À medida que as aplicações de blockchain ganham escala, os dados on-chain se tornaram um recurso essencial para DeFi, análise on-chain, Agentes de IA e aplicações multicadeia. No entanto, os dados brutos da blockchain geralmente vêm na forma de blocos, transações e logs de eventos, o que obriga os desenvolvedores a percorrer pipelines complexos de extração e processamento antes de poderem utilizá-los. Por isso, acessar dados on-chain de forma eficiente se tornou um dos principais desafios no desenvolvimento de infraestrutura Web3.
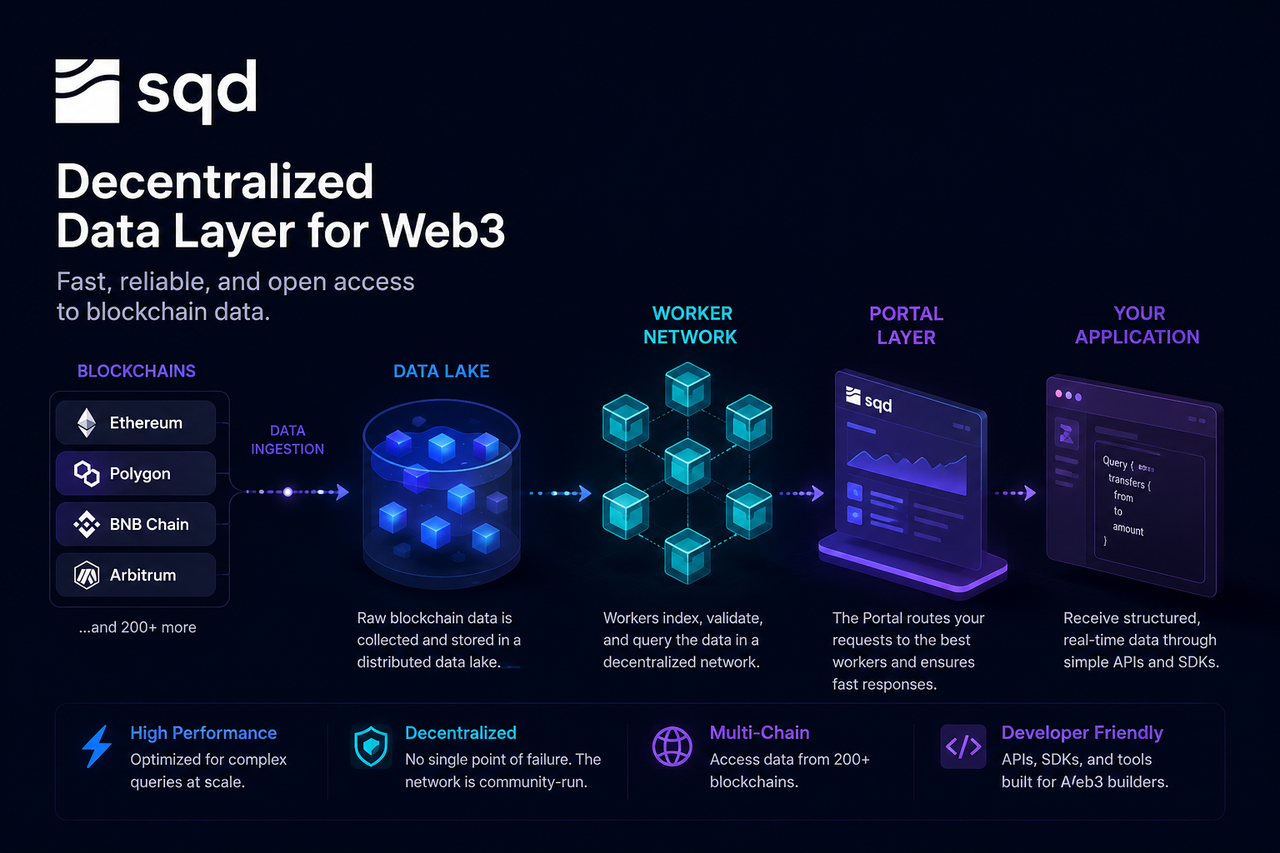
O Subsquid (SQD) surge como uma rede de dados descentralizada criada para resolver esse problema. Diferente dos nós RPC tradicionais, que leem diretamente o estado da blockchain, o SQD oferece uma arquitetura de serviço de dados construída em torno de um data lake, de Worker nodes e de uma camada de consulta Portal. Isso permite que os desenvolvedores acessem dados on-chain estruturados e indexados por meio de uma interface unificada.
O que é uma consulta de dados SQD?
Uma consulta de dados SQD é o processo pelo qual os desenvolvedores obtêm dados on-chain por meio da Rede SQD. Em vez de solicitar dados diretamente dos nós da blockchain, as consultas SQD retornam informações já pré-processadas e indexadas, permitindo respostas rápidas a solicitações complexas.
