¿Qué es la información on-chain?
La información on-chain es aquella que se registra en una cadena de bloques. Como la cadena de bloques funciona como una base de datos distribuida, estos datos son públicos y cualquier usuario puede acceder a ellos.
Web3 y web2 representan versiones distintas de la World Wide Web, siendo web3 la más avanzada y reciente. Las diferencias fundamentales entre ambas incluyen:
Web3 es descentralizada, mientras que web2 es centralizada. En web3, los datos y servicios los provee una red distribuida de nodos, no una única entidad. Esto hace que web3 sea más resistente y menos susceptible a la censura o a fallos, pero también más compleja y difícil de controlar.
Web3 se fundamenta en la tecnología blockchain, mientras que web2 se basa en la arquitectura tradicional cliente-servidor. En web3, los datos se almacenan y transfieren mediante algoritmos criptográficos, en vez de gestionarse en un servidor central. Esto aporta mayor seguridad y transparencia, aunque también ralentiza los procesos y los encarece.
Web3 está orientada a habilitar nuevas aplicaciones y servicios, mientras que web2 se dedica a optimizar los ya existentes. Así, web3 apuesta por la experimentación y la innovación, mientras que web2 es más madura y consolidada.
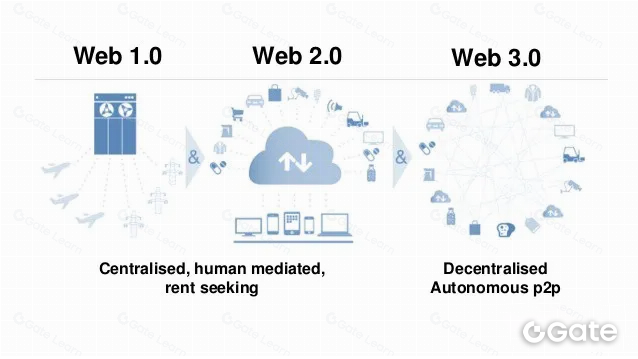
Estas diferencias repercuten en la forma de analizar los datos en cada entorno. En web3, el análisis se centra en comprender el funcionamiento de las redes descentralizadas y la tecnología blockchain subyacente, empleando técnicas avanzadas como aprendizaje automático y análisis de redes para detectar patrones y tendencias. En web2, el foco está en el comportamiento de los usuarios y de las aplicaciones, usando métodos tradicionales como el análisis estadístico y la visualización de datos para identificar tendencias y extraer conclusiones.
Para analizar información on-chain, primero hay que recopilar y organizar los datos relevantes, y después aplicar herramientas como la visualización y el análisis estadístico para identificar patrones y tendencias. Esto permite comprender mejor el comportamiento de la red blockchain y sus usuarios, así como prever la evolución del mercado. En ocasiones, también se pueden emplear técnicas de aprendizaje automático para automatizar el análisis y detectar patrones más complejos.
Categorías de información on-chain
Existen dos tipos principales de datos on-chain:
Datos brutos
Datos abstractos
Se distinguen estas categorías porque todas las métricas calculadas son, en esencia, abstracciones derivadas de los datos brutos. Los datos brutos on-chain son la información sin procesar registrada en la cadena de bloques, incluyendo detalles de transacciones individuales como remitente, destinatario y cantidad transferida de criptomoneda. Los datos económicos, por su parte, se obtienen a partir de los datos brutos y abarcan información sobre la oferta y demanda de una criptomoneda, así como su capitalización de mercado y volumen de trading.
La información económica no solo es una abstracción de los datos brutos, sino que se calcula utilizando diversas técnicas y métricas. Por ejemplo, la capitalización de mercado se determina multiplicando el suministro total de una criptomoneda por su precio actual, y el volumen de trading se calcula sumando todas las transacciones en un periodo concreto. Otras métricas, como la velocidad del dinero y la ratio valor de red/transacción, se obtienen mediante fórmulas más complejas que consideran factores como el número de transacciones y la actividad total de la red.
