> ジェネレーティブAIはビデオ時代に突入しました。出典: Heart of the Machine 画像ソース: Unbounded AIによって生成動画生成といえば、Gen-2やPika Labsを真っ先に思い浮かべる人も多いのではないでしょうか。 しかし、ちょうど今、Metaは、ビデオ生成の点で両方を上回り、編集がより柔軟になったと発表しました。   この「トランペット、踊るウサギ」は、Metaがリリースした最新のデモです。 ご覧のとおり、Metaのテクノロジーは、柔軟な画像編集(例:「ウサギ」を「トランペットバニー」に変えてから「虹色のトランペットバニー」に変える)と、テキストと画像から高解像度の動画を生成する(例:「トランペットバニー」が楽しそうに踊る)の両方をサポートしています。実は、2つのことが関係しています。柔軟な画像編集は「Emu Edit」と呼ばれるモデルによって行われます。 ローカルおよびグローバル編集、背景の削除と追加、色とジオメトリの変換、検出とセグメンテーションなど、テキストを含む画像の無料編集をサポートします。 さらに、指示に正確に従い、命令に関連しない入力画像内のピクセルがそのまま残るようにします。 *ダチョウにスカートを着せる*高解像度の動画は「Emu Video」というモデルで生成されます。 Emu Videoは、文生ビデオの拡散ベースのモデルであり、テキストに基づいて512x512 4秒の高解像度ビデオを生成できます(より長いビデオについても論文で説明しています)。 人間による厳格な評価では、Emu Videoは、RunwayのGen-2およびPika Labsの生成パフォーマンスと比較して、生成の品質とテキストの忠実度の両方で高いスコアを獲得しました。 これはどのように見えるかです:  Metaは公式ブログで、ソーシャルメディアユーザーが独自のGIF、ミームを生成したり、写真や画像を好きなように編集したりできるようにするなど、両方のテクノロジーの将来を思い描いています。 これに関して、Metaは前回のMeta ConnectカンファレンスでEmuモデルをリリースしたときにもこれに言及しました(「MetaのバージョンのChatGPTはこちらです:ラマ2の祝福、Bing検索へのアクセス、Xiaozhaライブデモ」を参照)。  次に、この2つの新モデルをそれぞれ紹介します。**エミュービデオ**大規模な Wensheng グラフ モデルは、Web スケールの画像とテキストのペアでトレーニングされ、高品質で多様な画像を生成します。 これらのモデルは、ビデオとテキストのペアを使用してテキストからビデオ(T2V)の生成にさらに適応できますが、ビデオ生成は、品質と多様性の点で画像生成に遅れをとっています。 画像生成と比較すると、ビデオ生成は、テキスト プロンプトに基づいて、より高い次元の時空間出力空間をモデル化する必要があるため、より困難になります。 さらに、ビデオテキストデータセットは、通常、画像テキストデータセットよりも桁違いに小さくなります。ビデオ生成の一般的なモードは、拡散モデルを使用してすべてのビデオ フレームを一度に生成することです。 これとは対照的に、NLPでは、長いシーケンス生成は自己回帰問題として定式化されます:以前に予測された単語の条件で次の単語を予測します。 その結果、その後の予測の条件付け信号は徐々に強くなります。 研究者らは、それ自体が時系列である高品質のビデオ生成には、強化された条件付けも重要であるという仮説を立てています。 しかし、拡散モデルによる自己回帰復号化は、そのようなモデルの助けを借りて単一フレーム画像を生成すること自体が複数回の反復を必要とするため、困難です。その結果、Metaの研究者は、拡散ベースのテキストからビデオへの生成を明示的な中間画像生成ステップで強化するEMU VIDEOを提案しました。 住所:プロジェクトの住所:具体的には、文生映像問題を、(1)入力テキストプロンプトに基づく画像生成、(2)画像とテキストの強化条件に基づく映像生成の2つのサブ問題に分解した。 直感的には、モデルに開始画像とテキストを与えると、モデルは画像が将来どのように進化するかを予測するだけでよいため、ビデオの生成が容易になります。 *Metaの研究者は、文生ビデオを2つのステップに分けました:最初にテキストpを条件とする画像Iを生成し、次により強い条件(結果の画像とテキスト)を使用してビデオvを生成します。 Model Fを画像で制約するために、画像に一時的に焦点を合わせ、どのフレームがゼロになったかを示すバイナリマスクとノイズの多い入力に接続しました。 *ビデオ-テキストデータセットは画像-テキストデータセットよりもはるかに小さいため、研究者は、重み凍結された事前学習済みテキスト-画像(T2I)モデルを使用してテキストからビデオへのモデルも初期化しました。 彼らは、512pxの高解像度ビデオを直接生成するために、拡散ノイズスケジューリングと多段階トレーニングの変更など、設計上の重要な決定を特定しました。テキストから直接ビデオを生成する方法とは異なり、分解方法では推論時に画像が明示的に生成されるため、文生図モデルの視覚的な多様性、スタイル、品質を簡単に維持できます (図 1 参照)。 これにより、EMU ビデオは、同じトレーニング データ、計算量、およびトレーニング可能なパラメーターを使用しても、直接 T2V 手法よりも優れたパフォーマンスを発揮します。  この研究は、多段階のトレーニング方法によって、Wenshengビデオ生成の品質を大幅に向上させることができることを示しています。 この方法では、前の方法で使用されていたディープ カスケード モデルの一部を必要とせずに、512px で高解像度ビデオの直接生成がサポートされます。  研究者らは、堅牢な人間評価プロトコルであるJUICEを考案し、評価者がペアを選択する際に自分の選択が正しいことを証明するように求めました。 図2に示すように、EMU VIDEOの平均勝率は91.8%、86.6%という品質とテキストの忠実度は、PikaやGen-2などの商用ソリューションを含むすべての先行作業をはるかに上回っています。 T2Vに加えて、EMUビデオは、ユーザーが提供した画像とテキストプロンプトに基づいてモデルがビデオを生成する画像からビデオへの生成にも使用できます。 この場合、EMU VIDEOの生成結果はVideoComposerよりも96%優れています。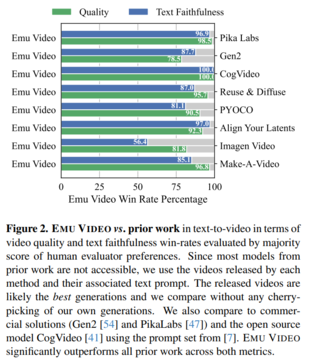 デモからわかるように、EMU VIDEOはすでに4秒のビデオ生成をサポートしています。 この論文では、ビデオの長さを長くする方法も模索しています。 アーキテクチャを少し変更するだけで、モデルをTフレームに拘束し、ビデオを拡張できると著者らは述べている。 そこで、EMUビデオのバリアントをトレーニングして、「過去」の16フレームを条件に次の16フレームを生成しました。 ビデオを展開すると、元のビデオとは異なる将来のテキスト プロンプトが使用されます (図 7 参照)。 その結果、拡張されたビデオは、元のビデオと将来のテキストプロンプトの両方に従っていることがわかりました。 **エミュー編集:正確な画像編集**毎日何百万人もの人々が画像編集を使用しています。 ただし、一般的な画像編集ツールは、かなりの専門知識を必要とし、使用に時間がかかるか、非常に制限されており、特定のフィルターなどの事前定義された一連の編集操作のみを提供します。 この段階では、命令ベースの画像編集は、これらの制限を回避するために、ユーザーに自然言語命令を使用させようとします。 たとえば、ユーザーはモデルに画像を提供し、モデルに「エミューに消防士のコスチュームを着せる」ように指示できます (図 1 参照)。 ただし、InstructPix2Pix のような命令ベースの画像編集モデルを使用すると、さまざまな命令を処理できますが、命令を正確に解釈して実行することは困難な場合がよくあります。 さらに、これらのモデルは汎化能力が限られており、ウサギの赤ちゃんに虹色のトランペットを吹かせたり、他のモデルでウサギを虹色に染めたり、虹色のトランペットを直接生成したりするなど、トレーニングされたタスクとは少し異なるタスクを実行できないことがよくあります(図3を参照)。 これらの問題に対処するために、Metaは、ローカルおよびグローバル編集、背景の削除と追加、色の変更と幾何学的変換、検出とセグメント化などのコマンドに基づいて自由形式の編集を実行できる、幅広く多様なタスクでトレーニングされた最初の画像編集モデルであるEmu Editを発表しました。 