

- 話題
8075 熱度
10197 熱度
10103 熱度
44857 熱度
412 熱度
- 置頂
- 🎤 爲 KAKA 打 Call · Gate 廣場送 Token of Love 門票!
10 月 1 日|新加坡濱海灣花園 The Meadow
DJ KAKA 即將引爆全場!節拍浪潮的女王將電音十足的能量傾注舞臺!
🎟️ 粉絲專屬福利:現在在廣場爲 KAKA 發帖打 Call,有機會瓜分 20 張演唱會門票,現場感受熱力!
廣場優質發帖:8 張
廣場幸運互動:2 張
Twitter & 小紅書優質發帖:各 5 張
📌 參與方式(越多越容易中獎)
1️⃣ 帖子互動
點讚 + 轉發 + 投票KAKA:https://www.gate.com/post/status/13214134
評論區留言:我在 Gate 廣場爲 Token of Love 打 Call!
2️⃣ 廣場發帖打 Call
帶上 #KAKA# + #TokenOfLove#
內容任選:
最想現場聽的歌
應援口號(例:KAKA 衝鴨!Gate 廣場全員打 Call!)
自制表情包/海報/短視頻(加分項)
3️⃣ Twitter / 小紅書發帖打 Call
帶上 #KAKA# + #TokenOfLove# + #Gate广场#
內容同上,並回鏈表單 👉 https://www.gate.com/questionnaire/7008
💡 優質帖文標準:內容豐富、創意滿分、熱度高。禁止水貼,原創更容易中獎!
⏰ - 🎁 GUSD 空投狂歡季:新人享 15 GUSD 獎勵加碼,單人可衝 960 GUSD 大獎
👉 立即參與:https://www.gate.com/campaigns/1895
✅ 新一輪空投嘉年華來襲,本次活動將爲新老用戶送上 GUSD 空投狂歡
✅ 單人可衝 960 GUSD 豪禮,新人登場可領 15 GUSD 獎勵
簡單參與任務,即可贏取 GUSD 大獎!
🔗 活動詳情:https://www.gate.com/announcements/article/46833 - 我知道大家一直在关注,想找低风险又稳健的投资方式——我非常理解,尤其是在波动大的币圈里,赚了钱之後还要一直稳妥的守住,有一点「安全感」真的很重要。
这也是我对 GUSD 上线 Gate 感到兴奋的原因。GUSD 它有真实资产背书,比如美国国债,1:1 可兑换交易,还能赚取稳健收益,让你参与市场的同时,不用总是担心风险。对我来说,投资就是要找到平衡:既抓住机会,又能保持安全感。废话不多说,大家准备好试试了吗? - 🔥 Gate Alpha 限時賞金活動第三期上線!
在 Alpha 區交易熱門代幣,瓜分 $30,000 獎池!
💰 獎勵規則:
1️⃣ 連續2日每日交易滿 128 USDT,即可參與共享 $20,000 美金盲盒獎勵
2️⃣ 累計買入 ≥1,024 USDT,交易量前100名可直領獎勵 100美金盲盒
⏰ 活動時間:8月29日 16:00 — 8月31日 16:00 (UTC+8)
👉 立即參與交易: https://www.gate.com/announcements/article/46841
#GateAlpha # #GateAlphaPoints # #onchain# - GM,家人們!還不知道如何參與Gate廣場內容挖礦賺取收益?
速速碼住下圖 #内容挖矿# 參與五部曲 👇️
教你快速掌握賺取最高達10%挖礦返佣收益技巧!
讓大模型看圖比打字管用! NeurIPS 2023新研究提出多模態查詢方法,準確率提升7.8%
原文來源:量子位
大模型「識圖」能力都這麼強了,為啥還老找錯東西?
例如,把長得不太像的蝙蝠和拍子搞混,又或是認不出一些數據集中的稀有魚類......