En general, los datos económicos proporcionan una visión global del mercado de criptomonedas y resultan útiles para analizar tendencias y tomar decisiones de inversión. Sin embargo, es importante recordar que estos datos no siempre reflejan de forma precisa o completa la realidad del mercado, por lo que deben utilizarse con cautela.
Soluciones analíticas diferentes
Centralización vs descentralización
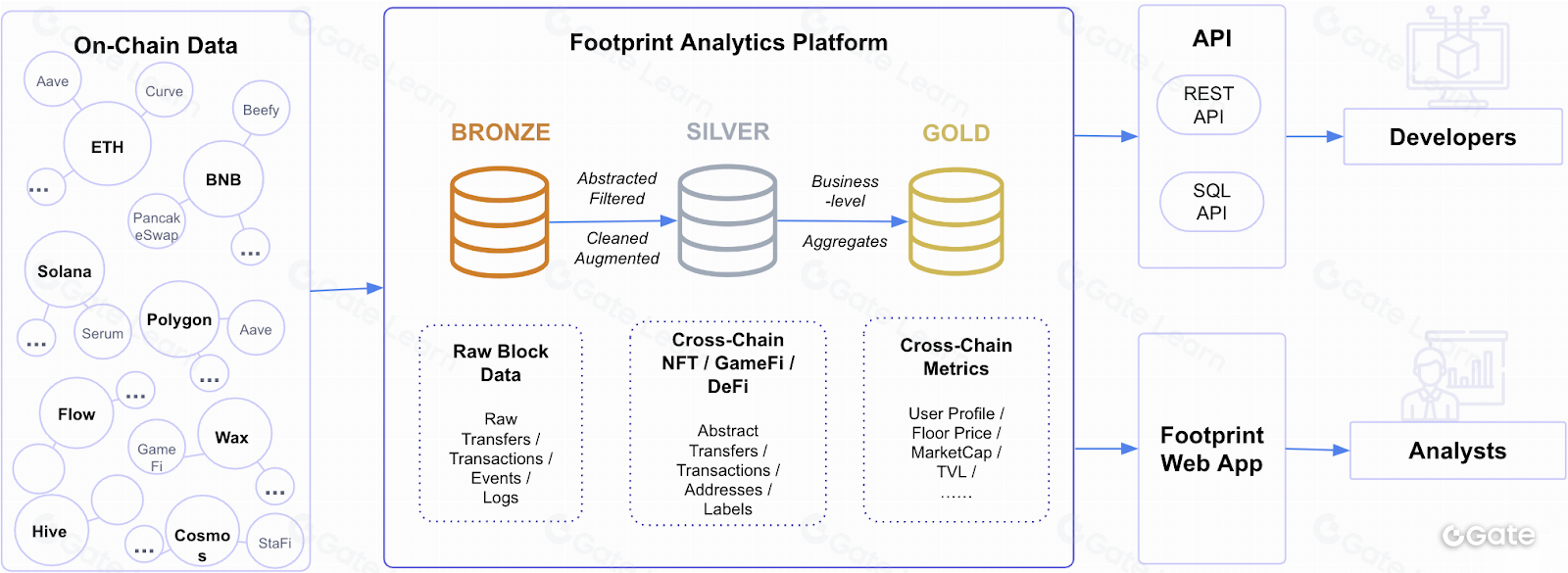
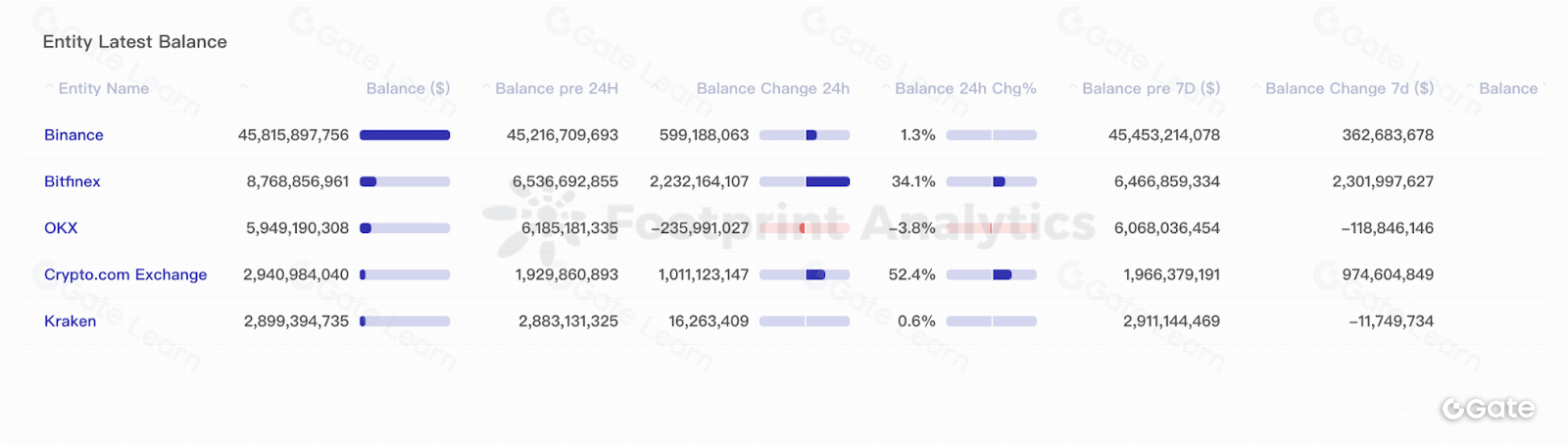
Existen varias alternativas para indexar datos on-chain, tanto centralizadas como descentralizadas. Las soluciones centralizadas se basan en que una entidad recopila y organiza los datos, mientras que las descentralizadas emplean una red distribuida de nodos. Ejemplos de soluciones de indexación son los exploradores de bloques, que permiten buscar y consultar la cadena de bloques, y los servicios de indexación, que ofrecen API y herramientas para que los desarrolladores accedan y analicen la información on-chain.
Es posible crear una solución analítica descentralizada con tecnología blockchain, pero la viabilidad depende de los requisitos y limitaciones del sistema. Un enfoque descentralizado puede reforzar la integridad y seguridad de los datos analizados, aunque también implica mayor complejidad en el diseño y desarrollo, y exige más recursos de cómputo y almacenamiento. En cuanto al rendimiento, un sistema descentralizado puede ser más lento que uno centralizado, aunque esto depende de factores como los algoritmos, las estructuras de datos y el diseño general del sistema. En última instancia, la elección entre uno u otro enfoque dependerá de las necesidades y objetivos concretos de la solución analítica.
¿Qué se puede hacer con los datos de blockchain?
Existen diversas metodologías aplicables al análisis de datos on-chain. Entre las más habituales destacan:
Análisis descriptivo
El análisis descriptivo resume y describe los datos, incluyendo cálculos de estadísticas básicas y generación de visualizaciones. Este enfoque resulta útil para obtener una visión general y detectar tendencias y patrones en la información.
