As blockchain evolves from a simple transaction system into a complex programmable network, more computation is moving from on-chain execution to off chain execution. Rollup scaling, cross chain bridges, AI inference, Oracles, and off chain data processing all need a technical solution that can prove a computation result is authentic and trustworthy.
Zero knowledge proofs, or ZK proofs, have become a key technology in Web3 infrastructure in this context. They allow a system to prove that a program has been executed correctly without revealing the original data. However, traditional ZK development has long had a very high barrier to entry. Developers often need to learn complex cryptographic constraint systems, specialized DSL languages, and low level circuit logic, which makes ZK technology difficult to adopt widely.
The emergence of SP1 zkVM is an attempt to solve this problem.
What Is SP1 zkVM?
As a general purpose zero knowledge virtual machine, or zkVM, launched by Succinct, SP1 zkVM allows developers to write programs directly in Rust and automatically generate verifiable ZK proofs, without hand writing cryptographic circuits.
Traditional ZK systems usually rely on specialized languages such as Circom, Halo2, Cairo, or Noir. Although these systems are powerful, they are difficult to develop with and require developers to understand a large amount of underlying cryptographic logic.
SP1 zkVM takes a completely different design approach.
Developers only need to write programs as they would in ordinary software development, and the rest of the proof generation process is handled automatically by the system. Succinct calls this idea “Code as Proof.” It means that, in theory, any program that can run can be converted into verifiable computation.
How Is SP1 zkVM Different from a Traditional Virtual Machine?
An ordinary virtual machine, or VM, is mainly responsible for running programs. Examples include the EVM, WASM, and JVM. These systems focus on execution efficiency, memory management, and state updates. A zkVM, however, not only needs to run a program, but also needs to prove that the program was executed correctly.
For that reason, a zkVM must do more than execute programs. It must also record the full execution process, build mathematical constraints, generate proofs, and provide verifiability to external systems.
At its core, a zkVM is more like a “provable execution environment.” It not only lets a program run, but also allows others to trust that the execution result is authentic and reliable.
Why Does SP1 Choose RISC-V?
The underlying execution architecture of SP1 zkVM is based on the RISC-V instruction set.
RISC-V is an open source reduced instruction set architecture. It is simple in structure, clear in logic, and easier to formally verify. This is especially important for a zkVM, because the more complex the CPU instructions are, the harder it becomes to generate proofs.
Compared with complex CPU architectures, RISC-V is better suited to being converted into a mathematical constraint system.
SP1 does not generate proofs directly from Rust programs. Its full process is:
Rust → RISC-V → zkVM execution → Proof
Therefore, RISC-V serves as the “intermediate execution layer” in the whole system.
Why Is Rust Suitable for zkVM?
Succinct chose Rust mainly because Rust is highly suitable for verifiable computation.
First, Rust offers very high performance. Since proof generation itself requires substantial computing resources, performance at the systems language level is critical.
Second, Rust has strong memory safety mechanisms. Its ownership model can reduce runtime errors, helping the system generate more stable execution traces.
Rust’s determinism is also important.
In a zkVM, the same input must produce the same output. Otherwise, different nodes may generate different proofs.
Rust has natural advantages in determinism, which makes it well suited as a development language for zkVMs.
More importantly, Rust is already widely used in Solana, Cosmos, Rollups, and systems development. Its developer ecosystem is mature, and migration costs are relatively low.
How Is a Rust Program Converted into a ZK Proof?
The core process of SP1 zkVM is:
Writing a Rust program → compiling it into RISC-V → zkVM execution → generating an execution trace → converting it into a STARK proof → compressing it into a SNARK → on-chain verification.
The central goal of the entire process is to prove that “the program was correctly executed according to the rules.”
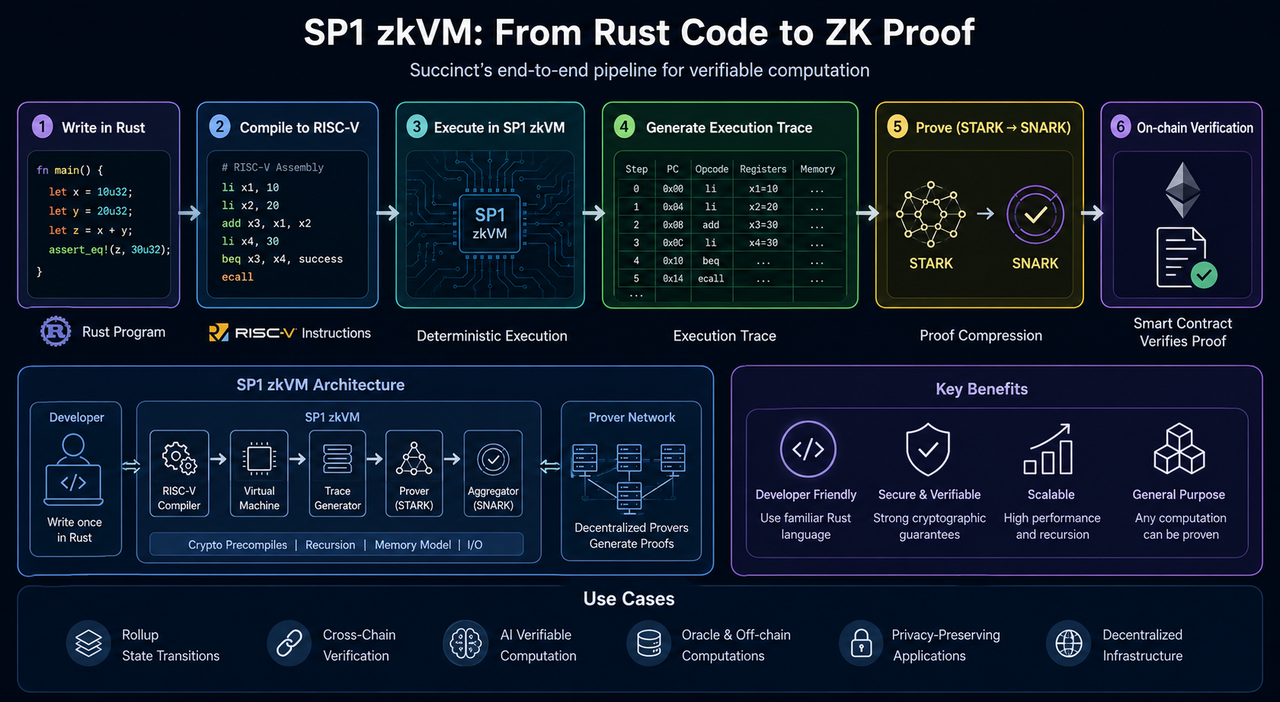
Step One: Write a Rust Program
Developers first write business logic in Rust.
These programs can be used for Rollup state transitions, AI model inference, cross chain verification, hash computation, data processing, and Oracle systems.
In traditional ZK development, developers often need to hand write complex circuits. In SP1, they only need to write ordinary Rust programs.
For example:
fn main() {
let x = 10;
let y = 20;
let z = x + y;
assert_eq!(z, 30);
}
SP1 automatically converts this program into a verifiable proof.
This greatly lowers the barrier to ZK development.
Step Two: Compile into RISC-V Instructions
The Rust program is then compiled into RISC-V instructions.
A proof system cannot directly verify a high level language. It can only verify the low level machine execution process.
The compiler converts Rust into a stream of low level instructions, such as:
ADD x1, x2, x3
LOAD x4, 0(x5)
STORE x6, 4(x7)
These instructions are then executed inside the zkVM.
The most important goal at this stage is to ensure that the program is deterministic and verifiable.
Why Is Determinism So Important?
In ordinary programs, time, random numbers, and system state can all affect execution results.
In a zkVM, however, the same input must produce the same output.
Otherwise, different nodes may generate different traces, and the final proof may fail verification.
For this reason, zkVMs usually strictly limit access to external state and ensure that the entire execution process is fully deterministic.
This is one of the biggest differences between a zkVM and an ordinary virtual machine.
Step Three: zkVM Execution Generates an Execution Trace
SP1 zkVM executes the RISC-V instructions and records the full execution process.
This process is called:
Execution Trace.
You can think of it as:
“A recording of the program’s execution.”
The trace records every state change during program execution, including:
instruction execution, CPU state changes, memory changes, register states, and input and output relationships.
For example:
Step 1: LOAD
Step 2: ADD
Step 3: STORE
Step 4: ASSERT
The proof system then proves that these steps really happened correctly.
Why Is the Trace the Core of the Whole System?
Because the essence of a ZK proof is not proving that “a result exists.”
What it actually proves is:
“The program was correctly executed according to the rules.”
Therefore, the execution trace determines the credibility of the entire proof.
If the trace contains an error, the final generated proof will also become invalid.
Step Four: Convert the Trace into a STARK Proof
After the execution trace is generated, the system converts it into mathematical constraints.
