップを使用します。
このシステムは2024年に導入される予定で、稼働すれば、Jupiterはこれまでに発表された中で最大のHopperベースのスーパーコンピューターになります。
Jupiterは、約93(10^18)のFLOPSのAI計算能力、FP64の計算速度のFLOPSの1E、毎秒1.2 PBの帯域幅、10.9 PBのLPDDR5X、さらに2.2 PBのHBM3メモリを備えています。
では、AI実務家がGH200を体験する初期の方法は何でしょうか?
また、オラクルとCoreWeaveは来年GH200インスタンスを提供する計画を発表しており、Amazon、Google Cloud、Microsoft AzureもGH200インスタンスを展開する最初のクラウドサービスプロバイダーとなる予定です。
また、Nvidia自身もNVIDIA LaunchPadプラットフォームを通じてGH200へのアクセスを提供します。
ハードウェアメーカーでは、ASUSやGIGABYTEなどが年内にGH200搭載サーバー機器の販売を開始する予定です。
参考リンク:
[1] [2] [3]