Análisis exploratorio
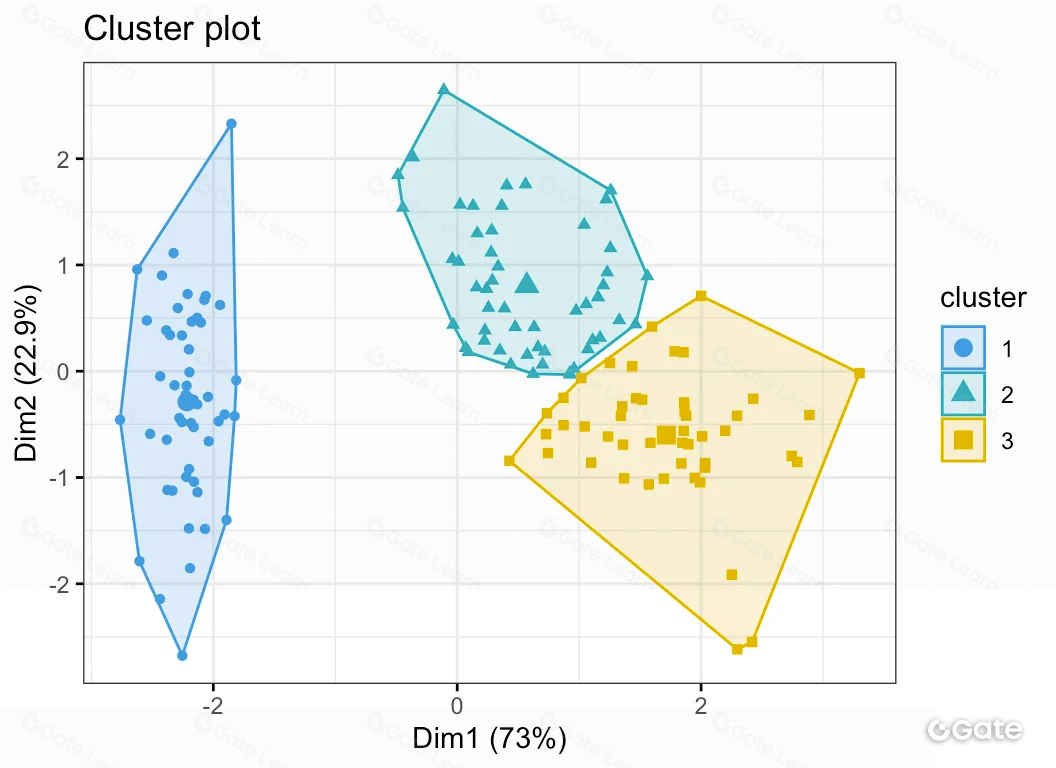
El análisis exploratorio profundiza en los datos, empleando técnicas como agrupamiento y reducción de dimensionalidad. Permite descubrir patrones y relaciones ocultas, y ayuda a formular hipótesis e ideas para estudios posteriores.
Análisis inferencial
El análisis inferencial aplica técnicas estadísticas para extraer conclusiones sobre una población a partir de una muestra de datos. Se emplean métodos para calcular media, mediana, moda y desviación estándar, así como herramientas para probar hipótesis y realizar regresiones. Este tipo de análisis permite hacer predicciones y generalizaciones, y descubrir tendencias y patrones menos evidentes.

Análisis predictivo
El análisis predictivo utiliza algoritmos de aprendizaje automático para anticipar eventos o resultados futuros a partir de los datos. Permite identificar tendencias y patrones, y realizar predicciones o recomendaciones. Suele incluir técnicas de agrupamiento, clasificación y regresión para detectar relaciones en la información.
