記事のソース: New Zhiyuan> ジェネレーティブAIモデルの新しいパラダイムが到来しています。 カリフォルニア大学バークレー校のGoogleは、1ステップでグラフを生成できるべき等生成ネットワーク(IGN)を提案しました。 *画像出典:Unbounded AIによって生成*空一面で流行った拡散模型は淘汰されるのか? 現在、GAN、拡散モデル、コンセンサスモデルなどの生成AIモデルは、ターゲットのデータ分布に対応する入力と出力をマッピングすることで画像を生成します。通常、このモデルは、生成された画像の実際の特徴を確認する前に、多くの実際の画像を学習する必要があります。最近、カリフォルニア大学バークレー校とグーグルの研究者は、べき等生成ネットワーク(IGN)と呼ばれる新しい生成モデルを提案しました。 住所:IGNは、ランダムノイズや単純なグラフィックスなど、さまざまな入力からフォトリアリスティックな画像を1つのステップで生成でき、複数回の反復は必要ありません。このモデルは、任意の入力データをターゲットのデータ分布にマッピングできる「グローバルプロジェクタ」となることを意図しています。要するに、これは将来の汎用画像生成モデルにも当てはまるはずです。興味深いことに、『となりのサインフェルド』の効率的なシーンが著者のインスピレーションとなった。 このシナリオは、冪等演算子の概念を非常によく要約しており、操作中に同じ入力が繰り返され、結果が常に同じであるという事実を指します。つまり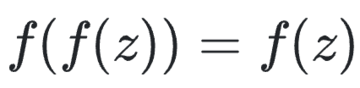 ジェリー・サインフェルドがユーモラスに指摘しているように、現実の行動の中にはべき等と見なすこともできます。## **べき等生成ネットワーク**IGNとGANおよび拡散モデルの間には、2つの重要な違いがあります。- IGNはGANと異なり、生成器と弁別器を別途用意する必要がなく、生成と判別を同時に行う「自己敵対的」モデルである。- インクリメンタルステップを実行する拡散モデルとは異なり、IGNは1つのステップで入力をデータ分布にマッピングしようとします。では、べき等生成モデル(IGN)はどのようにして生まれたのでしょうか? 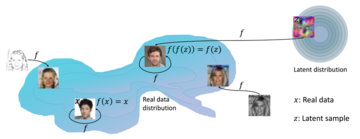 IGN トレーニング ルーチンの PyTorch コードの一部の例。  ## **実験結果**IGNを取得するとどのような影響がありますか?著者らは、現段階では、IGNによって生成された結果は、最も高度なモデルと競合できないことを認めています。実験では、より小さなモデルと低解像度のデータセットが使用され、探索の主な焦点は手法の単純化にあります。もちろん、GANや拡散モデルなどの基本的なジェネレーティブモデリング手法は、成熟度と規模に達するまでに長い時間を要してきました。**実験装置**研究者らは、それぞれ28×28と64×64の画像解像度を使用して、MNIST(グレースケール手書き数値データセット)とCelebA(顔画像データセット)でIGNを評価しました。著者らは、符号化器がDCGANの単純なレイヤ5識別器バックボーンであり、復号器が発生器であるという単純な自己符号化器アーキテクチャを採用しています。 表 1 に、学習とネットワークのハイパーパラメーターを示します。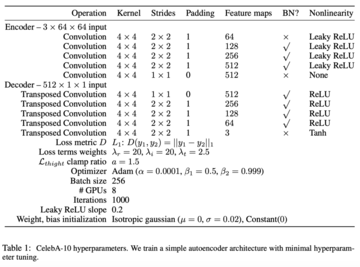 **結果の生成**図 4 は、適用されたモデルの最後の 2 つのデータセットの定性的な結果を 1 回と 2 回連続で示しています。図からわかるように、IGNを一度適用すると(f(z))、コヒーレントな生成結果が得られます。 ただし、MNIST番号の穴や、顔画像の頭頂部や髪の毛のピクセルの歪みなどのアーティファクトが発生する可能性があります。f(f(f(z)))を再適用することで、これらの問題を解決したり、穴を埋めたり、顔の雑音プラークの周りの全体的な変化を小さくすることができます。  図7は、追加結果とフリプリケートを適用した結果を示しています。   画像が学習多様体に近づくと、画像が分布していると見なされるため、f を再度適用すると変化が最小限に抑えられることが示されています。**空間操作の可能性**著者らは、GANが示すものと同様の演算を実行することで、IGNが一貫した潜在空間を持つことを実証し、図6は潜空間アルゴリズムを示しています。 ## **Out-of-Distribution マッピング**また、著者らは、さまざまな分布の画像をモデルに入力して同等の「自然画像」を生成することで、IGNの「グローバルマッピング」の可能性を検証しました。  これを示すために、図 5 の実際の画像に変換します。生の画像x、これらの逆タスクは決定できません。 IGNは、元の画像の構造に準拠した自然なマッピングを作成できます。図に示すように、Fを連続して適用すると、画質が向上します(たとえば、投影スケッチの暗闇や煙のアーティファクトが排除されます)。 ## **Google の今後の展開は?以上の結果から、IGNの方が推論に効果的であり、学習後に結果を生成するのにワンステップで済むことが分かります。また、より一貫性のある結果を出力することもでき、医用画像のインペインティングなど、より多くのアプリケーションに一般化できます。著者によると、> この研究は、任意の入力をターゲット分布にマッピングすることを学習するモデル、つまりジェネレーティブモデリングの新しいパラダイムに向けた第一歩であると考えています。次に、研究チームは、新しい生成AIモデルの可能性を最大限に引き出すために、より多くのデータでIGNをスケールアップすることを計画しています。最新の研究のコードは、今後GitHubで公開される予定です。リソース:


拡散モデルに終止符を打ち、IGNはフォトリアリスティックな画像をワンステップで生成!カリフォルニア大学バークレー校GoogleがLLMを革新し、アメリカのドラマがインスピレーションの源に
記事のソース: New Zhiyuan
空一面で流行った拡散模型は淘汰されるのか?
