Ф'ючерси
Сотні безстрокових контрактів
CFD
Золото
Одна платформа для світових активів
Опціони
Hot
Торгівля ванільними опціонами європейського зразка
Єдиний рахунок
Максимізуйте ефективність вашого капіталу
Демо торгівля
Вступ до ф'ючерсної торгівлі
Підготуйтеся до ф’ючерсної торгівлі
Ф'ючерсні події
Заробляйте, беручи участь в подіях
Демо торгівля
Використовуйте віртуальні кошти для безризикової торгівлі
Запуск
CandyDrop
Збирайте цукерки, щоб заробити аірдропи
Launchpool
Швидкий стейкінг, заробляйте нові токени
HODLer Airdrop
Утримуйте GT і отримуйте масові аірдропи безкоштовно
Pre-IPOs
Отримайте повний доступ до глобальних IPO акцій.
Alpha Поінти
Ончейн-торгівля та аірдропи
Ф'ючерсні бали
Заробляйте фʼючерсні бали та отримуйте аірдроп-винагороди
Інвестиції
Simple Earn
Заробляйте відсотки за допомогою неактивних токенів
Автоінвестування
Автоматичне інвестування на регулярній основі
Подвійні інвестиції
Прибуток від волатильності ринку
Soft Staking
Earn rewards with flexible staking
Криптопозика
0 Fees
Заставте одну криптовалюту, щоб позичити іншу
Центр кредитування
Єдиний центр кредитування
Центр багатства VIP
Преміальні плани зростання капіталу
Управління приватним капіталом
Розподіл преміальних активів
Квантовий фонд
Квантові стратегії найвищого рівня
Стейкінг
Стейкайте криптовалюту, щоб заробляти на продуктах PoS
Розумне кредитне плече
Кредитне плече без ліквідації
Випуск GUSD
Мінтинг GUSD для прибутку RWA
Акції
Центр діяльності
Беріть учать та отримуйте винагороди
Реферал
20 USDT
Запрошуйте друзів та отримуйте бонуси
Партнерська програма
Ексклюзивні комісійні винагороди
Gate Booster
Зростайте та отримуйте аірдропи