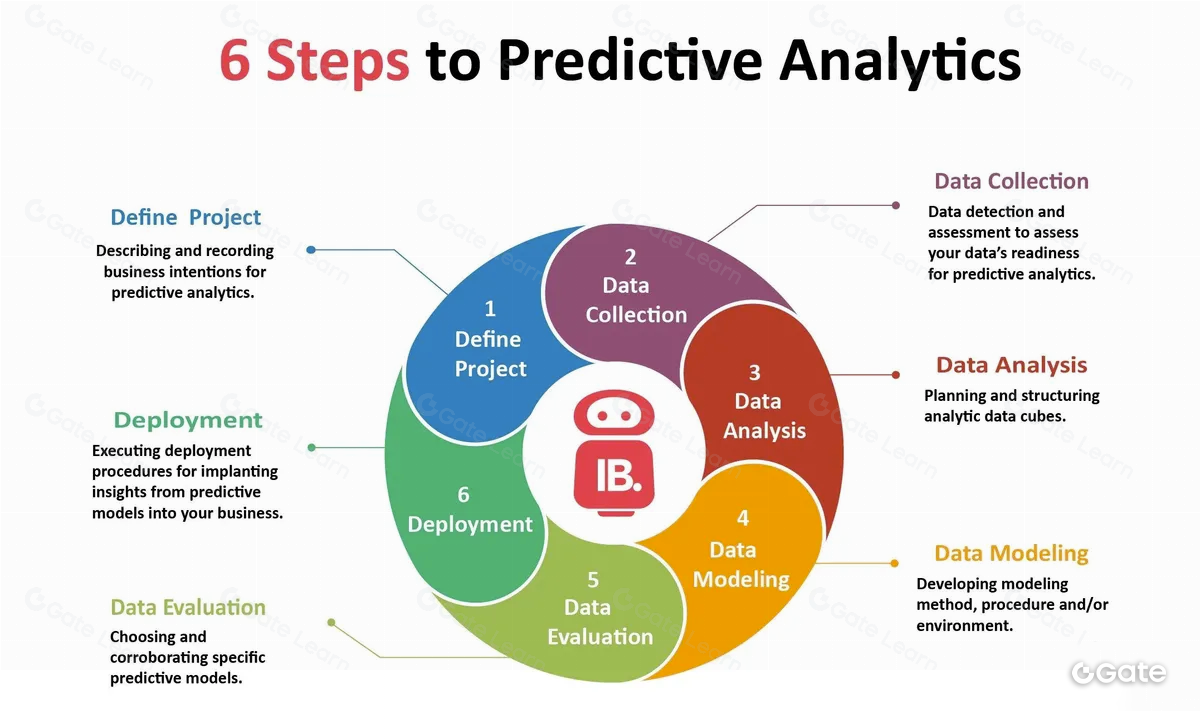
La metodología concreta para el análisis de datos on-chain depende de los objetivos y requisitos del estudio, así como de las características de los datos.
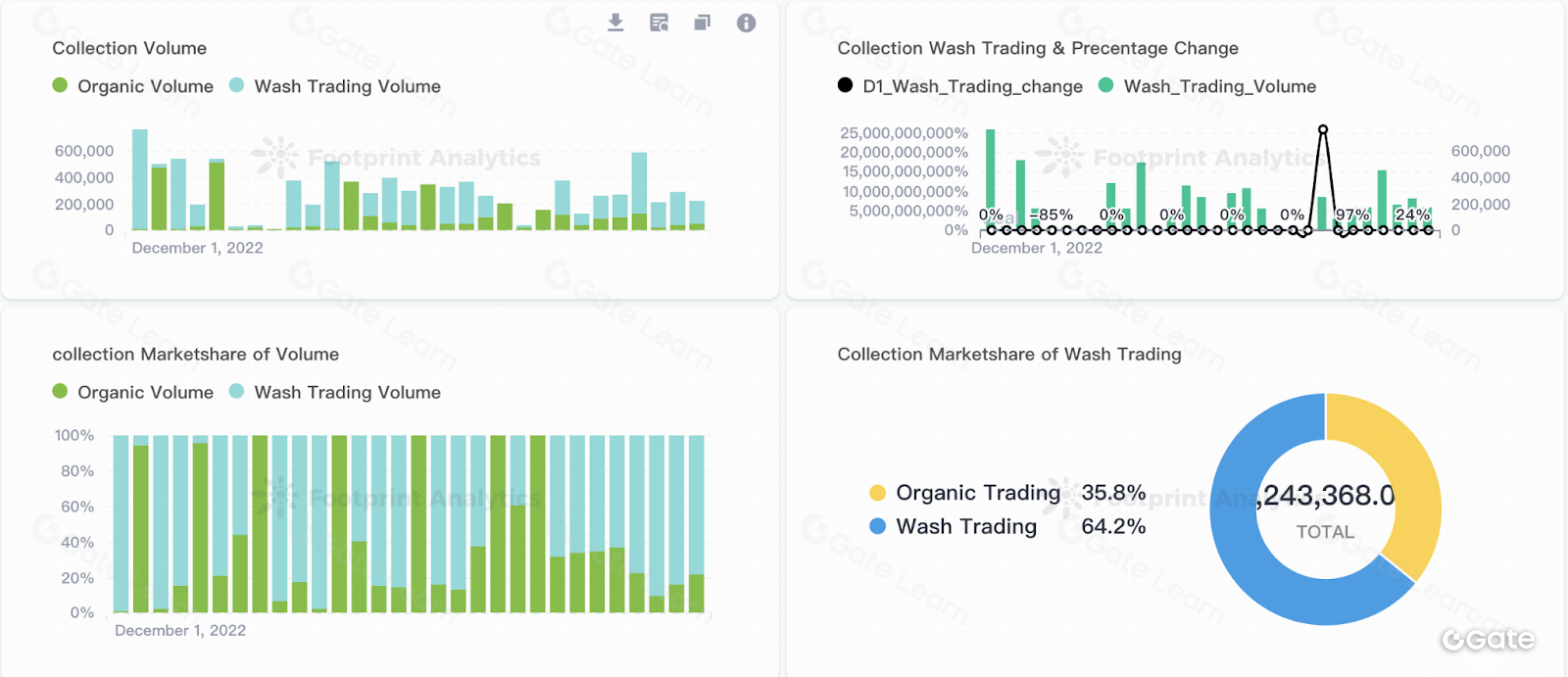
La visualización de datos es una herramienta habitual para representar información compleja de forma gráfica. Incluye gráficos, diagramas y mapas que facilitan la identificación de tendencias y patrones. Por ejemplo, un gráfico de líneas puede mostrar la evolución del precio de una criptomoneda, mientras que uno de barras permite comparar la capitalización de mercado de varios activos. También existen visualizaciones interactivas que permiten explorar los datos en profundidad y en tiempo real, lo que ayuda a detectar relaciones y patrones no evidentes en los datos brutos.
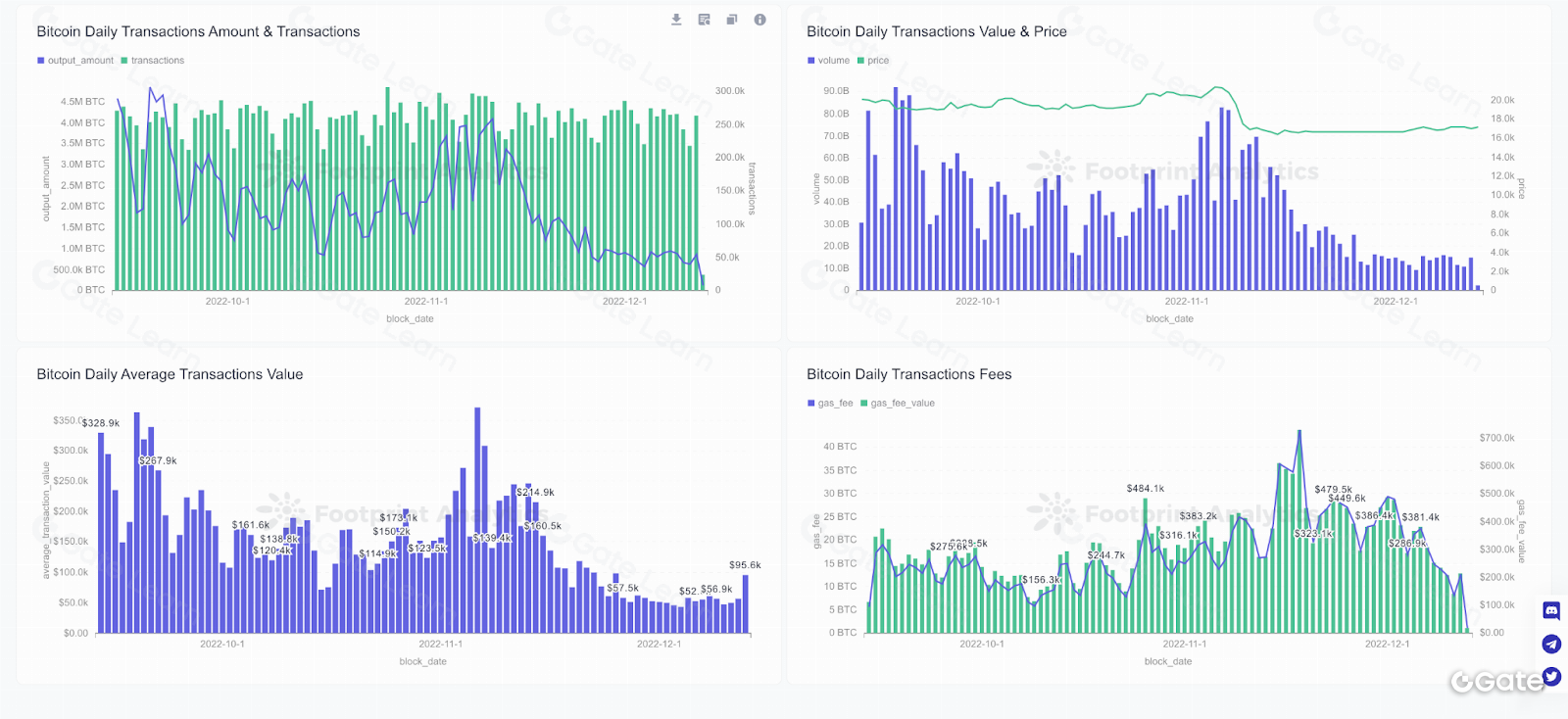
