Futuros
Aceda a centenas de contratos perpétuos
CFD
Ouro
Plataforma de ativos tradicionais globais
Opções
Hot
Negoceie Opções Vanilla ao estilo europeu
Conta Unificada
Maximize a eficiência do seu capital
Negociação de demonstração
Introdução à negociação de futuros
Prepare-se para a sua negociação de futuros
Eventos de futuros
Participe em eventos para recompensas
Negociação de demonstração
Utilize fundos virtuais para experimentar uma negociação sem riscos
Lançamento
CandyDrop
Recolher doces para ganhar airdrops
Launchpool
Faça staking rapidamente, ganhe potenciais novos tokens
HODLer Airdrop
Detenha GT e obtenha airdrops maciços de graça
Pre-IPOs
Desbloquear acesso completo a IPO de ações globais
Pontos Alpha
Negoceie ativos on-chain para airdrops
Pontos de futuros
Ganhe pontos de futuros e receba recompensas de airdrop
Investimento
Simple Earn
Ganhe juros com tokens inativos
Investimento automático
Invista automaticamente de forma regular.
Investimento Duplo
Aproveite a volatilidade do mercado
Soft Staking
Ganhe recompensas com staking flexível
Empréstimo de criptomoedas
0 Fees
Dê em garantia uma criptomoeda para pedir outra emprestada
Centro de empréstimos
Centro de empréstimos integrado
Promoções
Centro de atividades
Participe de atividades para recompensas
Referência
20 USDT
Convide amigos para recompensas de ref.
Programa de afiliados
Ganhe recomp. de comissão exclusivas
Gate Booster
Aumente a influência e ganhe airdrops
Announcements
Atualizações na plataforma em tempo real
Blog da Gate
Artigos da indústria cripto
Serviços VIP
Enormes descontos nas taxas
Gestão de ativos
Solução integral para a gestão de ativos
Institucional
Soluções de ativos digitais para empresas
Desenvolvedores (API)
Conecta-se ao ecossistema de aplicações Gate
Transferência Bancária OTC
Deposite e levante moeda fiduciária
Programa de corretora
Mecanismo generoso de reembolso de API
AI
Gate AI
O seu parceiro de IA conversacional tudo-em-um
Gate AI Bot
Utilize o Gate AI diretamente na sua aplicação social
GateClaw
Gate Lagosta Azul, pronto a usar
Gate for AI Agent
Infraestrutura de IA, Gate MCP, Skills e CLI
Gate Skills Hub
Mais de 10 mil competências
Do escritório à negociação, uma biblioteca de competências tudo-em-um torna a IA ainda mais útil
GateRouter
Escolha inteligentemente entre mais de 40 modelos de IA, com 0% de taxas adicionais
A IA Ainda Não Conseguiu Superar o Engenheiro de Plantão: Aqui Está o Porquê
Resumo
Empresas de IA continuam a apresentar agentes autônomos de engenheiros de confiabilidade de site—IA que investiga incidentes de produção no lugar de humanos. A Datadog realizou o benchmark real em falhas reais, e os melhores modelos de IA ainda não conseguem superar os engenheiros que deveriam substituir. O benchmark é o ARFBench (Anomaly Reasoning Framework Benchmark), um projeto conjunto da Datadog e Carnegie Mellon. Construído a partir de 63 incidentes reais de produção, extraídos de conversas no Slack durante emergências ao vivo—750 perguntas de múltipla escolha cobrindo 142 métricas de monitoramento e 5,38 milhões de pontos de dados, todas verificadas manualmente. Sem dados sintéticos. Sem cenários de livro didático. “Trilhões de dólares são perdidos a cada ano devido a falhas de sistema”, escrevem os pesquisadores. O benchmark testa se a IA pode realmente ajudar a mudar isso.
“Apesar do papel central dessa análise orientada por perguntas na resposta a incidentes, ainda não está claro se os modelos de fundação modernos podem responder de forma confiável aos tipos de perguntas de séries temporais que os engenheiros fazem na prática”, lê-se no artigo. As perguntas aparecem em três níveis. Nível I: Existe uma anomalia neste gráfico? Nível II: Quando começou, quão severa é, que tipo? O Nível III—o mais difícil—exige raciocínio entre métricas: Este gráfico está causando o problema naquele outro gráfico? É aí que a IA falha. GPT-5 pontua apenas 47,5% de F1 em perguntas de Nível III, uma métrica que penaliza modelos por tentarem manipular as respostas escolhendo a classe mais comum.
“Apesar do papel central dessa análise orientada por perguntas na resposta a incidentes, ainda não está claro se os modelos de fundação modernos podem responder de forma confiável aos tipos de perguntas de séries temporais que os engenheiros fazem na prática”, escrevem os pesquisadores. Como cada modelo se saiu GPT-5 liderou todos os modelos existentes com 62,7% de precisão—num teste onde chutar aleatoriamente dá 24,5%. Gemini 3 Pro marcou 58,1%. Claude Opus 4.6: 54,8%. Claude Sonnet 4.5: 47,2%. Especialistas de domínio atingiram 72,7% de precisão. Não especialistas—pesquisadores de séries temporais na Datadog sem vasta experiência em observabilidade—ainda assim alcançaram 69,7%. Nenhum modelo de IA superou qualquer uma das linhas de base humanas.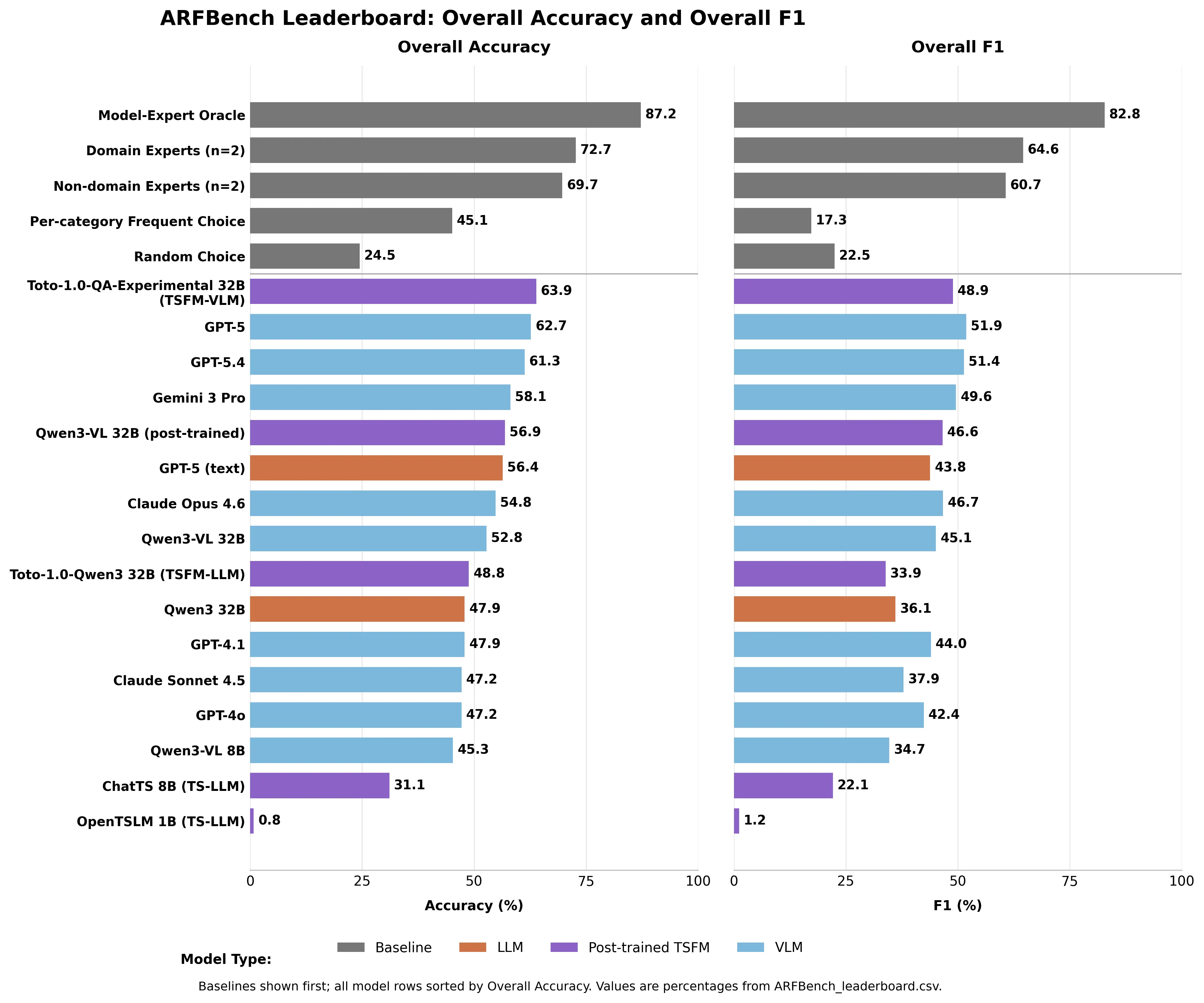
Imagem criada pela Decrypt com base no CSV do leaderboard do ARFBench
O modelo que realmente liderou a classificação geral foi o híbrido da própria Datadog: Toto—seu modelo interno de previsão de séries temporais—combinado com Qwen3-VL 32B. Toto-1.0-QA-Experimental atingiu 63,9% de precisão, superando o GPT-5 usando uma fração de seus parâmetros. Especificamente na identificação de anomalias, superou todos os outros modelos por pelo menos 8,8 pontos percentuais em F1. Um modelo de domínio feito sob medida, treinado com dados de observabilidade, superando um sistema de uso geral de fronteira nesta tarefa específica é o resultado esperado. Essa é a ideia. A descoberta mais valiosa não é qual modelo obteve a maior pontuação. “Observamos perfis de erro substancialmente diferentes entre os modelos líderes e os especialistas humanos, sugerindo que suas forças são complementares”, escrevem os pesquisadores. Os modelos inventam, perdem metadados e perdem o contexto de domínio. Humanos interpretam mal timestamps precisos e ocasionalmente falham em instruções complexas. Os erros quase não se sobrepõem.
Modele um “Modelo-Especialista Oracle” teórico—um juiz perfeito que sempre escolhe a resposta certa entre a IA e o humano—e você obtém 87,2% de precisão e 82,8% de F1. Muito acima de qualquer um isoladamente. Isso não é um produto. É uma meta documentada—construída a partir de emergências reais, não de conjuntos de dados curados—que quantifica exatamente o quanto a colaboração humano-IA poderia performar melhor. O leaderboard está ao vivo no Hugging Face. GPT-5 está em 62,7%. O limite superior é 87,2%.