住所:プロジェクトの住所:今日の多くのジェネレーティブAIモデルとは異なり、Emu Editは指示に正確に従うことができ、入力画像内の無関係なピクセルがそのまま残るようにします。 たとえば、ユーザーが「草むらの上の子犬を除去する」というコマンドを与えた場合、オブジェクトを削除した後の画像はほとんど目立ちません。 画像の左下隅にあるテキストの削除と画像の背景の変更も、Emu Edit によって処理されます。 このモデルをトレーニングするために、Metaは1,000万個の合成サンプルのデータセットを開発し、それぞれに入力画像、実行するタスクの説明、およびターゲット出力画像が含まれています。 その結果、Emu Editは、コマンドの忠実度と画質の点で前例のない編集結果を示しています。方法論レベルでは、メタのトレーニング済みモデルは、地域ベースの編集、自由形式の編集、コンピュータービジョンのタスクをカバーする16の異なる画像編集タスクを実行でき、これらはすべて生成タスクとして定式化されており、Metaはタスクごとに独自のデータ管理パイプラインも開発しています。 Metaは、トレーニングタスクの数が増えると、Emu Editのパフォーマンスも向上することを発見しました。 第二に、多種多様なタスクを効果的に処理するために、Metaは、生成プロセスをビルドタスクの正しい方向に導くために使用される学習タスク埋め込みの概念を導入しました。 具体的には、各タスクについて、固有のタスク埋め込みベクトルを学習し、クロスアテンションインタラクションを通じてモデルに統合し、時間ステップ埋め込みに追加します。 その結果、学習タスクの埋め込みにより、自由形式の指示から正確に推論し、正しい編集を実行するモデルの能力が大幅に向上することが示されました。今年4月、Metaは「Split Everything」というAIモデルをローンチしましたが、その効果はあまりにもすごかったため、多くの人がCV分野がまだ存在するのではないかと疑問に思い始めました。 わずか数か月で、Metaは画像と動画の分野でEmu VideoとEmu Editを立ち上げましたが、生成AIの分野は本当に不安定すぎるとしか言えません。


MetaのジェネレーティブAIコンボの動き:動画生成が第2世代を上回り、アニメーション画像の絵文字は好きなようにカスタマイズ可能
出典: Heart of the Machine
動画生成といえば、Gen-2やPika Labsを真っ先に思い浮かべる人も多いのではないでしょうか。 しかし、ちょうど今、Metaは、ビデオ生成の点で両方を上回り、編集がより柔軟になったと発表しました。
実は、2つのことが関係しています。
柔軟な画像編集は「Emu Edit」と呼ばれるモデルによって行われます。 ローカルおよびグローバル編集、背景の削除と追加、色とジオメトリの変換、検出とセグメンテーションなど、テキストを含む画像の無料編集をサポートします。 さらに、指示に正確に従い、命令に関連しない入力画像内のピクセルがそのまま残るようにします。
高解像度の動画は「Emu Video」というモデルで生成されます。 Emu Videoは、文生ビデオの拡散ベースのモデルであり、テキストに基づいて512x512 4秒の高解像度ビデオを生成できます(より長いビデオについても論文で説明しています)。 人間による厳格な評価では、Emu Videoは、RunwayのGen-2およびPika Labsの生成パフォーマンスと比較して、生成の品質とテキストの忠実度の両方で高いスコアを獲得しました。 これはどのように見えるかです:
エミュービデオ
大規模な Wensheng グラフ モデルは、Web スケールの画像とテキストのペアでトレーニングされ、高品質で多様な画像を生成します。 これらのモデルは、ビデオとテキストのペアを使用してテキストからビデオ(T2V)の生成にさらに適応できますが、ビデオ生成は、品質と多様性の点で画像生成に遅れをとっています。 画像生成と比較すると、ビデオ生成は、テキスト プロンプトに基づいて、より高い次元の時空間出力空間をモデル化する必要があるため、より困難になります。 さらに、ビデオテキストデータセットは、通常、画像テキストデータセットよりも桁違いに小さくなります。