Puede surgir la cuestión de por qué utilizar herramientas de visualización si los exploradores de bloques ya ofrecen información exhaustiva. Aunque ambos recursos sirven para analizar datos on-chain, cumplen funciones diferentes y aportan tipos de información distintos.
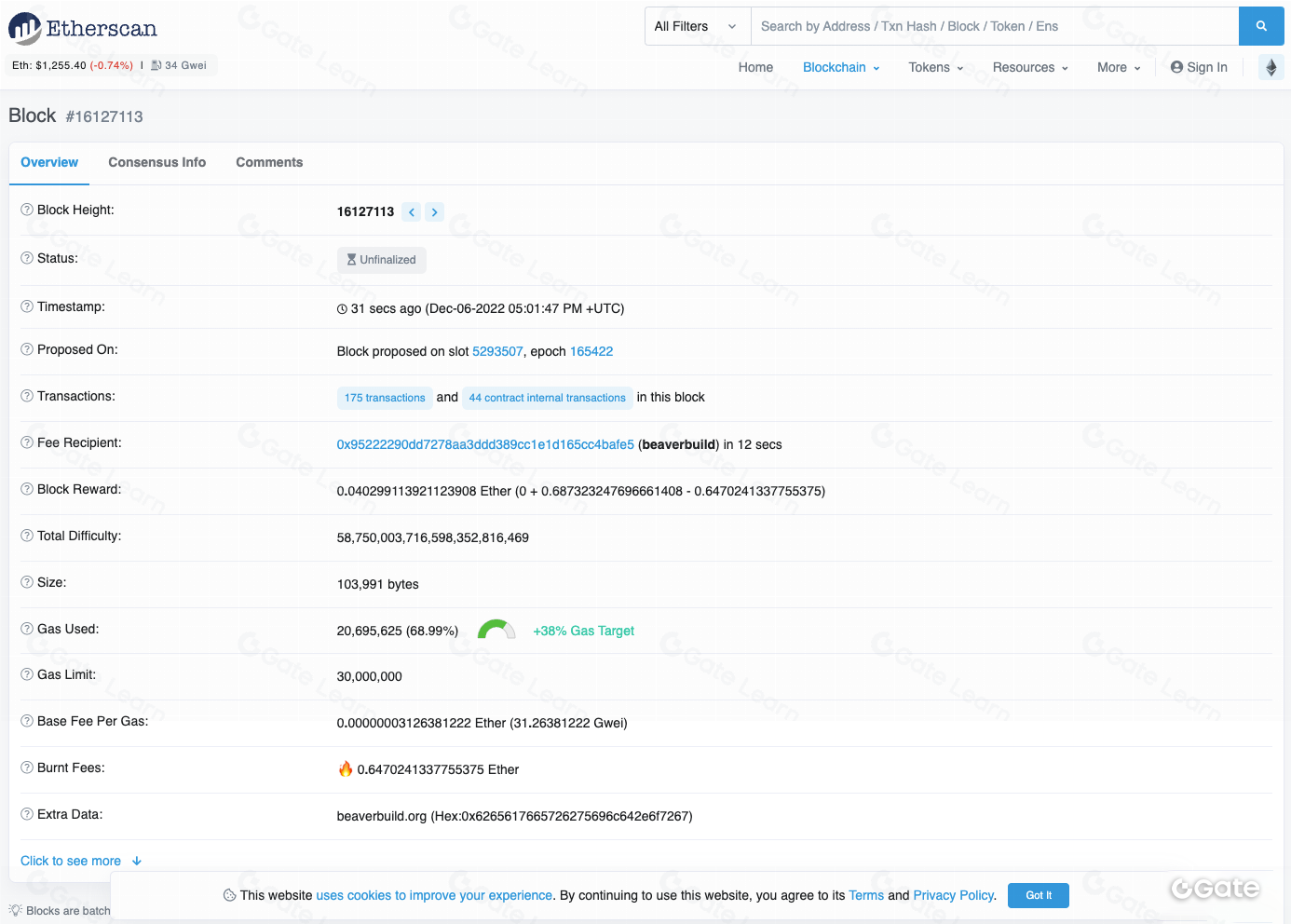
Las herramientas de visualización de datos permiten representar la información de forma gráfica, facilitando la comprensión y la detección de tendencias y patrones. Por el contrario, los exploradores de bloques son plataformas en línea para consultar información específica sobre bloques, transacciones y direcciones en la cadena de bloques. Ofrecen una interfaz sencilla para acceder y operar con los datos, pero no suelen incorporar funciones avanzadas de análisis o visualización. Por ello, la combinación de visualización de datos y exploradores de bloques permite obtener una visión más completa de la información en blockchain.