通常、このモデルは、生成された画像の実際の特徴を確認する前に、多くの実際の画像を学習する必要があります。
最近、カリフォルニア大学バークレー校とグーグルの研究者は、べき等生成ネットワーク(IGN)と呼ばれる新しい生成モデルを提案しました。
IGNは、ランダムノイズや単純なグラフィックスなど、さまざまな入力からフォトリアリスティックな画像を1つのステップで生成でき、複数回の反復は必要ありません。
このモデルは、任意の入力データをターゲットのデータ分布にマッピングできる「グローバルプロジェクタ」となることを意図しています。
要するに、これは将来の汎用画像生成モデルにも当てはまるはずです。
興味深いことに、『となりのサインフェルド』の効率的なシーンが著者のインスピレーションとなった。
つまり
べき等生成ネットワーク
IGNとGANおよび拡散モデルの間には、2つの重要な違いがあります。
IGNはGANと異なり、生成器と弁別器を別途用意する必要がなく、生成と判別を同時に行う「自己敵対的」モデルである。
インクリメンタルステップを実行する拡散モデルとは異なり、IGNは1つのステップで入力をデータ分布にマッピングしようとします。
では、べき等生成モデル(IGN)はどのようにして生まれたのでしょうか?
実験結果
IGNを取得するとどのような影響がありますか?
著者らは、現段階では、IGNによって生成された結果は、最も高度なモデルと競合できないことを認めています。
実験では、より小さなモデルと低解像度のデータセットが使用され、探索の主な焦点は手法の単純化にあります。
もちろん、GANや拡散モデルなどの基本的なジェネレーティブモデリング手法は、成熟度と規模に達するまでに長い時間を要してきました。
実験装置
研究者らは、それぞれ28×28と64×64の画像解像度を使用して、MNIST(グレースケール手書き数値データセット)とCelebA(顔画像データセット)でIGNを評価しました。
著者らは、符号化器がDCGANの単純なレイヤ5識別器バックボーンであり、復号器が発生器であるという単純な自己符号化器アーキテクチャを採用しています。 表 1 に、学習とネットワークのハイパーパラメーターを示します。
図 4 は、適用されたモデルの最後の 2 つのデータセットの定性的な結果を 1 回と 2 回連続で示しています。
図からわかるように、IGNを一度適用すると(f(z))、コヒーレントな生成結果が得られます。 ただし、MNIST番号の穴や、顔画像の頭頂部や髪の毛のピクセルの歪みなどのアーティファクトが発生する可能性があります。
f(f(f(z)))を再適用することで、これらの問題を解決したり、穴を埋めたり、顔の雑音プラークの周りの全体的な変化を小さくすることができます。
空間操作の可能性
著者らは、GANが示すものと同様の演算を実行することで、IGNが一貫した潜在空間を持つことを実証し、図6は潜空間アルゴリズムを示しています。
Out-of-Distribution マッピング
また、著者らは、さまざまな分布の画像をモデルに入力して同等の「自然画像」を生成することで、IGNの「グローバルマッピング」の可能性を検証しました。
生の画像x、これらの逆タスクは決定できません。 IGNは、元の画像の構造に準拠した自然なマッピングを作成できます。
図に示すように、Fを連続して適用すると、画質が向上します(たとえば、投影スケッチの暗闇や煙のアーティファクトが排除されます)。
**Google の今後の展開は?
以上の結果から、IGNの方が推論に効果的であり、学習後に結果を生成するのにワンステップで済むことが分かります。
また、より一貫性のある結果を出力することもでき、医用画像のインペインティングなど、より多くのアプリケーションに一般化できます。
著者によると、
次に、研究チームは、新しい生成AIモデルの可能性を最大限に引き出すために、より多くのデータでIGNをスケールアップすることを計画しています。
最新の研究のコードは、今後GitHubで公開される予定です。
リソース: