Gate Ventures Research Insights: Perang Browser Ketiga: Pertarungan Masuk di Era Agen AI
TL;DR
Perang browser ketiga sedang berlangsung dengan tenang. Melihat kembali sejarah, dari Netscape dan Internet Explorer milik Microsoft di tahun 1990-an hingga Firefox sumber terbuka dan Chrome milik Google, perang browser selalu menjadi manifestasi terfokus dari kontrol platform dan pergantian paradigma teknologi. Chrome telah mengamankan posisinya yang dominan berkat kecepatan pembaruan yang cepat dan ekosistem terintegrasinya, sementara Google, melalui duopoli pencarian dan browsernya, telah membentuk siklus tertutup akses informasi.
Tapi hari ini, lanskap ini sedang goyang. Munculnya model bahasa besar (LLM) memungkinkan semakin banyak pengguna untuk menyelesaikan tugas tanpa mengklik halaman hasil pencarian, sementara klik halaman web tradisional sedang menurun. Sementara itu, desas-desus bahwa Apple berniat untuk mengganti mesin pencari default di Safari semakin mengancam basis keuntungan Alphabet (induk perusahaan Google), dan pasar mulai menunjukkan ketidaknyamanan tentang "ortodoksi pencarian."
Peramban itu sendiri juga menghadapi perubahan peran. Itu bukan hanya alat untuk menampilkan halaman web, tetapi juga wadah untuk berbagai kemampuan, termasuk input data, perilaku pengguna, dan identitas pribadi. Meskipun agen AI sangat kuat, mereka masih bergantung pada batas kepercayaan peramban dan kotak pasir fungsional untuk menyelesaikan interaksi halaman yang kompleks, mengakses data identitas lokal, dan mengontrol elemen halaman web. Peramban sedang berkembang dari antarmuka manusia menjadi platform panggilan sistem untuk agen.
Dalam artikel ini, kami menjelajahi apakah peramban masih diperlukan. Kami percaya bahwa apa yang benar-benar dapat mengganggu lanskap pasar peramban saat ini bukanlah "Chrome yang lebih baik," tetapi struktur interaksi baru: bukan hanya tampilan informasi, tetapi pemanggilan tugas. Peramban masa depan harus dirancang untuk agen AI—yang mampu tidak hanya membaca, tetapi juga menulis dan mengeksekusi. Proyek seperti Browser Use berusaha untuk menyemantisasi struktur halaman, mengubah antarmuka visual menjadi teks terstruktur yang dapat dipanggil oleh LLM, memetakan halaman ke perintah dan secara signifikan mengurangi biaya interaksi.
Proyek-proyek besar sudah mulai menguji perairan: Perplexity sedang membangun browser asli, Comet, yang menggantikan hasil pencarian tradisional dengan AI; Brave menggabungkan perlindungan privasi dengan penalaran lokal, menggunakan LLM untuk meningkatkan kemampuan pencarian dan pemblokiran; dan proyek-proyek berbasis kripto seperti Donut menargetkan titik masuk baru bagi AI untuk berinteraksi dengan aset on-chain. Satu sifat umum di antara proyek-proyek ini adalah upaya mereka untuk membentuk ulang lapisan input browser, daripada mempercantik lapisan outputnya.
Bagi para pengusaha, peluang terletak dalam segitiga input, struktur, dan akses agen. Sebagai antarmuka untuk dunia berbasis agen di masa depan, browser berarti bahwa siapa pun yang dapat menyediakan "kapabilitas" yang terstruktur, dapat dipanggil, dan dapat dipercaya akan menjadi komponen dari platform generasi berikutnya. Dari SEO hingga AEO (Optimisasi Mesin Agen), dari lalu lintas halaman hingga pemanggilan rantai tugas, bentuk produk dan pemikiran desain sedang dibentuk ulang. Perang browser ketiga sedang berlangsung di atas "input" daripada "tampilan." Kemenangan tidak lagi ditentukan oleh siapa yang menarik perhatian pengguna, tetapi oleh siapa yang mendapatkan kepercayaan agen dan mendapatkan akses.
Sejarah Singkat Pengembangan Browser
Pada awal 1990-an, sebelum internet menjadi bagian dari kehidupan sehari-hari, Netscape Navigator muncul di tengah-tengah, seperti perahu layar yang membuka pintu ke dunia digital bagi jutaan pengguna. Meskipun bukan peramban pertama, ini adalah yang pertama benar-benar menjangkau massa dan membentuk pengalaman internet. Untuk pertama kalinya, orang bisa menjelajahi web dengan begitu mudah melalui antarmuka grafis, seolah-olah seluruh dunia tiba-tiba menjadi dapat diakses.
Namun, kejayaan sering kali tidak bertahan lama. Microsoft dengan cepat menyadari pentingnya browser dan memutuskan untuk memaksa menggabungkan Internet Explorer ke dalam sistem operasi Windows, menjadikannya sebagai browser default. Strategi ini, yang benar-benar merupakan "pembunuh platform," secara langsung merusak dominasi pasar Netscape. Banyak pengguna tidak secara aktif memilih IE; sebaliknya, mereka hanya menerimanya sebagai default. Memanfaatkan kemampuan distribusi Windows, IE dengan cepat menjadi pemimpin industri, sementara Netscape jatuh ke dalam penurunan.

Di tengah kesulitan, para insinyur Netscape memilih jalur yang radikal dan idealis — mereka membuka kode sumber browser dan meminta bantuan komunitas sumber terbuka. Keputusan ini seperti "pengunduran diri Makedonia" di dunia teknologi, menandakan akhir dari era lama dan munculnya kekuatan baru. Kode tersebut kemudian menjadi dasar proyek browser Mozilla, yang pertama kali dinamakan Phoenix (melambangkan kelahiran kembali), tetapi setelah beberapa sengketa merek dagang, akhirnya dinamai ulang menjadi Firefox.
Firefox bukanlah sekadar salinan dari Netscape. Ia membuat terobosan dalam pengalaman pengguna, ekosistem plugin, dan keamanan. Kelahirannya menandai kemenangan semangat sumber terbuka dan menyuntikkan vitalitas baru ke seluruh industri. Beberapa menggambarkan Firefox sebagai "penerus spiritual" dari Netscape, mirip dengan bagaimana Kekaisaran Ottoman mewarisi kemegahan Byzantium yang memudar. Meskipun berlebihan, perbandingan ini memiliki makna.
Namun, sebelum Firefox dirilis secara resmi, Microsoft sudah meluncurkan enam versi Internet Explorer. Dengan memanfaatkan waktu peluncuran yang lebih awal dan strategi penggabungan sistem, Firefox ditempatkan dalam posisi mengejar dari awal, memastikan bahwa perlombaan ini tidak pernah menjadi kompetisi yang setara dari garis awal yang sama.
Pada saat yang sama, pemain awal lainnya secara diam-diam memasuki panggung. Pada tahun 1994, browser Opera lahir di Norwegia, awalnya hanya sebagai proyek percobaan. Namun, mulai dari versi 7.0 pada tahun 2003, ia memperkenalkan mesin Presto yang dikembangkan sendiri, pelopor dukungan untuk CSS, tata letak adaptif, kontrol suara, dan pengkodean Unicode. Meskipun basis penggunanya terbatas, ia secara konsisten memimpin industri secara teknologi, menjadi "favorit para geek."
Tahun yang sama, Apple meluncurkan browser Safari — sebuah titik balik yang berarti. Pada saat itu, Microsoft telah menginvestasikan $150 juta ke dalam Apple yang sedang berjuang untuk mempertahankan serangkaian kompetisi dan menghindari pengawasan antimonopoli. Meskipun mesin pencari bawaan Safari adalah Google sejak awal, keterikatan ini dengan Microsoft melambangkan hubungan yang kompleks dan halus di antara raksasa internet: kerjasama dan kompetisi, selalu saling terkait.
Pada tahun 2007, IE7 diluncurkan bersamaan dengan Windows Vista, tetapi respons pasar agak dingin. Di sisi lain, Firefox secara bertahap meningkatkan pangsa pasarnya menjadi sekitar 20%, berkat siklus pembaruan yang lebih cepat, mekanisme ekstensi yang lebih ramah pengguna, dan daya tarik alami bagi para pengembang. Dominasi IE mulai melonggar, dan angin sedang berubah.
Namun, Google mengambil pendekatan yang berbeda. Meskipun telah merencanakan perambannya sendiri sejak 2001, dibutuhkan waktu enam tahun untuk meyakinkan CEO Eric Schmidt agar menyetujui proyek tersebut. Chrome diluncurkan pada 2008, dibangun di atas proyek sumber terbuka Chromium dan mesin WebKit yang digunakan oleh Safari. Itu dicemooh sebagai peramban "berbobot" , tetapi dengan keahlian mendalam Google dalam periklanan dan pembangunan merek, ia naik dengan cepat.
Senjata utama Chrome bukanlah fitur-fitur yang dimilikinya, tetapi siklus pembaruan yang sering (setiap enam minggu) dan pengalaman lintas platform yang terpadu. Pada November 2011, Chrome melampaui Firefox untuk pertama kalinya, mencapai pangsa pasar 27%; enam bulan kemudian, Chrome mengalahkan IE, menyelesaikan transformasinya dari penantang menjadi pemimpin dominan.
Sementara itu, internet seluler China sedang membentuk ekosistemnya sendiri. UC Browser milik Alibaba meroket popularitasnya pada awal 2010-an, terutama di pasar negara berkembang seperti India, Indonesia, dan China. Dengan desainnya yang ringan dan fitur kompresi data yang menghemat bandwidth, ia berhasil menarik pengguna di perangkat kelas bawah. Pada tahun 2015, pangsa pasar browser selulernya secara global melebihi 17%, dan di India pernah mencapai setinggi 46%. Namun, kemenangan ini tidak bertahan lama. Ketika pemerintah India memperketat ulasan keamanan terhadap aplikasi-aplikasi China, UC Browser terpaksa keluar dari pasar-pasar kunci, secara bertahap kehilangan kejayaannya yang dulu.
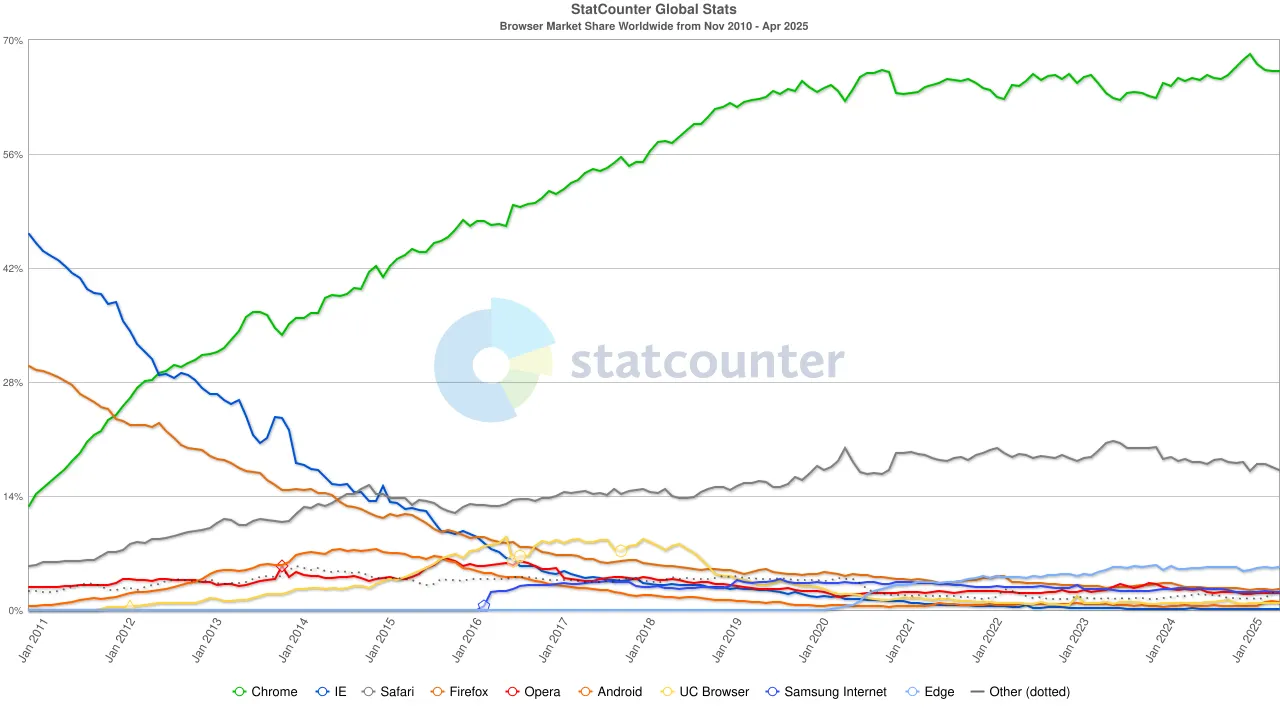
Pada tahun 2020-an, dominasi Chrome telah mapan, dengan pangsa pasar globalnya stabil di sekitar 65%. Secara mencolok, meskipun mesin pencari Google dan browser Chrome keduanya milik Alphabet, dari perspektif pasar, mereka mewakili dua hegemoni independen — yang pertama mengendalikan sekitar 90% lalu lintas pencarian global, dan yang terakhir berfungsi sebagai "jendela pertama" melalui mana sebagian besar pengguna mengakses internet.
Untuk mempertahankan struktur monopoli ganda ini, Google tidak segan-segan mengeluarkan biaya. Pada tahun 2022, Alphabet membayar Apple sekitar $20 miliar hanya untuk menjaga Google sebagai mesin pencari default di Safari. Para analis telah menunjukkan bahwa biaya ini mencapai sekitar 36% dari pendapatan iklan pencarian yang diperoleh Google dari lalu lintas Safari. Dengan kata lain, Google secara efektif membayar "biaya perlindungan" untuk mempertahankan keunggulannya.
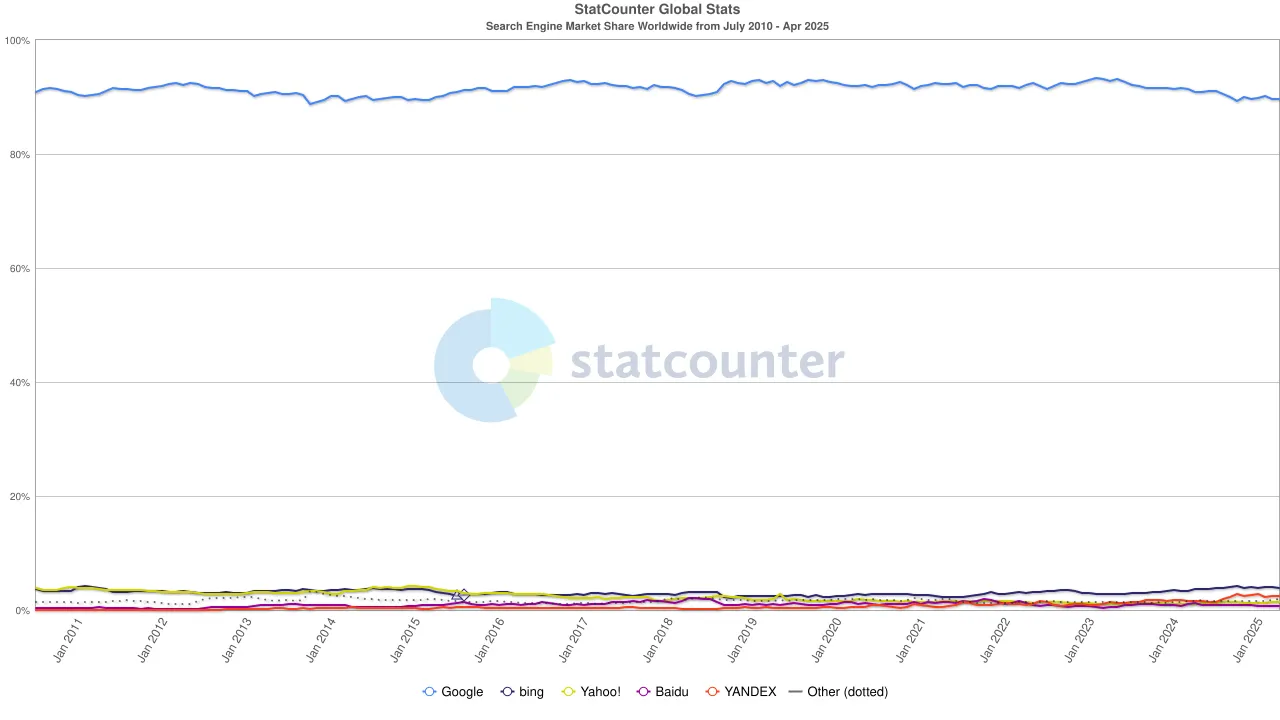
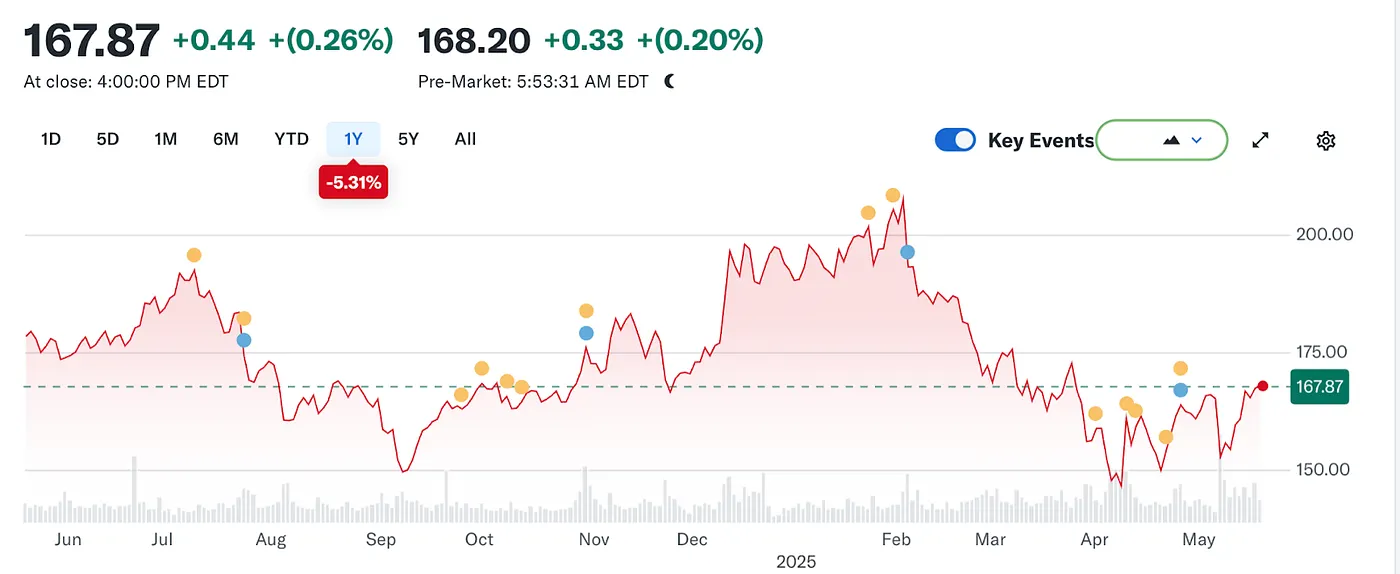
Namun, arus kembali berubah. Dengan munculnya model bahasa besar (LLMs), pencarian tradisional mulai merasakan dampaknya. Pada tahun 2024, pangsa pasar pencarian Google turun dari 93% menjadi 89%. Meskipun masih mendominasi, retakan mulai terlihat. Bahkan lebih mengganggu adalah desas-desus bahwa Apple mungkin meluncurkan mesin pencari bertenaga AI-nya sendiri. Jika pencarian default Safari beralih ke ekosistem milik Apple, itu tidak hanya akan membentuk kembali lanskap persaingan tetapi juga dapat mengguncang dasar keuntungan Alphabet. Pasar bereaksi dengan cepat: harga saham Alphabet turun dari $170 menjadi $140, mencerminkan tidak hanya kepanikan investor tetapi juga ketidaknyamanan yang dalam tentang arah masa depan era pencarian.
Dari Navigator ke Chrome, dari idealisme sumber terbuka ke komersialisasi yang didorong oleh iklan, dari browser ringan ke asisten pencarian AI, pertarungan browser selalu menjadi perang atas teknologi, platform, konten, dan kontrol. Medan perang terus bergeser, tetapi esensinya tidak pernah berubah: siapa pun yang mengendalikan Gate menentukan masa depan.
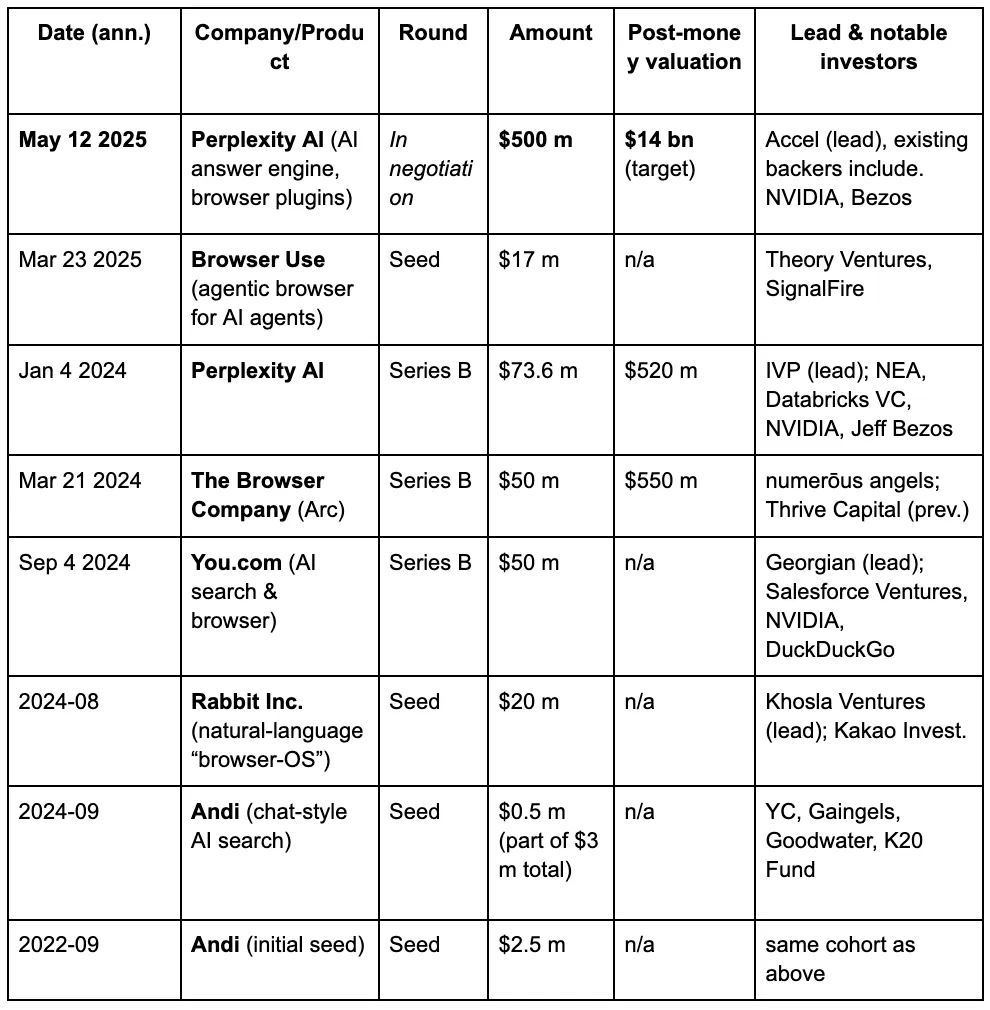
Di mata para pemodal ventura, perang peramban ketiga secara bertahap sedang terjadi, didorong oleh permintaan baru yang diajukan orang kepada mesin pencari di era LLM dan AI. Berikut adalah rincian pendanaan dari beberapa proyek terkenal di jalur peramban AI.
Arsitektur Usang dari Browser Modern
Ketika berbicara tentang arsitektur browser, struktur tradisional klasik ditunjukkan pada diagram di bawah ini:
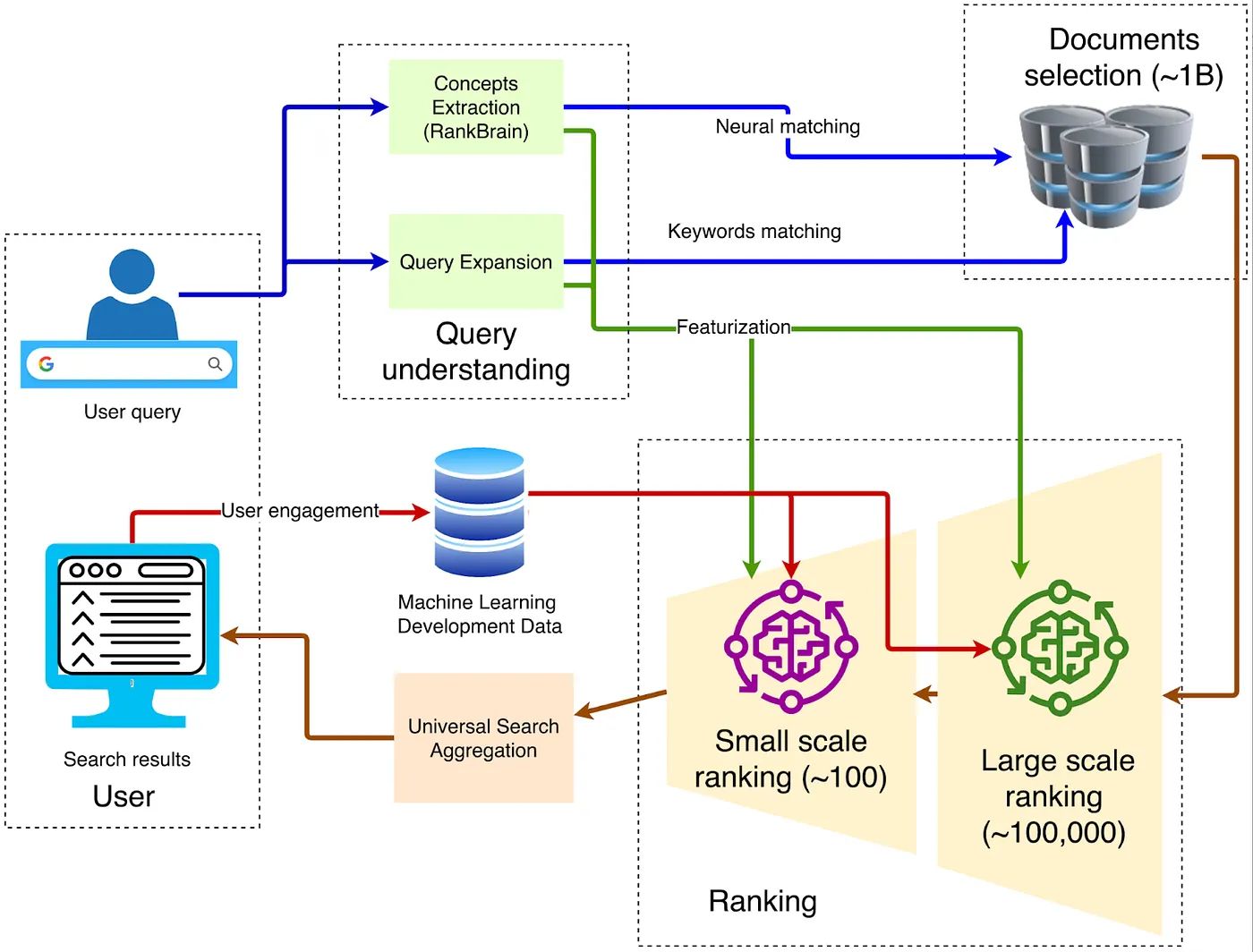
1. Klien — Masuk Front-End
Kueri dikirim melalui HTTPS ke Google Front End terdekat, di mana dekripsi TLS, pengambilan QoS, dan routing geografis dilakukan. Jika lalu lintas yang tidak normal terdeteksi (seperti serangan DDoS atau pengambilan data otomatis), pembatasan laju atau tantangan dapat diterapkan di lapisan ini.
2. Pemahaman Kuery
Antarmuka depan perlu memahami arti kata-kata yang diketik oleh pengguna. Ini melibatkan tiga langkah:
Koreksi ejaan neural, seperti mengubah “recpie” menjadi “recipe”.
Perluasan sinonim, misalnya memperluas "cara memperbaiki sepeda" untuk mencakup "memperbaiki sepeda".
Parsing niat, yang menentukan apakah kueri bersifat informasional, navigasional, atau transaksional, dan kemudian menetapkan permintaan vertikal yang sesuai.
3. Pengambilan Kandidat
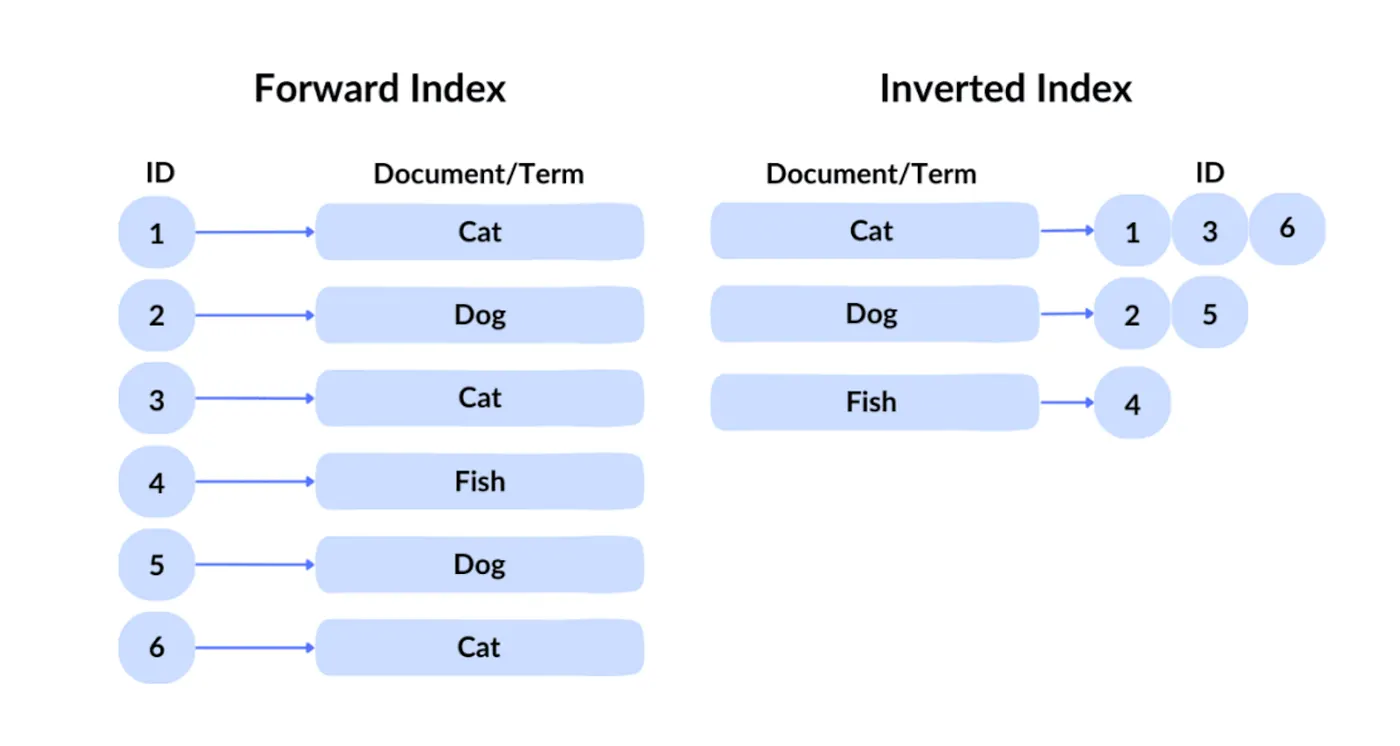
Teknologi kueri Google dikenal sebagai indeks terbalik. Dalam indeks maju, Anda mengambil file berdasarkan ID-nya. Namun karena pengguna tidak mungkin mengetahui pengidentifikasi konten yang diinginkan di antara ratusan miliar file, Google menggunakan indeks terbalik tradisional, yang melakukan kueri berdasarkan konten untuk mengidentifikasi file mana yang mengandung kata kunci yang sesuai.
Selanjutnya, Google menerapkan pengindeksan vektor untuk menangani pencarian semantik—yaitu, menemukan konten yang mirip dalam arti dengan kueri. Ini mengubah teks, gambar, dan konten lainnya menjadi vektor berdimensi tinggi (embedding), kemudian mencari berdasarkan kesamaan antara vektor tersebut. Sebagai contoh, jika pengguna mencari "cara membuat adonan pizza", mesin pencari dapat mengembalikan hasil yang terkait dengan "panduan persiapan adonan pizza", karena keduanya secara semantik mirip.
Melalui pengindeksan terbalik dan pengindeksan vektor, sekitar ratusan ribu halaman web disaring pada tahap penyaringan awal.
4. Peringkat Multi-Tahap
Sistem ini biasanya menggunakan ribuan fitur ringan seperti BM25, TF-IDF, dan skor kualitas halaman untuk menyaring ratusan ribu halaman kandidat menjadi sekitar 1.000, membentuk set kandidat awal. Sistem semacam itu secara kolektif disebut sebagai mesin rekomendasi. Mereka bergantung pada fitur masif yang dihasilkan dari berbagai entitas, termasuk perilaku pengguna, atribut halaman, niat kueri, dan sinyal kontekstual. Misalnya, Google menggabungkan riwayat pengguna, umpan balik dari pengguna lain, semantik halaman, dan makna kueri, sambil juga mempertimbangkan elemen kontekstual seperti waktu (waktu dalam sehari, hari dalam seminggu) dan peristiwa eksternal seperti berita terkini.
5. Pembelajaran Mendalam untuk Peringkat Utama
Pada tahap pengambilan awal, Google menggunakan teknologi seperti RankBrain dan Neural Matching untuk memahami semantik dari kueri dan menyaring hasil yang paling relevan dari koleksi dokumen yang masif.
RankBrain, yang diperkenalkan oleh Google pada tahun 2015, adalah sistem pembelajaran mesin yang dirancang untuk lebih memahami makna dari kueri pengguna, terutama kueri yang belum pernah dilihat sebelumnya. Ini mengubah kueri dan dokumen menjadi representasi vektor dan menghitung kesamaannya untuk menemukan hasil yang paling relevan. Misalnya, untuk kueri "cara membuat adonan pizza", bahkan jika tidak ada dokumen yang mengandung kecocokan kata kunci yang tepat, RankBrain dapat mengidentifikasi konten yang terkait dengan "dasar-dasar pizza" atau "persiapan adonan."
Neural Matching, yang diluncurkan pada tahun 2018, dirancang untuk lebih menangkap hubungan semantik antara kueri dan dokumen. Menggunakan model jaringan saraf, ia mengidentifikasi hubungan fuzzy antara kata-kata untuk lebih baik mencocokkan kueri dengan konten web. Misalnya, untuk kueri “mengapa kipas laptop saya begitu keras,” Neural Matching dapat memahami bahwa pengguna mungkin mencari informasi pemecahan masalah mengenai overheating, penumpukan debu, atau penggunaan CPU tinggi—bahkan jika istilah-istilah tersebut tidak muncul secara eksplisit dalam kueri.