Оголошення
Оновлення платформи в реальному часі
Блог Gate
Статті про криптоіндустрію
VIP послуги
Величезні знижки на комісії
Управління активами
Універсальне рішення для управління активами
Інституційний
Рішення цифрових активів для бізнесу
Розробники (API)
Підключається до екосистеми додатків Gate
Позабіржовий банківський переказ
Поповнюйте та виводьте фіат
Брокерська програма
Щедрі механізми знижок API
AI
Gate AI
Ваш універсальний AI-помічник для спілкування
Gate AI Bot
Використовуйте Gate AI безпосередньо у своєму соціальному додатку
GateClaw
Gate Блакитний Лобстер — готовий до використання
Gate for AI Agent
AI-інфраструктура, Gate MCP, Skills і CLI
Gate Skills Hub
Понад 10 000 навичок
Від офісу до трейдингу: універсальна база навичок для ефективнішої роботи з AI
GateRouter
Розумний вибір із понад 40 моделей ШІ, без додаткових витрат (0%)
Штучний інтелект все ще не може перевершити чергового інженера: ось чому
Коротко
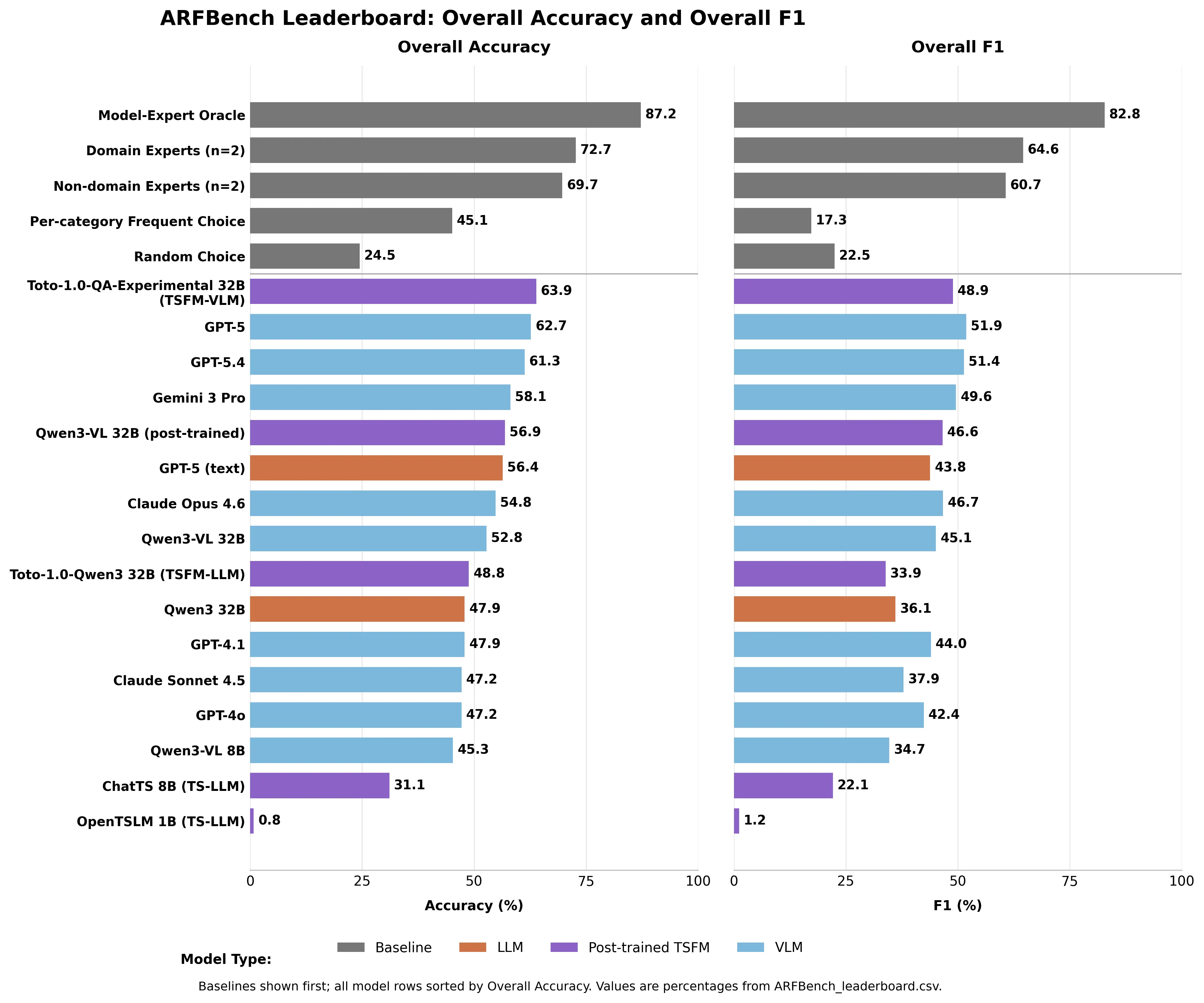
* ARFBench — перший тестовий стенд AI, створений цілком на основі реальних інцидентів у виробництві.
* GPT-5 лідирує серед усіх існуючих моделей AI з точністю 62,7%, але поступається експертам у галузі з 72,7%.
* Теоретична модель-експерт-оракул — поєднання AI та людського судження — досягає 87,2% точності, встановлюючи межу для того, чого можуть досягти колаборативні команди AI і людини.
Компанії з AI продовжують пропонувати автономних агентів з обслуговування надійності сайтів — AI, що досліджує інциденти у виробництві замість людей. Datadog провів реальний тест на справжніх збої, і найкращі моделі AI ще не можуть перевершити інженерів, яких вони мають замінити.
Тестовий стенд — ARFBench (Anomaly Reasoning Framework Benchmark), спільний проект Datadog і Карнегі-Меллон. Створений на основі 63 реальних інцидентів у виробництві, витягнутих із Slack-ланцюгів інженерів під час аварій — 750 питань з множинним вибором, що охоплюють 142 метрики моніторингу та 5,38 мільйонів даних, кожне питання перевірене вручну. Жодних синтетичних даних. Жодних сценаріїв із підручників.
"Триліони доларів щороку втрачаються через збої систем," — пишуть дослідники. Тестовий стенд перевіряє, чи може AI справді допомогти змінити цю ситуацію.
"Незважаючи на центральну роль аналізу, орієнтованого на питання, у реагуванні на інциденти, досі неясно, чи можуть сучасні базові моделі надійно відповідати на типи питань про часові ряди, які інженери ставлять на практиці," — йдеться у статті.
Питання поділяються на три рівні. Рівень I: Чи існує аномалія на цьому графіку? Рівень II: Коли вона почалася, наскільки вона серйозна, який тип?
Рівень III — найскладніший — вимагає міжметричного аналізу: Чи спричиняє цей графік проблему в іншому графіку? Саме тут AI руйнується. GPT-5 показує лише 47,5% F1 на питаннях рівня III, метриці, яка карає моделі за ігнорування відповіді, що ґрунтується на найпоширенішому класі.
"Незважаючи на центральну роль аналізу, орієнтованого на питання, у реагуванні на інциденти, досі неясно, чи можуть сучасні базові моделі надійно відповідати на типи питань про часові ряди, які інженери ставлять на практиці," — пишуть дослідники.
Як кожна модель показала себе
GPT-5 лідирує серед усіх моделей із точністю 62,7% — на тесті, де випадкове вгадування дає 24,5%. Gemini 3 Pro — 58,1%. Claude Opus — 54,8%. Claude Sonnet — 47,2%.
Експерти-галузевики — 72,7%. Неекспертні інженери з досліджень часових рядів у Datadog без глибокого досвіду в обсервабельності — 69,7%.
Жодна модель AI не перевершила жодну людську базову лінію.
Зображення створене Decrypt на основі CSV-таблиці ARFBench лідерборду
Модель, яка фактично очолила весь рейтинг — це гібрид Datadog: Toto — їхня внутрішня модель прогнозування часових рядів — у поєднанні з Qwen3-VL 32B. Toto-1.0-QA-Experimental показала 63,9% точності, обігнавши GPT-5, використовуючи при цьому менше параметрів. Щодо ідентифікації аномалій, вона перевершила всі інші моделі щонайменше на 8,8 пунктів у F1.
Цільова модель, спеціально створена для галузі, навчена на даних обсервабельності, перевершує передові універсальні системи у цій конкретній задачі — це і є очікуваний результат. Саме це і є суть.
Найціннішим висновком є не те, яка модель набрала найвищий бал.
"Ми спостерігаємо суттєво різні профілі помилок між провідними моделями та людськими експертами, що свідчить про їхню взаємодоповнюваність," — пишуть дослідники. Моделі галюцинують, пропускають метадані та втрачають контекст галузі. Люди неправильно читають точні часові позначки і іноді не справляються з складними інструкціями. Помилки майже не збігаються.
Модель — теоретичний "Модель-Експерт-Оракул" — ідеальний суддя, що завжди обирає правильну відповідь між AI і людиною, — дає 87,2% точності та 82,8% F1. Значно вище за будь-яку з них окремо.
Це не продукт. Це задокументована ціль — створена на основі реальних аварій, а не курованих наборів даних — яка точно кількісно показує, наскільки краще може працювати співпраця людини і AI. Лідерборд доступний на Hugging Face. GPT-5 — 62,7%. Межа — 87,2%.