Моделі прогнозування цін на криптовалюту на основі машинного навчання: від LSTM до трансформатора
Ринок криптовалюти відомий своєю екстремальною волатильністю, що надає значні можливості для інвесторів, але також значні ризики. Точний прогноз цін має вирішальне значення для обґрунтованих інвестиційних рішень. Однак традиційні методи фінансового аналізу часто мають проблеми з управлінням складністю і швидкими змінами криптовалютного ринку. Останнім часом розвиток машинного навчання надав потужні інструменти для прогнозування фінансових часових рядів, особливо в прогнозуванні цін на криптовалюту.
Алгоритми машинного навчання можуть навчитися на великих обсягах історичних даних про ціни та іншу відповідну інформацію, виявляючи складні шаблони, які складно виявити для людей. Серед різних моделей машинного навчання Рекурентні Нейронні Мережі (RNN) та їх варіанти, такі як Довготривала Короткочасна Пам'ять (LSTM) та моделі Трансформера, здобули широку увагу завдяки їх винятковій здатності обробляти послідовні дані, що показують зростаючий потенціал у прогнозуванні цін на криптовалюту. Ця стаття пропонує глибинний аналіз моделей на основі машинного навчання для прогнозування цін на криптовалюту, зосереджуючись на порівнянні застосувань LSTM та Трансформера. Вона також досліджує, як інтеграція різноманітних джерел даних може підвищити продуктивність моделі та розглядає вплив подій чорного лебедя на стійкість моделі.
Застосування машинного навчання в передбаченні цін криптовалют
Основна ідея машинного навчання полягає в тому, щоб дати змогу комп'ютерам навчатися на великих наборах даних і робити прогнози на основі вивчених закономірностей. Ці алгоритми аналізують історичні зміни цін, торгові обсяги та інші пов'язані дані для виявлення прихованих тенденцій і закономірностей. Загальні підходи включають аналіз регресії, дерева рішень та нейронні мережі, які широко використовуються в побудові моделей прогнозування цін криптовалют.
Більшість досліджень ґрунтувалися на традиційних статистичних методах на початкових етапах прогнозування цін на криптовалюти. Наприклад, близько 2017 року, до поширення глибокого навчання, багато досліджень використовували моделі ARIMA для прогнозування тенденцій цін на криптовалюти, такі як Bitcoin. Представницьке дослідження Донга, Лі та Гонга (2017) використовувало модель ARIMA для аналізу волатильності Bitcoin, демонструючи стабільність та надійність традиційних моделей в ухваленні лінійних тенденцій.
З технологічними досягненнями, методи глибокого навчання почали показувати проривні результати в прогнозуванні фінансових часових рядів до 2020 року. Зокрема, мережі довгострокової пам'яті (LSTM) набули популярності через їхню здатність захоплювати довгострокові залежності в даних часових рядів. вивченняПател та ін. (2019) довели переваги LSTM у прогнозуванні цін на Bitcoin, що є значним досягненням на той момент.
До 2023 року моделі трансформаторів, з їх унікальними механізмами самоуваги, здатними захоплювати взаємозв'язки по всій послідовності даних одночасно, все частіше застосовувалися для прогнозування фінансових часових рядів. Наприклад, у 2023 році Зао і його співавтори.вивчення“Увага! Трансформатор зі сентиментом щодо прогнозування цін на криптовалюти” успішно інтегрував моделі трансформатора з даними про сентимент у соціальних мережах, що значно покращило точність прогнозування тенденцій цін на криптовалюти, що є важливою подією в цій галузі.

Вікові події в технології передбачення криптовалюти (Джон, автор Gate Learn)
Серед багатьох моделей машинного навчання, моделі глибокого навчання — зокрема Рекурентні нейронні мережі (RNN) та їх вдосконалені версії, LSTM та Трансформер — продемонстрували значні переваги в роботі з часовими рядами даних. RNN спеціально призначені для обробки послідовних даних шляхом передачі інформації з попередніх кроків на наступні, ефективно захоплюючи залежності між часовими точками. Однак традиційні RNN мають проблему "зникливого градієнту" при роботі з довгими послідовностями, що призводить до поступової втрати старої, але важливої інформації. Для вирішення цього LSTM вводить пам'ятні комірки та механізми воріт на основі RNN, що дозволяє довготривалу збереженість ключової інформації та краще моделювання довгострокових залежностей. Оскільки фінансові дані, такі як історичні ціни криптовалют, мають виражені тимчасові характеристики, моделі LSTM особливо підходять для прогнозування таких тенденцій.
З іншого боку, моделі-трансформери спочатку були розроблені для обробки мови. Механізм самоуваги дозволяє моделі розглядати взаємозв'язки по всій послідовності даних одночасно, а не обробляти їх крок за кроком. Ця архітектура надає трансформаторам величезний потенціал у прогнозуванні фінансових даних з складними часовими залежностями.
Порівняння моделей прогнозування
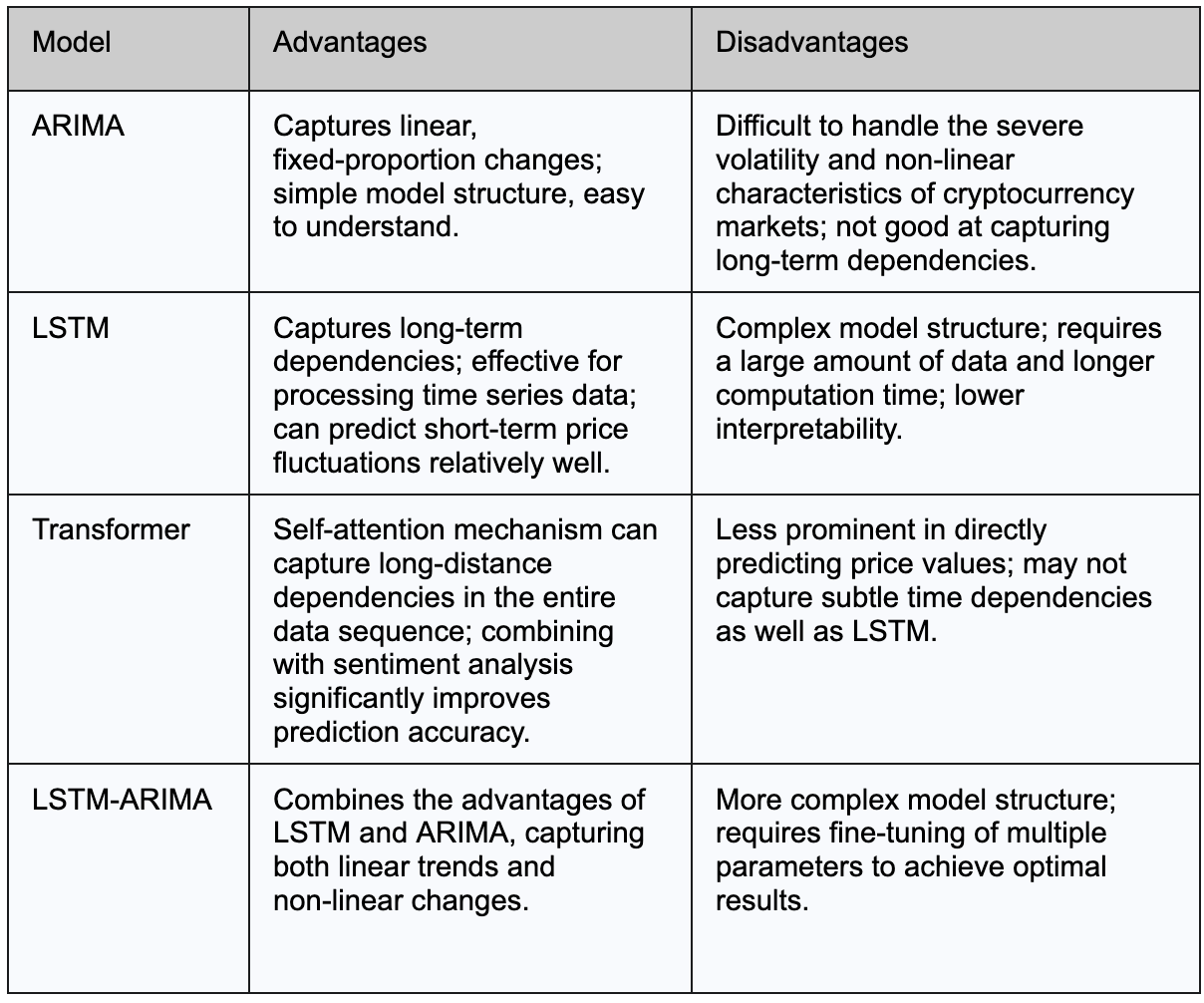
Традиційні моделі, такі як ARIMA, часто використовуються як базові порівняно з моделями глибинного навчання в передбаченні цін на криптовалюту. ARIMA призначений для захоплення лінійних тенденцій та постійних пропорційних змін в даних, добре виконує завдання багатьох прогнозних завдань. Однак через високу волатильність та складний характер цін на криптовалюту лінійні припущення ARIMA часто не виправдовуються.Дослідження показалищо моделі глибокого навчання, як правило, надають більш точні прогнози на нелинійних і дуже змінних ринках.
Серед підходів глибокого навчання, дослідження порівняння моделей LSTM та трансформаторів у передбаченні цін на Bitcoin показало, що LSTM працює краще при захопленні більш докладних деталей короткострокових змін цін. Ця перевага в основному пояснюється механізмом пам'яті LSTM, який дозволяє йому ефективніше та стабільніше моделювати короткострокові залежності. Хоча LSTM може перевершувати у точності короткострокового прогнозування, моделі трансформаторів залишаються дуже конкурентоспроможними. Коли їх покращують додатковими контекстними даними, такими як аналіз настроїв з Twitter, трансформатори можуть пропонувати ширше розуміння ринку, значно покращуючи прогностичну продуктивність.
Більше того, деякі дослідження досліджували гібридні моделі, які поєднують глибоке навчання з традиційними статистичними підходами, такими як LSTM-ARIMA. Ці гібридні моделі спрямовані на захоплення як лінійних, так і нелінійних закономірностей в даних, що подальше покращує точність прогнозу та стійкість моделі.
Таблиця нижче узагальнює ключові переваги та недоліки моделей ARIMA, LSTM та Transformer у прогнозуванні ціни Bitcoin:
Покращення точності прогнозування за допомогою інженерії ознак
Прогнозуючи ціни на криптовалюти, ми не покладаємося виключно на історичні дані про ціни — ми також враховуємо додаткову цінну інформацію, щоб допомогти моделям робити більш точні прогнози. Цей процес називається інженерією функцій, який передбачає організацію та побудову «функцій» даних, які підвищують продуктивність прогнозування.
Джерела загальних функцій даних
Дані на ланцюжку
Дані ланцюгавказує на всю інформацію про транзакції та активність, записану в блокчейні, включаючи торговий обсяг, кількість активних адрес.складність майнінгу, та швидкість хешування. Ці показники безпосередньо відображають динаміку подання та попиту на ринку та загальну активність мережі, що робить їх дуже цінними для прогнозування цін. Наприклад, значний стрибок обсягу торгів може сигналізувати про зміну настроїв на ринку, тоді як збільшення активних адрес може вказувати на більш широке прийняття, що потенційно підніматиме ціни вгору.
Такі дані зазвичай отримують доступ до API-дослідників блокчейну або спеціалізованих постачальників даних, таких як Glassnode та Монетні метрикиВи можете використовувати бібліотеку запитів Python для виклику API або безпосереднього завантаження файлів CSV для аналізу.
Індикатори настроїв у соціальних мережах
Платформи, як Santimentаналізувати вміст тексту з джерел, таких як Twitter та Reddit, щоб оцінити настрій учасників ринку щодо криптовалют. Вони подальше застосовують техніки обробки природної мови (NLP), такі як аналіз настрою, щоб перетворити цей текст у показники настрою. Ці показники відображають думки та очікування інвесторів, пропонуючи цінні відомості для прогнозування цін. Наприклад, переважно позитивний настрій у соціальних мережах може привернути більше інвесторів та підняти ціни, тоді як негативний настрій може викликати продажний тиск. Платформи, такі як Santiment, також надають API та інструменти для допомоги розробникам інтегрувати дані настрою в моделі прогнозування.Дослідження показалищо включення аналізу настроїв у соціальних мережах може значно підвищити ефективність моделей прогнозування цін криптовалют, особливо для короткострокових прогнозів.

Santiment може надати дані про настрої учасників ринку щодо криптовалют (Джерело: Santiment)
Макроекономічні Фактори
Макроекономічні показники, такі як процентні ставки, інфляція, зростання ВВП та рівень безробіття, також впливають на ціни криптовалют. Ці фактори впливають на ризикові уподобання і потоки капіталу інвесторів. Наприклад, інвестори можуть переміщати кошти з високоризикових активів, таких як криптовалюти, до безпечніших альтернатив, коли зростають процентні ставки, що призводить до падіння цін. З іншого боку, коли зростає інфляція, інвестори можуть шукати засоби збереження вартості — Біткоін іноді розглядають як захист від інфляції.
Дані про процентні ставки, інфляцію, зростання ВВП та безробіття зазвичай можна отримати від національних урядів або міжнародних організацій, таких як Світовий банк або МВФ. Ці набори даних зазвичай доступні у форматі CSV або JSON і можуть бути отримані за допомогою бібліотек Python, таких як pandas_datareader.
Наступна таблиця узагальнює загальновживані дані on-chain, показники настроїв у соціальних мережах та макроекономічні фактори, а також те, як вони можуть впливати на ціни криптовалют:

Як інтегрувати дані ознак
Загалом цей процес можна розбити на кілька кроків:
1. Очищення даних та стандартизація
Дані з різних джерел можуть мати різні формати, деякі можуть бути відсутніми або неоднорідними. У таких випадках необхідне очищення даних. Наприклад, перетворення всіх даних у той самий формат дати, заповнення відсутніх даних і стандартизація даних, щоб їх можна було легше порівняти.
2. Інтеграція даних
Після очищення дані з різних джерел об'єднуються за датами, створюючи повний набір даних, що показує ринкові умови на кожен день.
3. Побудова вхідного моделі
На останок ці інтегровані дані перетворюються у формат, який модель може зрозуміти. Наприклад, якщо ми хочемо, щоб модель передбачила ціну на сьогодні на основі даних з минулих 60 днів, ми організуємо дані з цих 60 днів у список (або матрицю), яка служитиме в якості введення моделі. Модель вивчає відносини в цих даних для передбачення майбутніх тенденцій цін.
Модель може використовувати більш комплексну інформацію для підвищення точності прогнозування через цей процес інженерії ознак.
Приклади проектів з відкритим кодом
На GitHub є багато популярних відкритих проектів з передбачення ціни криптовалюти. Ці проекти використовують різні моделі машинного навчання та глибокого навчання для передбачення тенденцій цін на різні криптовалюти.
Більшість проектів використовують популярні фреймворки глибокого навчання, такі як TensorFlowабоKerasщоб побудувати та навчити моделі, вивчати шаблони з історичних даних про ціни та передбачати майбутні рухи цін. Весь процес зазвичай включає підготовку даних (таку як організацію та стандартизацію історичних даних про ціни), побудову моделі (визначення шарів LSTM та інших необхідних шарів), навчання моделі (налаштування параметрів моделі через великий набір даних для зменшення помилок передбачення) та остаточну оцінку та візуалізацію результатів передбачення.
Один з таких проектів, який використовує техніки глибокого навчання для прогнозування цін на криптовалюту, єDat-TG/Криптовалюта-Цінові-Прогнози.