6. Deep Re-Ranking: Penerapan BERT
Setelah penyaringan awal dokumen yang relevan, Google menerapkan BERT (Bidirectional Encoder Representations from Transformers) untuk memperbaiki peringkat dan memastikan bahwa hasil yang paling relevan muncul di atas. BERT adalah model bahasa yang sudah dilatih sebelumnya berdasarkan Transformer yang dapat memahami hubungan kontekstual kata-kata dalam kalimat.
Dalam pencarian, BERT digunakan untuk mengurutkan kembali dokumen yang diambil pada tahap awal. Ia secara bersama-sama mengkodekan kueri dan dokumen, menghitung skor relevansi mereka, dan kemudian mengurutkan kembali dokumen-dokumen tersebut. Sebagai contoh, untuk kueri "parkir di bukit tanpa tepi jalan", BERT dapat dengan benar menginterpretasikan arti "tanpa tepi jalan" dan mengembalikan hasil yang menyarankan pengemudi untuk memutar roda mereka menuju tepi jalan, daripada salah menginterpretasikannya sebagai situasi dengan tepi jalan.
Bagi insinyur SEO, ini berarti mereka harus mempelajari dengan cermat algoritma peringkat Google dan rekomendasi pembelajaran mesin untuk mengoptimalkan konten web dengan cara yang terarah, sehingga mendapatkan visibilitas yang lebih tinggi dalam peringkat pencarian.
Mengapa AI Akan Membentuk Ulang Browser
Pertama, kita perlu memperjelas: mengapa formulir browser masih perlu ada? Apakah ada paradigma ketiga di luar agen AI dan browser?
Kami percaya bahwa keberadaan mengimplikasikan ketidak tergantian. Mengapa kecerdasan buatan dapat menggunakan browser tetapi tidak dapat sepenuhnya menggantikan mereka? Karena browser adalah platform universal. Ini bukan hanya titik masuk untuk membaca data tetapi juga titik masuk umum untuk memasukkan data. Dunia tidak hanya dapat mengkonsumsi informasi—ia juga harus memproduksi data dan berinteraksi dengan situs web. Oleh karena itu, browser yang mengintegrasikan informasi pengguna yang dipersonalisasi akan terus ada secara luas.
Inilah poin kunci: sebagai Gerbang universal, browser tidak hanya untuk membaca data; pengguna sering kali perlu berinteraksi dengan data. Browser itu sendiri adalah repository yang sangat baik untuk menyimpan sidik jari pengguna. Perilaku pengguna yang lebih kompleks dan tindakan otomatis harus dilakukan melalui browser. Browser dapat menyimpan semua sidik jari perilaku pengguna, kredensial, dan informasi pribadi lainnya, memungkinkan pemanggilan tanpa kepercayaan selama otomatisasi. Interaksi dengan data dapat berkembang menjadi pola ini:
Pengguna → memanggil Agen AI → Browser.
Dengan kata lain, satu-satunya bagian yang dapat digantikan terletak pada tren alami dunia—menuju kecerdasan yang lebih besar, personalisasi, dan otomatisasi. Tentu saja, bagian ini dapat ditangani oleh agen AI. Namun, agen AI sendiri tidak cocok untuk membawa konten pengguna yang dipersonalisasi, karena mereka menghadapi berbagai tantangan terkait keamanan data dan kegunaan. Secara spesifik:
Browser adalah tempat penyimpanan untuk konten yang dipersonalisasi:
Sebagian besar model besar dihosting di cloud, dengan konteks sesi yang bergantung pada penyimpanan server, sehingga sulit untuk mengakses langsung kata sandi lokal, dompet, cookie, dan data sensitif lainnya.
Mengirim semua data penelusuran dan pembayaran ke model pihak ketiga memerlukan otorisasi pengguna yang diperbarui; DMA Uni Eropa dan undang-undang privasi tingkat negara bagian AS keduanya menuntut minimalisasi data di seluruh batas.
Mengisi otomatis kode otentikasi dua faktor, memanggil kamera, atau menggunakan GPU untuk inferensi WebGPU harus dilakukan dalam sandbox browser.
Konteks data sangat bergantung pada browser. Tab, cookie, IndexedDB, Cache Pekerja Layanan, kredensial passkey, dan data ekstensi semuanya disimpan di dalam browser.
Perubahan Mendalam dalam Bentuk Interaksi
Kembali ke topik dari awal, perilaku kita saat menggunakan browser umumnya dapat dibagi menjadi tiga kategori: membaca data, memasukkan data, dan berinteraksi dengan data. Model bahasa besar (LLM) telah secara mendalam mengubah efisiensi dan metode di mana kita membaca data. Praktik lama pengguna mencari halaman web melalui kata kunci sekarang tampak ketinggalan zaman dan tidak efisien.
Ketika datang ke evolusi perilaku pencarian pengguna—apakah tujuannya untuk mendapatkan jawaban ringkas atau mengklik melalui halaman web—banyak studi telah menganalisis pergeseran ini.
Dalam hal pola perilaku pengguna, sebuah studi tahun 2024 menunjukkan bahwa di AS, dari setiap 1.000 kueri Google, hanya 374 yang berakhir dengan klik halaman web terbuka. Dengan kata lain, hampir 63% adalah perilaku "nol klik". Pengguna telah terbiasa mendapatkan informasi seperti cuaca, kurs, dan kartu pengetahuan langsung dari halaman hasil pencarian.
Namun, apa yang benar-benar dapat memicu transformasi besar-besaran pada browser adalah lapisan interaksi data. Di masa lalu, orang berinteraksi dengan browser terutama dengan memasukkan kata kunci—tingkat maksimal pemahaman yang dapat ditangani oleh browser itu sendiri. Sekarang, pengguna semakin lebih suka menggunakan bahasa alami penuh untuk menggambarkan tugas kompleks, seperti:
"Temukan saya penerbangan langsung dari New York ke Los Angeles selama periode tertentu."
"Cari saya penerbangan dari New York ke Shanghai dan kemudian ke Los Angeles."
Bahkan untuk manusia, tugas-tugas seperti itu membutuhkan banyak waktu untuk mengunjungi beberapa situs web, mengumpulkan informasi, dan membandingkan hasil. Namun, Tugas Agentic ini secara bertahap diambil alih oleh agen AI.
Ini juga sejalan dengan trajektori sejarah: otomatisasi dan kecerdasan. Orang-orang ingin membebaskan tangan mereka, dan agen AI pasti akan tertanam dalam peramban. Peramban masa depan harus dirancang dengan penuh otomatisasi dalam pikiran, terutama mengingat:
Bagaimana cara menyeimbangkan pengalaman membaca untuk manusia dengan interpretabilitas mesin untuk agen AI.
Bagaimana memastikan satu halaman web melayani baik pengguna akhir maupun model agen.
Hanya dengan memenuhi kedua persyaratan desain ini, browser dapat benar-benar menjadi pengangkut yang stabil bagi agen AI untuk mengeksekusi tugas.
Selanjutnya, kita akan fokus pada lima proyek terkemuka—Browser Use, Arc (The Browser Company), Perplexity, Brave, dan Donut. Proyek-proyek ini mewakili arah masa depan evolusi browser AI, serta potensi mereka untuk integrasi asli dalam konteks Web3 dan kripto.
Dari perspektif psikologi pengguna, survei 2023 menunjukkan bahwa 44% responden menganggap hasil organik reguler lebih dapat dipercaya daripada cuplikan yang ditampilkan. Penelitian akademis juga menemukan bahwa dalam kasus kontroversi atau kurangnya kebenaran otoritatif tunggal, pengguna lebih memilih halaman hasil yang mengandung tautan dari berbagai sumber.
Dengan kata lain, sementara sebagian pengguna tidak sepenuhnya mempercayai ringkasan yang dihasilkan oleh AI, persentase perilaku yang signifikan telah bergeser ke "zero-click." Oleh karena itu, browser AI masih perlu mengeksplorasi paradigma interaksi yang tepat—khususnya di bidang pembacaan data. Karena masalah halusinasi dalam model besar belum sepenuhnya terpecahkan, banyak pengguna masih kesulitan untuk sepenuhnya mempercayai ringkasan konten yang dihasilkan secara otomatis. Dalam hal ini, penyematan model besar ke dalam browser tidak selalu memerlukan transformasi yang mengganggu. Sebaliknya, itu hanya memerlukan perbaikan bertahap dalam akurasi dan kontrol—proses yang sudah berlangsung.
Penggunaan Browser
Ini adalah inti logika di balik pendanaan besar yang diterima oleh Perplexity dan Penggunaan Browser. Secara khusus, Penggunaan Browser telah muncul sebagai peluang inovasi paling menjanjikan kedua pada awal 2025, dengan kepastian dan potensi pertumbuhan yang kuat.

Browser Use telah membangun lapisan semantik yang sejati, dengan fokus inti pada penciptaan arsitektur pengenalan semantik untuk generasi berikutnya dari browser.
Browser Use menginterpretasikan kembali "DOM = pohon node untuk dilihat manusia" menjadi "Semantic DOM = pohon instruksi untuk dibaca LLM." Ini memungkinkan agen untuk dengan tepat mengklik, mengisi, dan mengunggah tanpa bergantung pada "koordinat piksel." Alih-alih menggunakan OCR visual atau Selenium berbasis koordinat, pendekatan ini mengambil jalur "teks terstruktur → panggilan fungsi," membuat eksekusi lebih cepat, menghemat token, dan mengurangi kesalahan. TechCrunch menggambarkannya sebagai "lapisan perekat yang memungkinkan AI benar-benar memahami halaman web." Pada bulan Maret, Browser Use menutup putaran pendanaan awal sebesar $17 juta, bertaruh pada inovasi dasar ini.
Berikut cara kerjanya:
Setelah HTML dirender, ia membentuk pohon DOM standar. Browser kemudian menghasilkan pohon aksesibilitas, yang menyediakan label "peran" dan "status" yang lebih kaya untuk pembaca layar.
Setiap elemen interaktif (tombol, input, dll.) diubah menjadi potongan JSON dengan metadata seperti peran, visibilitas, koordinat, dan tindakan yang dapat dieksekusi.
Seluruh halaman diterjemahkan menjadi daftar datar dari simpul semantik, yang dapat dibaca LLM dalam satu prompt sistem.
LLM menghasilkan instruksi tingkat tinggi (misalnya, klik(node_id="btn-Checkout")), yang kemudian diputar ulang di browser nyata.
Blog resmi menggambarkan proses ini sebagai "mengubah antarmuka situs web menjadi teks terstruktur yang dapat diparse oleh LLM."
Selanjutnya, jika standar ini pernah diadopsi oleh W3C, itu dapat sangat menyelesaikan masalah input browser. Berikutnya, kita akan melihat surat terbuka dan studi kasus dari The Browser Company untuk menjelaskan lebih lanjut mengapa pendekatan mereka cacat.
Busur
Perusahaan Browser (perusahaan induk Arc) menyatakan dalam surat terbukanya bahwa browser Arc akan masuk ke mode pemeliharaan reguler, sementara tim akan mengalihkan fokusnya untuk mengembangkan DIA, sebuah browser yang sepenuhnya berorientasi pada AI. Dalam surat tersebut, mereka juga mengakui bahwa jalur implementasi spesifik untuk DIA belum ditentukan. Pada saat yang sama, tim menggarisbawahi beberapa prediksi tentang masa depan pasar browser.
Berdasarkan prediksi ini, kami lebih lanjut percaya bahwa jika lanskap browser saat ini benar-benar akan terganggu, kuncinya terletak pada mengubah sisi output dari interaksi.
Berikut adalah tiga prediksi tentang pasar browser masa depan yang dibagikan oleh tim Arc.
https://browsercompany.substack.com/p/letter-to-arc-members-2025
Pertama, tim Arc percaya bahwa halaman web tidak akan lagi menjadi antarmuka utama untuk interaksi. Memang, ini adalah klaim yang berani dan menantang, dan ini juga merupakan alasan utama mengapa kami tetap skeptis terhadap refleksi pendirinya. Menurut kami, perspektif ini secara signifikan meremehkan peran peramban, dan ini menyoroti masalah kunci yang diabaikan tim saat menjelajahi jalur peramban AI.
Model besar sangat unggul dalam menangkap niat—misalnya, memahami instruksi seperti “bantu saya memesan penerbangan.” Namun, mereka masih tidak memadai ketika datang ke kepadatan informasi. Ketika seorang pengguna membutuhkan sesuatu seperti dasbor, notebook gaya Bloomberg Terminal, atau kanvas visual seperti Figma, tidak ada yang dapat mengalahkan halaman web yang disetel dengan presisi piksel. Ergonomi setiap produk—grafik, fungsionalitas seret dan lepas, tombol pintas—bukanlah dekorasi yang dangkal, tetapi kemampuan penting yang mempercepat kognisi. Kemampuan ini tidak dapat direplikasi oleh interaksi percakapan sederhana. Mengambil Gate.com sebagai contoh: jika seorang pengguna ingin melakukan tindakan investasi, mengandalkan hanya pada percakapan AI jauh dari cukup, karena pengguna sangat bergantung pada input terstruktur, akurasi, dan presentasi informasi yang jelas.
Peta jalan tim Arc mengandung flaw fundamental: ia gagal untuk membedakan dengan jelas bahwa "interaksi" terdiri dari dua dimensi—input dan output. Di sisi input, pandangan mereka memiliki beberapa validitas dalam skenario tertentu, karena AI memang dapat meningkatkan efisiensi interaksi gaya perintah. Namun di sisi output, asumsi mereka jelas tidak seimbang, mengabaikan peran inti browser dalam penyajian informasi dan pengalaman yang dipersonalisasi. Misalnya, Reddit memiliki tata letak dan arsitektur informasi yang unik, sementara AAVE memiliki antarmuka dan struktur yang sangat berbeda. Sebagai platform yang secara bersamaan menyimpan data yang sangat pribadi dan menyajikan berbagai antarmuka produk, browser memiliki substitutabilitas yang terbatas di sisi input, sementara kompleksitas dan sifatnya yang tidak terstandarisasi di sisi output membuatnya semakin sulit untuk mengganggu.
Sebaliknya, browser AI saat ini sebagian besar berkonsentrasi pada lapisan "ringkasan output": merangkum halaman, mengekstrak informasi, menghasilkan kesimpulan. Ini tidak cukup untuk menantang secara fundamental browser atau sistem pencarian arus utama seperti Google—ini hanya menggerogoti pangsa pasar untuk ringkasan pencarian.
Oleh karena itu, satu-satunya teknologi yang benar-benar dapat mengguncang pangsa pasar Chrome sebesar 66% tidak ditakdirkan untuk menjadi "Chrome berikutnya." Untuk mencapai gangguan yang nyata, model rendering dari browser harus direstrukturisasi secara fundamental untuk beradaptasi dengan kebutuhan interaksi era AI Agent, terutama dalam hal desain arsitektur sisi input. Itulah mengapa kami menemukan jalur teknis yang diambil oleh Browser Use jauh lebih meyakinkan—itu berfokus pada perubahan struktural di mekanisme dasar browser. Setelah sistem mana pun mencapai desain "atom" atau "modular", pemrograman dan komposabilitas yang dihasilkan darinya membuka potensi gangguan. Inilah arah yang sedang dikejar oleh Browser Use hari ini.
Singkatnya, operasi agen AI masih sangat bergantung pada keberadaan browser. Browser bukan hanya menjadi repositori utama untuk data pribadi yang kompleks, tetapi juga antarmuka rendering universal untuk berbagai aplikasi, dan dengan demikian akan terus berfungsi sebagai Gateway inti untuk interaksi di masa depan. Ketika agen AI semakin terbenam dalam browser untuk menyelesaikan tugas-tugas tetap, mereka akan berinteraksi dengan data pengguna dan aplikasi tertentu terutama melalui sisi input. Untuk alasan ini, model rendering saat ini dari browser harus diinnovasi untuk mencapai kompatibilitas dan adaptabilitas maksimum dengan agen AI—akhirnya memungkinkan mereka untuk menangkap aplikasi dengan lebih efektif.
Kebingungan
Perplexity adalah mesin pencari AI yang terkenal dengan sistem rekomendasinya. Valuasi terbarunya telah melonjak menjadi $14 miliar, hampir meningkat lima kali lipat dari $3 miliar pada bulan Juni 2024. Saat ini, ia menangani lebih dari 400 juta kueri pencarian per bulan. Pada bulan September 2024 saja, ia memproses sekitar 250 juta kueri, menandai peningkatan delapan kali lipat dalam volume pencarian pengguna dibandingkan tahun lalu, dengan lebih dari 30 juta pengguna aktif bulanan.
Fitur utamanya adalah kemampuan untuk merangkum halaman secara real-time, memberikan keuntungan yang kuat dalam mengakses informasi terkini. Awal tahun ini, Perplexity mulai membangun browser asli mereka sendiri, Comet. Perusahaan menggambarkan Comet sebagai browser yang tidak hanya "menampilkan" halaman web tetapi juga "berpikir" tentangnya. Secara resmi, mereka mengklaim bahwa itu akan menyematkan mesin jawaban Perplexity jauh di dalam browser itu sendiri, mengikuti pendekatan "mesin utuh" yang mengingatkan pada filosofi Steve Jobs: mengintegrasikan tugas AI secara mendalam di tingkat dasar browser, daripada hanya membangun plugin sidebar.
Dengan jawaban singkat yang didukung oleh kutipan, Comet bertujuan untuk menggantikan "sepuluh tautan biru" tradisional dan bersaing langsung dengan Chrome.
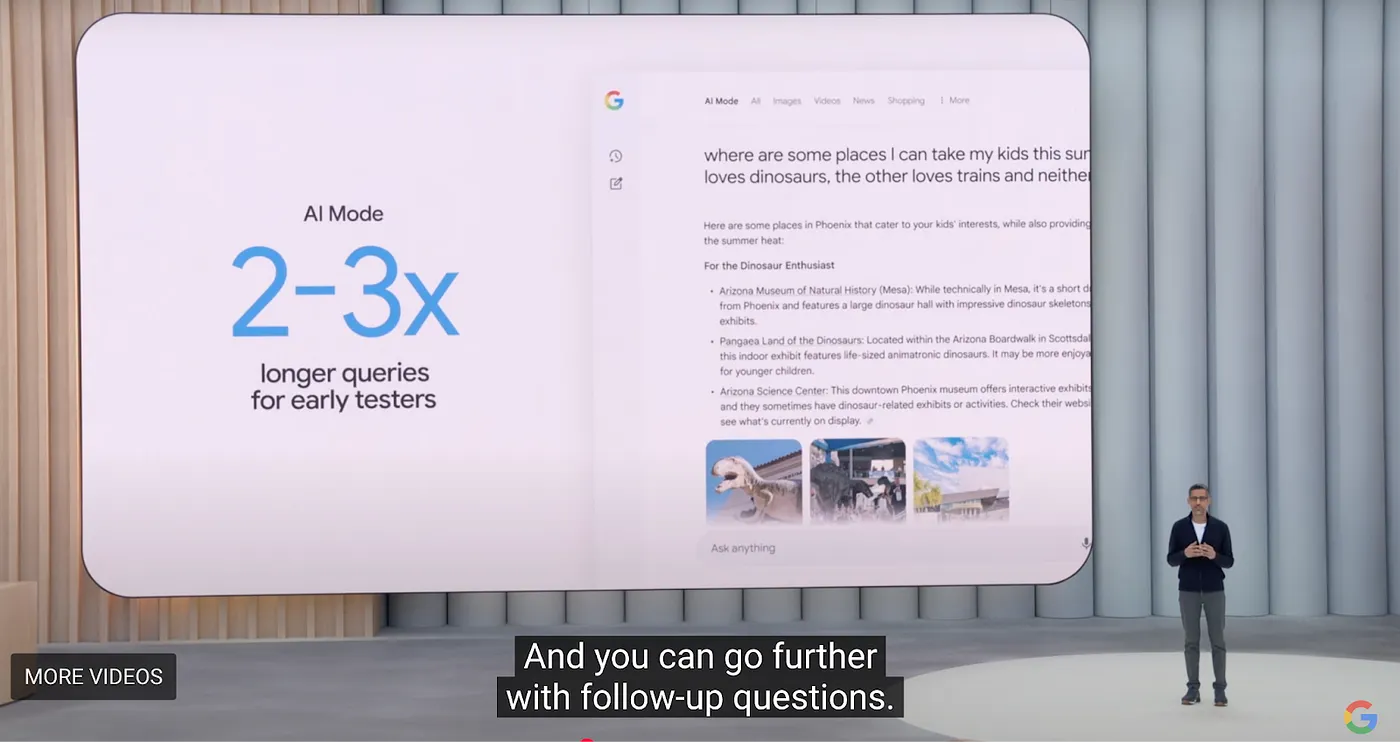
Namun, Perplexity masih perlu memecahkan dua masalah inti: biaya pencarian yang tinggi dan margin keuntungan yang rendah dari pengguna marginal. Meskipun Perplexity saat ini memimpin di bidang pencarian AI, Google mengumumkan pada konferensi I/O 2025-nya sebuah perombakan cerdas skala besar terhadap produk inti mereka. Untuk browser, Google meluncurkan pengalaman tab browser baru yang disebut AI Model, yang mengintegrasikan Overview, Deep Research, dan kemampuan Agentic di masa depan. Seluruh inisiatif ini disebut sebagai "Project Mariner."
Google secara aktif memajukan transformasi AI-nya, yang berarti bahwa imitasi fitur yang dangkal—seperti Overview, Deep Research, atau Agentics—hampir tidak akan menjadi ancaman nyata. Apa yang benar-benar dapat membangun tatanan baru di tengah kekacauan adalah membangun kembali arsitektur browser dari dasar, secara mendalam mengintegrasikan model bahasa besar (LLM) ke dalam kernel browser, dan secara fundamental mengubah metode interaksi.
Berani
Brave adalah salah satu browser paling awal dan paling sukses di industri kripto. Dibangun di atas arsitektur Chromium, ia kompatibel dengan ekstensi dari Google Store. Brave menarik pengguna dengan model yang berbasis pada privasi dan mendapatkan token melalui browsing. Jalur pengembangannya menunjukkan potensi pertumbuhan tertentu. Namun, dari perspektif produk, meskipun privasi memang penting, permintaan tetap terkonsentrasi di dalam kelompok pengguna tertentu. Bagi publik yang lebih luas, kesadaran akan privasi belum menjadi faktor pengambilan keputusan yang mainstream. Oleh karena itu, berusaha mengandalkan fitur ini saja untuk mengganggu raksasa yang sudah ada tidak mungkin berhasil.
Hingga saat ini, Brave telah mencapai 82,7 juta pengguna aktif bulanan (MAU) dan 35,6 juta pengguna aktif harian (DAU), memegang pangsa pasar sekitar 1%–1,5%. Basis penggunanya menunjukkan pertumbuhan yang stabil: dari 6 juta pada Juli 2019, menjadi 25 juta pada Januari 2021, menjadi 57 juta pada Januari 2023, dan pada Februari 2025, telah melampaui 82 juta. Tingkat pertumbuhan tahunan gabungannya tetap di angka dua digit.
Brave menangani sekitar 1,34 miliar kueri pencarian per bulan, yang merupakan sekitar 0,3% dari volume Google.
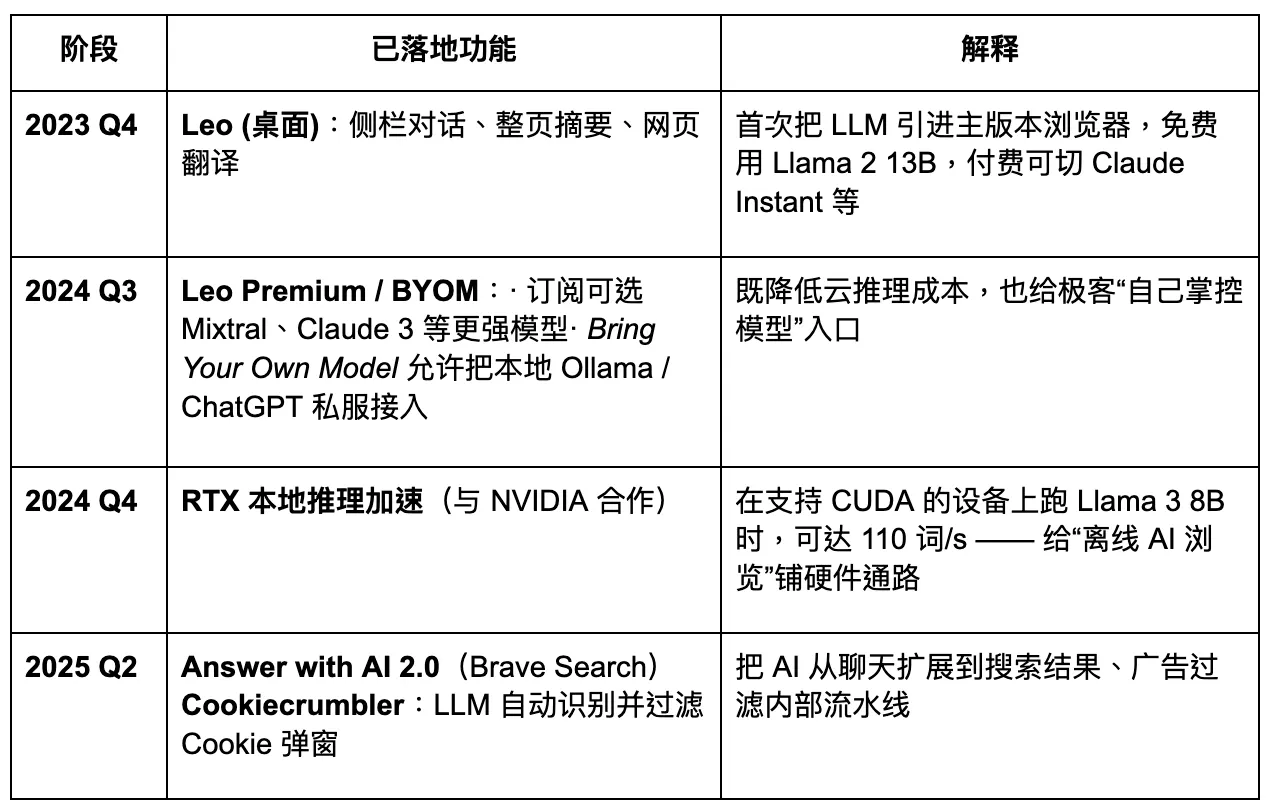
Brave berencana untuk meningkatkan menjadi browser AI yang mengutamakan privasi. Namun, aksesnya yang terbatas terhadap data pengguna mengurangi tingkat kustomisasi yang mungkin untuk model-model besar, yang pada gilirannya menghambat iterasi produk yang cepat dan tepat. Di era Browser Agentic yang akan datang, Brave mungkin mempertahankan pangsa pasar yang stabil di antara kelompok pengguna yang fokus pada privasi tertentu, tetapi akan sulit baginya untuk menjadi pemain dominan. Asisten AI-nya, Leo, berfungsi lebih seperti peningkatan plugin—menawarkan beberapa kemampuan ringkasan konten, tetapi kurang memiliki strategi yang jelas untuk pergeseran penuh menuju agen AI. Inovasi dalam interaksi tetap tidak memadai.
Donut
Baru-baru ini, industri kripto juga telah membuat kemajuan di bidang Browser Agens. Proyek tahap awal Donut mengumpulkan $7 juta dalam putaran pra-bibit, dipimpin oleh Hongshan (Sequoia China), HackVC, dan Bitkraft Ventures. Proyek ini masih dalam tahap konseptual awal, dengan visi mencapai "Penemuan – Pengambilan keputusan – dan Eksekusi asli-kripto" sebagai kemampuan terintegrasi.
Arah inti adalah menggabungkan jalur eksekusi otomatisasi yang berbasis kripto. Seperti yang diprediksi oleh a16z, agen mungkin akan menggantikan mesin pencari sebagai Gerbang lalu lintas utama di masa depan. Pengusaha tidak akan lagi bersaing di sekitar algoritma peringkat Google, tetapi sebaliknya berjuang untuk lalu lintas dan konversi yang berasal dari eksekusi agen. Industri telah menyebut tren ini sebagai "AEO" (Optimisasi Mesin Jawaban / Agen), atau bahkan lebih jauh, "ATF" (Pemenuhan Tugas Agen)—di mana tujuannya bukan lagi untuk mengoptimalkan peringkat pencarian, tetapi untuk secara langsung melayani model cerdas yang dapat menyelesaikan tugas untuk pengguna, seperti memesan, memesan tiket, atau menulis surat.
Untuk Pengusaha
Pertama, harus diakui: browser itu sendiri tetap menjadi "Gateway" terbesar yang tidak terbangun kembali di dunia internet. Dengan sekitar 2,1 miliar pengguna desktop dan lebih dari 4,3 miliar pengguna mobile secara global, ia berfungsi sebagai pembawa umum untuk input data, perilaku interaktif, dan penyimpanan sidik jari yang dipersonalisasi. Alasan ketahanannya bukan karena inersia, tetapi karena sifat ganda yang melekat pada browser: ia adalah titik masuk untuk membaca data dan titik keluar untuk tindakan penulisan.
Oleh karena itu, bagi para pengusaha, potensi disruptif yang sebenarnya tidak terletak pada pengoptimalan lapisan "output halaman". Bahkan jika seseorang dapat mereplikasi fungsi overview AI seperti Google dalam tab baru, itu masih akan menjadi iterasi di lapisan plugin, bukan perubahan paradigma yang mendasar. Terobosan nyata terletak pada sisi "input"—bagaimana membuat agen AI secara aktif memanggil produk Anda untuk menyelesaikan tugas tertentu. Ini akan menentukan apakah suatu produk dapat terintegrasi ke dalam ekosistem agen, menangkap lalu lintas, dan berbagi dalam distribusi nilai.
Di era pencarian, kompetisinya adalah tentang klik; di era agen, ini tentang panggilan.
Jika Anda seorang pengusaha, Anda harus membayangkan ulang produk Anda sebagai komponen API—sesuatu yang dapat dipahami tidak hanya oleh agen cerdas tetapi juga dapat diinvokasi. Ini mengharuskan Anda untuk mempertimbangkan tiga dimensi sejak awal desain produk:
1. Standarisasi Struktur Antarmuka: Apakah produk Anda dapat dipanggil?
Kemampuan agen untuk memanggil produk tergantung pada apakah struktur informasinya dapat distandarisasi dan diabstraksikan ke dalam skema yang jelas. Misalnya, dapatkah tindakan kunci seperti pendaftaran pengguna, penempatan pesanan, atau pengiriman komentar dijelaskan melalui struktur DOM semantik atau pemetaan JSON? Apakah sistem menyediakan mesin status sehingga agen dapat mereplikasi alur kerja pengguna dengan dapat diandalkan? Dapatkah interaksi pengguna di halaman diskripkan? Apakah produk menawarkan webhook atau titik akhir API yang stabil?
Inilah sebabnya mengapa Browser Use berhasil mengumpulkan dana—ia mengubah browser dari renderer HTML datar menjadi pohon semantik yang dapat dipanggil oleh LLM. Bagi para pengusaha, mengadopsi filosofi desain serupa dalam produk web berarti mempersiapkan diri untuk adaptasi terstruktur di era agen AI.
2. Identitas dan Akses: Dapatkah Anda membantu agen “melintasi batas kepercayaan”?
Agar agen dapat menyelesaikan transaksi atau memanggil fungsi pembayaran dan aset, mereka memerlukan perantara yang tepercaya—bisakah Anda menjadi perantara itu? Browser secara alami memiliki kemampuan untuk membaca penyimpanan lokal, mengakses dompet, menangani CAPTCHA, dan mengintegrasikan otentikasi dua faktor. Ini membuat mereka lebih cocok daripada model yang dihosting di cloud untuk mengeksekusi tugas. Ini terutama benar di Web3, di mana antarmuka interaksi aset tidak distandarisasi. Tanpa "identitas" atau "kemampuan tanda tangan," agen tidak dapat melanjutkan.
Bagi para pengusaha crypto, ini membuka ruang putih yang sangat imajinatif: “MCP (Multi Capability Platform) dari dunia blockchain.” Ini bisa berupa lapisan perintah universal (yang memungkinkan agen untuk memanggil Dapps), seperangkat antarmuka kontrak yang terstandarisasi, atau bahkan dompet lokal ringan + pusat identitas.
3. Memikirkan Kembali Mekanisme Lalu Lintas: Masa depan bukanlah SEO, tetapi AEO / ATF.
Dulu, Anda harus menang melawan algoritma Google; sekarang Anda perlu terintegrasi dalam rantai tugas agen AI. Ini berarti produk Anda harus memiliki granularitas tugas yang jelas: bukan "halaman," tetapi serangkaian unit kemampuan yang dapat dipanggil. Ini juga berarti mulai mengoptimalkan untuk Optimisasi Mesin Agen (AEO) atau beradaptasi dengan Pemenuhan Tugas Agen (ATF). Misalnya, dapatkah proses pendaftaran disederhanakan menjadi langkah-langkah terstruktur? Dapatkah harga diambil melalui API? Apakah inventaris dapat diakses secara real-time?
Anda mungkin bahkan perlu beradaptasi dengan sintaksis pemanggilan yang berbeda di berbagai kerangka kerja LLM—karena OpenAI dan Claude, misalnya, memiliki preferensi yang berbeda untuk panggilan fungsi dan penggunaan alat. Chrome adalah terminal dari dunia lama, bukan Gerbang menuju yang baru. Proyek-proyek masa depan tidak akan membangun kembali browser, tetapi lebih pada membuat browser melayani agen—membangun jembatan untuk generasi baru "aliran instruksi."
Apa yang perlu Anda bangun adalah "bahasa antarmuka" melalui mana agen memanggil dunia Anda.
Apa yang Anda butuhkan untuk mendapatkan adalah tempat dalam rantai kepercayaan sistem cerdas.
Apa yang perlu Anda bangun adalah "kastil API" dalam paradigma pencarian berikutnya.
Jika Web2 menangkap perhatian pengguna melalui UI, maka era Web3 + AI Agent akan menangkap niat eksekusi agen melalui rantai panggilan.
Penafian
Konten ini tidak merupakan tawaran, permohonan, atau rekomendasi. Anda harus selalu mencari saran profesional independen sebelum membuat keputusan investasi. Harap dicatat bahwa Gate dan/atau Gate Ventures dapat membatasi atau melarang beberapa atau semua layanan di wilayah yang dibatasi. Harap baca perjanjian pengguna yang berlaku untuk informasi lebih lanjut.
Tentang Gate Ventures
Gate Ventures adalah divisi modal ventura dari Gate, yang berfokus pada investasi dalam infrastruktur terdesentralisasi, ekosistem, dan aplikasi—teknologi yang akan membentuk kembali dunia di era Web 3.0. Gate Ventures bekerja sama dengan pemimpin industri global untuk memberdayakan tim dan startup dengan pemikiran inovatif dan kemampuan untuk mendefinisikan ulang cara masyarakat dan keuangan berinteraksi.
Website: https://www.gate.com/ventures
Bagikan
Konten