Web3; ciencia de datos; oportunidades laborales
Existen cuatro aspectos clave sobre el futuro de Web3 y la ciencia de datos:
Web3 generará más oportunidades laborales para científicos de datos y profesionales del sector. Las organizaciones que adopten Web3 demandarán expertos en análisis e interpretación de datos, así como en el desarrollo de productos y servicios basados en la información disponible, integrando inteligencia artificial y aprendizaje automático en sus procesos.
Web3 permitirá beneficios económicos tanto para usuarios como para científicos de datos. Las empresas podrán adquirir datos directamente de los usuarios (permitiendo que los propietarios vendan su información a quien deseen), combinar estos nuevos conjuntos de datos con los existentes para mejorar modelos de aprendizaje, y comercializar los nuevos conocimientos en el mercado abierto.
Los científicos de datos podrán aplicar inteligencia artificial para entender mejor las necesidades específicas de los clientes en Web3. Las empresas de datos podrán crear modelos de lenguaje que aporten “comprensión semántica”, ya que Web3 se centra en el usuario y los datos están vinculados a su interacción, desarrollando así soluciones personalizadas. Además, podrán extraer información de los datos brutos y convertirla en recomendaciones de producto más precisas, mejorando la experiencia del cliente según sus expectativas.
En la era Web3, los científicos de datos tendrán un impacto mucho mayor en la economía global. Serán las nuevas “neuronas” capaces de crear contenido y modelos de inteligencia artificial que colaboren con otros modelos para abordar problemas complejos y riesgos potenciales para empresas y organizaciones.