Основна мета цього проекту полягає в тому, щоб використовувати модель LSTM для прогнозування закритих цін на біткоїн (BTC-USD), ефіріум (ETH-USD) та кардано (ADA-USD), щоб допомогти інвесторам краще розуміти тенденції на ринку. Користувачі можуть клонувати сховище GitHub та запустити програму локально, дотримуючись наданих інструкцій.

Результати прогнозування BTC для проекту (Джерело: Панель цін криптовалют)
Структура коду цього проекту чітка, з окремими скриптами та Jupyter Notebooks для отримання даних, навчання моделі та запуску веб-додатка. На основі структури каталогу проекту та внутрішньої код, процес побудови прогностичної моделі виглядає наступним чином:
- Дані завантажуються з Yahoo Finance, а потім очищаються і організовуються за допомогою Pandas, включаючи завдання, такі як стандартизація формату дати та заповнення відсутніх значень.
- Оброблені дані генерують "кочуюче вікно", використовуючи минулі 60 днів даних для прогнозування ціни на 61-й день.
- Дані потім подаються в модель, побудовану за допомогою LSTM (довга короткострокова пам'ять). LSTM ефективно пам'ятає короткострокові та довгострокові зміни цін, що робить його добре підходящим для прогнозування тенденцій цін.
- Результати прогнозування та фактичні ціни відображаються за допомогою різних графіків через Plotly Dash, з випадаючим меню, що дозволяє користувачам вибирати різні криптовалюти або технічні індикатори, оновлюючи графіки в реальному часі.

Структура каталогу проекту (Джерело: Криптовалюта-Цінова-Прогноз)
Аналіз ризику моделі прогнозування ціни криптовалюти
Вплив чорних лебедів на стабільність моделі
Подія Чорного Лебедя є надзвичайно рідкісною та непередбачуваною з масивним впливом. Ці події зазвичай виходять за межі очікувань традиційних прогностичних моделей та можуть спричинити значні ринкові розлади. Типовим прикладом є Крах Луниу травні 2022 року.
Луна, як проект алгоритмічної стейблкоїну, поклався на складний механізм зі своєю сестринською токеном LUNA для стабільності. На початку травня 2022 року стейблкоїн UST Луни почав розлачатися від долара США, що призвело до панічної продажу інвесторами. У зв'язку з недоліками алгоритмічного механізму, руйнування UST призвело до драматичного збільшення обсягу LUNA. Протягом кількох днів ціна LUNA впала з майже 80 доларів практично до нуля, ухиляючись від сотень мільярдів доларів ринкової вартості. Це призвело до значних втрат для залучених інвесторів і викликало широкомасштабні обурення щодо системних ризиків на ринку криптовалют.
Таким чином, коли стається подія Чорного Лебедя, традиційні моделі машинного навчання, навчені на історичних даних, ймовірно, ніколи не стикалися з такими екстремальними ситуаціями, що призводить до невдачі моделей у точних прогнозах або навіть до видачі вводних результатів.
Внутрішні ризики моделі
Крім подій Чорного Лебедя, ми також повинні бути усвідомлені деяких вроджених ризиків у самій моделі, які можуть поступово накопичуватися та впливати на точність прогнозування під час щоденного використання.
(1) Data Skew and Outliers
У фінансових часових рядинах дані часто виявляють асиметрію або містять викиди. Якщо не проводиться належна підготовка даних, процес навчання моделі може бути порушений шумом, що вплине на точність прогнозування.
(2) Переспрощені моделі та недостатня перевірка
Деякі дослідження можуть надто сильно покладатися на одну математичну структуру при конструюванні моделей, наприклад, використовуючи лише модель ARIMA для захоплення лінійних тенденцій, ігноруючи при цьому нелінійні фактори на ринку. Це може призвести до занадто спрощення моделі. Крім того, недостатня перевірка моделі може призвести до занадто оптимістичної віддачі на тестуванні, але погані результати передбачення в реальних застосуваннях (наприклад, перетренуванняпризводить до відмінної продуктивності на історичних даних, але суттєво відхиляється в реальному використанні).