This stage usually uses technologies such as AIR, or Algebraic Intermediate Representation, polynomial constraint systems, and hash commitments.
The system then generates a STARK proof.
The advantages of STARKs are:
They require no trusted setup, provide strong security, offer quantum resistance, and scale well.
For this reason, many modern zkVMs currently use STARKs as their underlying proof system.
However, STARKs also have one obvious drawback:
Their proof size is relatively large.
So further optimization is needed.
Step Five: Compress the STARK into a SNARK
To reduce on-chain verification costs, SP1 usually further compresses the STARK into a SNARK.
This design combines the strengths of both proof systems:
STARKs are fast to generate, while SNARKs are inexpensive to verify on-chain.
As a result, SP1 can balance:
proof generation efficiency, on-chain gas costs, and overall network scalability.
The final SNARK proof is submitted to blockchains such as Ethereum for verification.
What Is a Recursive Proof?
Recursive proof is one of the key technologies in modern zkVMs.
It allows:
one proof to verify another proof.
For example, multiple Rollup proofs can be generated separately and then aggregated into a larger proof.
In the end, the chain only needs to verify once.
Recursive proofs can significantly reduce on-chain verification costs and lower network load, making them an important foundation for large scale verifiable computation.
How Is SP1 zkVM Different from zkEVM?
Many developers confuse zkVM with zkEVM.
But their goals are actually completely different.
The core goal of a zkEVM is to be compatible with Ethereum’s EVM, so it mainly revolves around Solidity and EVM bytecode.
SP1 zkVM, by contrast, is more focused on general purpose verifiable computation.
It can execute not only smart contract logic, but also AI inference, data processing, cross chain logic, and arbitrary Rust programs.
Therefore:
A zkEVM is more like an Ethereum scaling solution.
SP1 zkVM is more like general purpose proof infrastructure.
Core Advantages of SP1 zkVM
The biggest advantage of SP1 is that it significantly lowers the barrier to ZK development.
Developers no longer need to hand write complex cryptographic circuits. Instead, they can build verifiable applications directly in Rust.
At the same time, SP1 is highly general purpose and supports recursive proofs, modular extensions, and low cost on-chain verification.
These capabilities make it suitable not only for Rollups, but also for broader scenarios such as AI, cross chain systems, and off chain computation.
Typical Use Cases of SP1 zkVM
SP1 zkVM is gradually being applied across multiple fields.
In Rollups, it can generate state transition proofs. In cross chain protocols, it can verify the authenticity of states across different chains. In AI scenarios, it can verify model inference results. In Oracle systems, it can verify complex off chain data computation.
In the long run, SP1’s more important goal is to support the development of a “verifiable internet.”
In the future:
APIs, web pages, database queries, and even AI content may all have their authenticity verified through proofs.
What Challenges Does SP1 zkVM Face?
Despite its broad potential, SP1 still faces many practical challenges.
First, generating complex proofs remains expensive and requires substantial GPU and hardware resources.
Second, a general purpose zkVM needs to balance performance, security, and generality at the same time, making it far more technically complex than specialized circuit systems.
In addition, the zkVM space is currently highly competitive. Projects including RISC Zero, zkSync, Starknet, Valida, and Jolt are all pushing development in different directions.
At the same time, the broader verifiable computation market is still in its early stages, and large scale demand has not yet fully emerged.
Conclusion
SP1 zkVM is trying to redefine how zero knowledge proofs are developed.
Through Rust programming, RISC-V execution, execution traces, STARK and SNARK compression, and recursive proofs, Succinct has built a general purpose verifiable computation infrastructure.
Developers no longer need to understand complex ZK circuits. Instead, they can build verifiable applications much like ordinary software.
FAQs
Why Does SP1 Choose RISC-V?
Because RISC-V instructions are simple, open source, and easier to formally verify, making them better suited to building a zkVM.
Why Is Rust Suitable for zkVM?
Rust offers high performance, determinism, and memory safety, which makes it highly suitable for verifiable computation environments.
What Are the Steps in Generating a ZK Proof?
The main steps include writing a Rust program, compiling it into RISC-V, executing it in the zkVM to generate a trace, generating a STARK or SNARK proof, and performing on-chain verification.
How Is SP1 zkVM Different from Traditional ZK Systems?
Traditional systems usually require specialized DSLs and hand written circuits, while SP1 supports general purpose languages and automatically generates proofs.
What Are the Use Cases of SP1 zkVM?
They include Rollup scaling, cross chain verification, verifiable AI computation, Oracles, and off chain computation.