如果描述有歧義或太偏門,像是“bat”(蝙蝠還是拍子? )或“魔鰍”(Cyprinodon diabolis),AI就會大為困惑。
這就導致用大模型做目標檢測、尤其是開放世界(未知場景)目標檢測任務時,效果往往沒有想像中那麼好。
現在,一篇被NeurIPS 2023收錄的論文,終於解決了這個問題。
在基準檢測數據集LVIS上,無需下游任務模型微調,MQ-Det平均提升主流檢測大模型GLIP精度約7.8%,在13個基準小樣本下游任務上,平均提高了**6.3%**精度。
這究竟是怎麼做到的? 一起來看看。
以下內容轉載自論文作者、知乎博主@沁園夏:
目錄
MQ-Det:多模態查詢的開放世界目標檢測大模型
**論文名稱:**Multi-modal Queried Object Detection in the Wild
論文連結:
代碼位址:
一圖勝千言:隨著圖文預訓練的興起,藉助文本的開放語義,目標檢測逐漸步入了開放世界感知的階段。 為此,許多檢測大模型都遵循了文本查詢的模式,即利用類別文本描述在目標圖像中查詢潛在目標。 然而,這種方式往往會面臨「廣而不精」的問題。
例如,(1)圖1中的細粒度物體(魚種)檢測,往往很難用有限的文本來描述各種細粒度的魚種,(2)類別歧義(“bat”既可指蝙蝠又可指拍子)。
然而,以上的問題均可通過圖像示例來解決,相比文本,圖像能夠提供目標物體更豐富的特徵線索,但同時文本又具備強大的泛化性。
由此,如何能夠有機地結合兩種查詢方式,成為了一個很自然的想法。
獲取多模態查詢能力的難點:如何得到這樣一個具備多模態查詢的模型,存在三個挑戰:(1)直接用有限的圖像示例進行微調很容易造成災難性遺忘; (2)從頭訓練一個檢測大模型會具備較好的泛化性但是消耗巨大,例如,單卡訓練GLIP 需要利用3000萬數據量訓練480 天。
**多模態查詢目標檢測:**基於以上考慮,作者提出了一種簡單有效的模型設計和訓練策略——MQ-Det。
MQ-Det在已有凍結的文本查詢檢測大模型基礎上插入少量門控感知模組(GCP)來接收視覺示例的輸入,同時設計了視覺條件掩碼語言預測訓練策略高效地得到高性能多模態查詢的檢測器。
1.2 MQ-Det即插即用的多模態查詢模型架構
** **###### △圖1 MQ-Det方法架構圖
**###### △圖1 MQ-Det方法架構圖
門控感知模組
如圖1所示,作者在已有凍結的文本查詢檢測大模型的文本編碼器端逐層插入了門控感知模組(GCP),GCP的工作模式可以用下面公式簡潔地表示:
1.3 MQ-Det高效訓練策略
基於凍結語言查詢檢測器的調製訓練
由於目前文本查詢的預訓練檢測大模型本身就具備較好的泛化性,論文作者認為,只需要在原先文本特徵基礎上用視覺細節進行輕微地調整即可。
在文章中也有具體的實驗論證發現,打開原始預訓練模型參數后進行微調很容易帶來災難性遺忘的問題,反而失去了開放世界檢測的能力。
由此,MQ-Det在凍結文本查詢的預訓練檢測器基礎上,僅調製訓練插入的GCP模組,就可以高效地將視覺資訊插入到現有文本查詢的檢測器中。
在論文中,作者分別將MQ-Det的結構設計和訓練技術應用於目前的SOTA模型GLIP和GroundingDINO ,來驗證方法的通用性。
以視覺為條件的掩碼語言預測訓練策略
作者還提出了一種視覺為條件的掩碼語言預測訓練策略,來解決凍結預訓練模型帶來的學習惰性的問題。
所謂學習惰性,即指檢測器在訓練過程中傾向於保持原始文本查詢的特徵,從而忽視新加入的視覺查詢特徵。
為此,MQ-Det在訓練時隨機地用[MASK] token來替代文本token,迫使模型向視覺查詢特徵側學習,即:
1.4 實驗結果:Finetuning-free評估
Finetuning-free:相比傳統零樣本(zero-shot)評估僅利用類別文本進行測試,MQ-Det提出了一種更貼近實際的評估策略:finetuning-free。 其定義為:在不進行任何下游微調的條件下,使用者可以利用類別文本、圖像示例、或者兩者結合來進行目標檢測。
在finetuning-free的設定下,MQ-Det對每個類別選用了5個視覺示例,同時結合類別文本進行目標檢測,而現有的其他模型不支援視覺查詢,只能用純文本描述進行目標檢測。 下表展示了在LVIS MiniVal和LVIS v1.0上的檢測結果。 可以發現,多模態查詢的引入大幅度提升了開放世界目標檢測能力。
**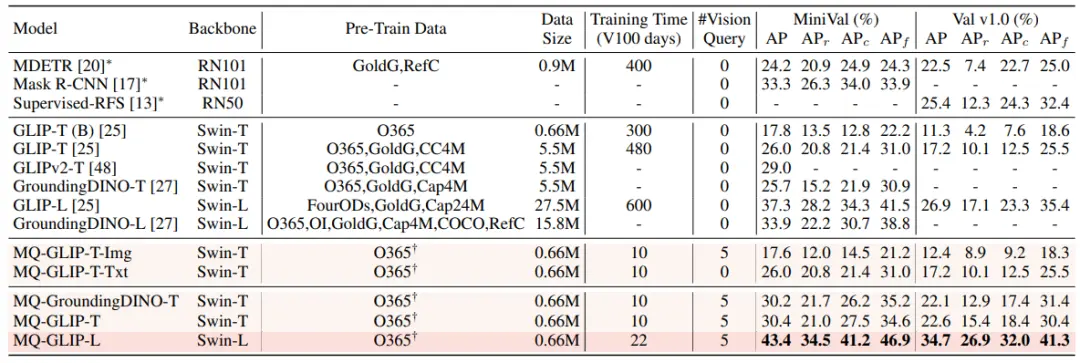 **###### △表1 各個檢測模型在LVIS基準數據集下的finetuning-free表現
**###### △表1 各個檢測模型在LVIS基準數據集下的finetuning-free表現
從表1可以看到,MQ-GLIP-L在GLIP-L基礎上提升了超過7%AP,效果十分顯著!