Por exemplo, um dashboard DeFi pode precisar agregar volumes de negociação dos últimos meses, um Agente de IA pode precisar ler variações de ativos em vários endereços, e uma plataforma de análise pode precisar consultar todo o histórico de eventos de um contrato inteligente específico. Todos esses são cenários típicos de consulta de dados.
A ideia central do SQD é deslocar o processamento pesado de dados para a etapa inicial, de modo que as aplicações possam acessar dados estruturados diretamente, sem precisar lidar com enormes volumes brutos de blocos.
Como os dados on-chain entram na Rede SQD
O ponto de partida de uma consulta ocorre antes mesmo de o desenvolvedor enviar a solicitação.
À medida que as redes de blockchain geram novos blocos continuamente, a Rede SQD captura dados brutos — incluindo blocos, transações, eventos de log e mudanças de estado de contratos inteligentes — em tempo real por meio de seu sistema de coleta de dados. Esses dados são então padronizados para processamento e armazenamento posteriores.
Como o SQD suporta múltiplas blockchains, sua camada de coleta de dados precisa sincronizar continuamente fluxos de dados de diferentes ecossistemas, garantindo integridade e consistência. Após a padronização, os dados são gravados na camada de armazenamento da rede.
O data lake é a infraestrutura de armazenamento central da rede SQD.
Diferente dos bancos de dados tradicionais, projetados para dados estruturados, um data lake consegue lidar com grandes volumes de dados brutos e semiestruturados. O histórico da blockchain, dados de transações, logs de eventos e instantâneos de estado são todos armazenados nessa camada.
A vantagem de um data lake é que ele preserva o histórico completo dos dados, ao mesmo tempo que permite processamento e análise downstream flexíveis. Para aplicações que precisam rastrear milhões de transações, esse método de armazenamento é muito mais eficiente do que consultar nós de blockchain diretamente.
O data lake funciona como a memória de longo prazo da Rede SQD, fornecendo dados para indexação e consultas posteriores.
Como os Worker nodes processam solicitações de consulta
Os Worker nodes são a camada de execução da rede SQD.
Quando os dados entram na rede, os Worker nodes indexam, classificam e otimizam as informações para recuperação rápida. O processo de indexação é como criar um sumário de uma enciclopédia enorme: não é necessário revisar tudo do zero a cada consulta.
Além de construir índices, os Worker nodes também executam tarefas de consulta. Quando um desenvolvedor solicita dados específicos, um Worker node localiza rapidamente os registros relevantes usando o índice e, em seguida, filtra, agrega e calcula os resultados.
Como vários Worker nodes podem ser executados em paralelo, a rede consegue lidar com muitas consultas simultaneamente, aumentando o desempenho geral e a escalabilidade.
Como o Portal recebe solicitações de desenvolvedores
O Portal é o ponto de entrada unificado para os desenvolvedores acessarem a Rede SQD.
Os desenvolvedores normalmente enviam consultas por meio de uma API ou SDK, sem se conectar diretamente aos nós subjacentes. Quando uma solicitação chega ao Portal, o sistema analisa a consulta e determina quais Worker nodes são mais adequados para processá-la.
O Portal funciona como um balanceador de carga na internet. Os desenvolvedores interagem apenas com uma interface única, enquanto o agendamento complexo de recursos e a seleção de nós acontecem automaticamente nos bastidores.
Esse design simplifica o desenvolvimento e melhora a eficiência geral de recursos da rede.
Como os resultados da consulta são retornados às aplicações
Assim que os Worker nodes concluem o processamento, os resultados são enviados de volta à camada Portal.
O Portal formata os resultados conforme necessário e envia os dados finais para a aplicação. Os desenvolvedores recebem dados já estruturados — por exemplo, objetos JSON ou resultados analíticos, prontos para exibição no front-end, lógica de negócios ou inferência de IA.
Todo o processo geralmente é transparente para os usuários finais. Eles simplesmente veem a página carregar ou os resultados da análise aparecerem, enquanto nos bastidores várias etapas, da coleta de dados à execução da consulta, já foram concluídas.
Como o Hotblocks suporta consultas de dados em tempo real
Além de consultas históricas, muitas aplicações precisam de informações on-chain em tempo real.
Por exemplo, sistemas de monitoramento on-chain precisam detectar transações anômalas, estratégias automatizadas precisam ouvir eventos de contratos inteligentes, e Agentes de IA precisam estar atualizados sobre as condições mais recentes do mercado. Esses cenários exigem que os dados estejam disponíveis assim que um novo bloco é produzido.
O Hotblocks é a camada de dados em tempo real fornecida pelo SQD, projetada especificamente para novos blocos e eventos ao vivo. Em comparação com os dados históricos do data lake, o Hotblocks prioriza baixa latência e respostas rápidas, permitindo que os desenvolvedores criem aplicações em tempo real.
Como as consultas SQD diferem das consultas RPC tradicionais
Ambos os métodos permitem acessar dados on-chain, mas a lógica subjacente é muito diferente.
Os nós RPC tradicionais funcionam como uma consulta direta a um banco de dados da blockchain. Cada solicitação precisa buscar os dados correspondentes no estado on-chain ou nos registros históricos. À medida que o escopo da consulta aumenta, a pressão sobre o desempenho e os custos cresce proporcionalmente.
O SQD, por sua vez, utiliza uma arquitetura pré-indexada. Os dados já estão organizados e indexados quando entram na rede, portanto as consultas não precisam escanear todo o histórico novamente. Para análises complexas, agregação de dados multicadeia e estatísticas históricas de longo prazo, o SQD oferece uma eficiência muito maior.
| Dimensão |
SQD |
RPC tradicional |
| Fonte de dados |
Dados pré-indexados |
Leituras on-chain em tempo real |
| Eficiência de consulta |
Alta |
Média |
| Análise de dados históricos |
Vantagem significativa |
Mais complexa |
| Suporte a múltiplas cadeias |
Forte |
Depende de múltiplos nós |
| Custo de infraestrutura |
Menor |
Maior |
| Leitura de estado em tempo real |
Suportada |
Suportada |
Como o processo de consulta SQD é importante para Agentes de IA
Os Agentes de IA tornam-se uma aplicação-chave na infraestrutura Web3, e o acesso a dados é fundamental para seu funcionamento.
Se um Agente de IA precisa analisar o comportamento de carteiras, rastrear estados de protocolos ou executar ações on-chain, ele precisa obter continuamente dados precisos e estruturados. As consultas RPC tradicionais podem fornecer dados brutos, mas geralmente exigem processamento e transformação adicionais.
A interface de dados unificada fornecida pelo SQD reduz a complexidade para que os Agentes de IA obtenham informações on-chain. Com resultados de consulta padronizados, os sistemas de IA podem dedicar mais poder computacional à análise e à tomada de decisão, em vez de à manipulação de dados.
À medida que a IA e a Web3 continuam convergindo, a importância das camadas de dados descentralizadas só tende a crescer.
Resumo
Uma consulta de dados SQD não é apenas uma simples leitura de dados, mas sim um fluxo de trabalho completo que envolve a camada de coleta de dados, o data lake, os Worker nodes e a camada Portal, todos atuando em conjunto. Os dados brutos da blockchain são primeiro coletados e armazenados, depois indexados e otimizados, e finalmente entregues aos desenvolvedores por meio de uma interface unificada.
Esse modelo de processamento pré-indexado e distribuído permite que o SQD ofereça alta eficiência para consultas complexas, análise multicadeia e acesso a dados em tempo real. Com a demanda crescente de DeFi, plataformas de análise on-chain e Agentes de IA por mais dados, a arquitetura de camada de dados representada pelo SQD está se tornando uma peça essencial da infraestrutura Web3.
Perguntas Frequentes
Qual é a diferença entre uma consulta de dados SQD e uma consulta de API comum?
Uma API comum geralmente é mantida por um provedor centralizado, enquanto uma consulta SQD é executada em uma rede de dados descentralizada. Os dados do SQD vêm de sistemas de coleta e indexação on-chain, oferecendo um acesso a dados mais aberto e verificável.
Por que a velocidade de consulta do SQD é mais rápida do que algumas solicitações RPC?
O SQD realiza indexação e organização antecipadamente, portanto as consultas não precisam escanear novamente grandes quantidades de histórico de blocos. Para análises complexas e tarefas com dados históricos, o SQD é geralmente muito mais rápido.
Qual é o papel dos Worker nodes no processo de consulta?
Os Worker nodes são responsáveis pela indexação, filtragem, agregação e computação. Quando o Portal recebe uma solicitação de consulta, os Worker nodes relevantes realizam o processamento real dos dados.
Qual é a diferença entre um data lake e um banco de dados?
Um banco de dados normalmente armazena dados estruturados, enquanto um data lake pode armazenar grandes volumes de dados brutos e semiestruturados. O SQD usa um data lake para armazenar o histórico on-chain completo, suportando consultas e análises flexíveis.
O Hotblocks pode substituir consultas de dados históricos?
Não. O Hotblocks foi projetado para acesso a dados em tempo real; as consultas históricas ainda dependem do data lake e do sistema de indexação. Juntos, eles formam a capacidade completa de serviço de dados do SQD.
Quais aplicações são mais adequadas para os serviços de consulta do SQD?
Dashboards DeFi, exploradores de blockchain, plataformas de análise on-chain, sistemas de monitoramento em tempo real, aplicações multicadeia e Agentes de IA — qualquer cenário que exija acesso frequente a dados on-chain, são ideais para os serviços de consulta do SQD.