ビデオ生成の一般的なモードは、拡散モデルを使用してすべてのビデオ フレームを一度に生成することです。 これとは対照的に、NLPでは、長いシーケンス生成は自己回帰問題として定式化されます:以前に予測された単語の条件で次の単語を予測します。 その結果、その後の予測の条件付け信号は徐々に強くなります。 研究者らは、それ自体が時系列である高品質のビデオ生成には、強化された条件付けも重要であるという仮説を立てています。 しかし、拡散モデルによる自己回帰復号化は、そのようなモデルの助けを借りて単一フレーム画像を生成すること自体が複数回の反復を必要とするため、困難です。
その結果、Metaの研究者は、拡散ベースのテキストからビデオへの生成を明示的な中間画像生成ステップで強化するEMU VIDEOを提案しました。
プロジェクトの住所:
具体的には、文生映像問題を、(1)入力テキストプロンプトに基づく画像生成、(2)画像とテキストの強化条件に基づく映像生成の2つのサブ問題に分解した。 直感的には、モデルに開始画像とテキストを与えると、モデルは画像が将来どのように進化するかを予測するだけでよいため、ビデオの生成が容易になります。
ビデオ-テキストデータセットは画像-テキストデータセットよりもはるかに小さいため、研究者は、重み凍結された事前学習済みテキスト-画像(T2I)モデルを使用してテキストからビデオへのモデルも初期化しました。 彼らは、512pxの高解像度ビデオを直接生成するために、拡散ノイズスケジューリングと多段階トレーニングの変更など、設計上の重要な決定を特定しました。
テキストから直接ビデオを生成する方法とは異なり、分解方法では推論時に画像が明示的に生成されるため、文生図モデルの視覚的な多様性、スタイル、品質を簡単に維持できます (図 1 参照)。 これにより、EMU ビデオは、同じトレーニング データ、計算量、およびトレーニング可能なパラメーターを使用しても、直接 T2V 手法よりも優れたパフォーマンスを発揮します。
毎日何百万人もの人々が画像編集を使用しています。 ただし、一般的な画像編集ツールは、かなりの専門知識を必要とし、使用に時間がかかるか、非常に制限されており、特定のフィルターなどの事前定義された一連の編集操作のみを提供します。 この段階では、命令ベースの画像編集は、これらの制限を回避するために、ユーザーに自然言語命令を使用させようとします。 たとえば、ユーザーはモデルに画像を提供し、モデルに「エミューに消防士のコスチュームを着せる」ように指示できます (図 1 参照)。
プロジェクトの住所:
今日の多くのジェネレーティブAIモデルとは異なり、Emu Editは指示に正確に従うことができ、入力画像内の無関係なピクセルがそのまま残るようにします。 たとえば、ユーザーが「草むらの上の子犬を除去する」というコマンドを与えた場合、オブジェクトを削除した後の画像はほとんど目立ちません。
方法論レベルでは、メタのトレーニング済みモデルは、地域ベースの編集、自由形式の編集、コンピュータービジョンのタスクをカバーする16の異なる画像編集タスクを実行でき、これらはすべて生成タスクとして定式化されており、Metaはタスクごとに独自のデータ管理パイプラインも開発しています。 Metaは、トレーニングタスクの数が増えると、Emu Editのパフォーマンスも向上することを発見しました。
第二に、多種多様なタスクを効果的に処理するために、Metaは、生成プロセスをビルドタスクの正しい方向に導くために使用される学習タスク埋め込みの概念を導入しました。 具体的には、各タスクについて、固有のタスク埋め込みベクトルを学習し、クロスアテンションインタラクションを通じてモデルに統合し、時間ステップ埋め込みに追加します。 その結果、学習タスクの埋め込みにより、自由形式の指示から正確に推論し、正しい編集を実行するモデルの能力が大幅に向上することが示されました。
今年4月、Metaは「Split Everything」というAIモデルをローンチしましたが、その効果はあまりにもすごかったため、多くの人がCV分野がまだ存在するのではないかと疑問に思い始めました。 わずか数か月で、Metaは画像と動画の分野でEmu VideoとEmu Editを立ち上げましたが、生成AIの分野は本当に不安定すぎるとしか言えません。