(3) Ризик запізнення даних API
У живій торгівлі, якщо модель покладається на API для отримання даних в реальному часі, будь-яке затримка в API або невдале оновлення даних вчасно може безпосередньо вплинути на роботу моделі та результати прогнозування, що призведе до невдачі в живій торгівлі.
Заходи для підвищення стабільності моделі прогнозування
У зв'язку з ризиками, згаданими вище, необхідно прийняти відповідні заходи для покращення стабільності моделі. Надзвичайно важливі наступні стратегії:
(1) Різноманітні джерела даних та попередня обробка даних
Поєднання декількох джерел даних (таких як історичні ціни, обсяг угод, дані соціального настрою тощо) може компенсувати недоліки однієї моделі, тоді як жорстке очищення, трансформація та розбиття даних повинні бути проведені. Цей підхід підвищує загальну здатність моделі та зменшує ризики, що виникають від відхилень та викидів даних.
(2) Вибір відповідних метрик оцінки моделі
Під час процесу побудови моделі важливо вибрати відповідні метрики оцінки на основі характеристик даних (таких як MAPE, RMSE, AIC, BIC тощо), щоб комплексно оцінити продуктивність моделі та уникнути перенавчання. Регулярна перехресна перевірка та прогнозування на основі ковзного вікна також є критичними кроками для покращення стійкості моделі.
(3) Підтвердження моделі та ітерація
Після того, як модель встановлена, вона повинна пройти ретельну перевірку за допомогою аналізу залишкових відхилень та механізмів виявлення аномалій. Стратегія прогнозування повинна неперервно коригуватися на основі змін на ринку. Наприклад, введення контекстно-орієнтованого навчання для коригування параметрів моделі відповідно до поточних умов ринку динамічно - це один підхід. Крім того, поєднання традиційних моделей з моделями глибокого навчання для формування гібридної моделі є ефективним методом для покращення точності та стабільності прогнозування.
Увага до ризиків відповідності
Нарешті, крім технічних ризиків, слід враховувати ризики конфіденційності даних та дотримання правил при використанні непристрійних джерел даних, таких як дані про настрій. Наприклад, Комісія з цінних паперів та бірж США (SEC) має строгі вимоги щодо збору та використання даних про настрій для запобігання правових ризиків, пов'язаних з проблемами конфіденційності.
Це означає, що під час процесу збору даних особиста ідентифікована інформація (така як імена користувачів, особисті дані тощо) повинна бути анонімізована. Це спрямовано на запобігання викриттю особистої конфіденційності, а також уникання неправильного використання даних. Крім того, важливо забезпечити легітимність джерел зібраних даних і уникати їх отримання неправомірними засобами (наприклад, несанкціонований веб-скрапінг). Також необхідно публічно розголошувати методи збору та використання даних, що дозволяє інвесторам та регулюючим органам розуміти, як дані обробляються та застосовуються. Ця прозорість допомагає запобігти використанню даних для маніпулювання настроями на ринку.
Висновок та перспективи майбутнього
У висновку можна сказати, що моделі прогнозування цін на криптовалюту на основі машинного навчання показують великий потенціал у вирішенні волатильності та складності ринку. Інтеграція стратегій управління ризиками та постійне дослідження нових архітектур моделей та методів інтеграції даних буде важливими напрямками для майбутнього розвитку прогнозування цін на криптовалюту. З розвитком технологій машинного навчання ми вважаємо, що з'являться більш точні та стабільні моделі прогнозування цін на криптовалюту, які нададуть інвесторам сильну підтримку в процесі прийняття рішень.
Поділіться


Пов’язані статті

Як провести власне дослідження (DYOR)?
Дослідження 8 основних агрегаторів DEX: Двигуни, що забезпечують ефективність та ліквідність на крипторинку

Що таке фундаментальний аналіз?

Що таке Технічний аналіз?

Що таке альткойни?