1.5 實驗結果:Few-shot評估
**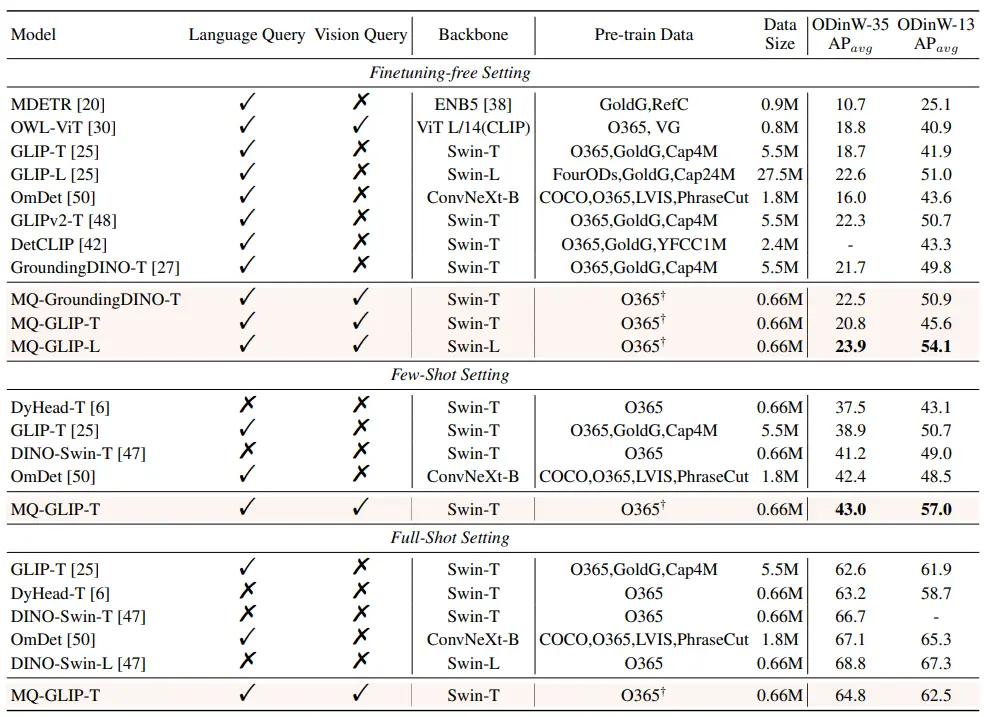 **###### △表2 各個模型在35個檢測任務ODinW-35以及其13個子集ODinW-13中的表現
**###### △表2 各個模型在35個檢測任務ODinW-35以及其13個子集ODinW-13中的表現
作者還進一步在下游35個檢測任務ODinW-35中進行了全面的實驗。 由表2可以看到,MQ-Det除了強大的finetuning-free表現,還具備良好的小樣本檢測能力,進一步印證了多模態查詢的潛力。 圖2也展示了MQ-Det對於GLIP的顯著提升。
**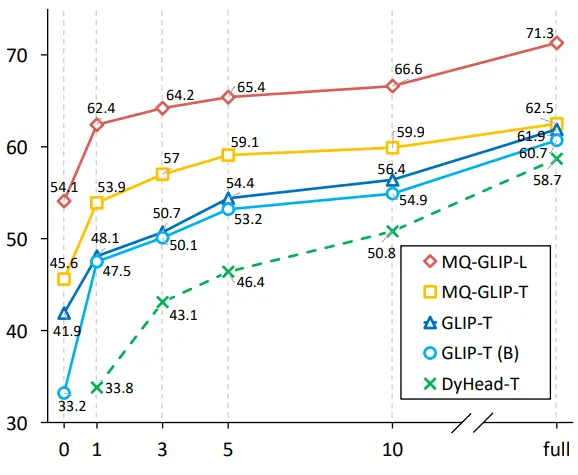 **###### △圖2 數據利用效率對比; 橫軸:訓練樣本數量,縱軸:OdinW-13上的平均AP
**###### △圖2 數據利用效率對比; 橫軸:訓練樣本數量,縱軸:OdinW-13上的平均AP
1.6 多模態查詢目標檢測的前景
目標檢測作為一個以實際應用為基礎的研究領域,非常注重演算法的落地。
儘管以往的純文本查詢目標檢測模型展現出了良好的泛化性,但是在實際的開放世界檢測中文本很難涵蓋細粒度的資訊,而圖像中豐富的資訊粒度完美地補全了這一環。
至此我們能夠發現,文本泛而不精,圖像精而不泛,如果能夠有效地結合兩者,即多模態查詢,將會推動開放世界目標檢測進一步向前邁進。
MQ-Det在多模態查詢上邁出了第一步嘗試,其顯著的性能提升也昭示著多模態查詢目標檢測的巨大潛力。
同時,文本描述和視覺示例的引入為使用者提供了更多的選擇,使得目標檢測更加靈活和使用者友好。
原文連結: