O mercado de criptomoedas é conhecido pela sua extrema volatilidade, apresentando oportunidades significativas para investidores, mas também riscos consideráveis. A previsão precisa de preços é crucial para decisões de investimento informadas. No entanto, os métodos tradicionais de análise financeira frequentemente lutam para lidar com a complexidade e mudanças rápidas do mercado de criptomoedas. Nos últimos anos, o avanço da aprendizagem automática tem fornecido ferramentas poderosas para previsão de séries temporais financeiras, especialmente na previsão de preços de criptomoedas.
Os algoritmos de aprendizagem automática podem aprender grandes volumes de dados de preços históricos e outras informações relevantes, identificando padrões difíceis de detectar para os humanos. Entre vários modelos de aprendizagem automática, as Redes Neurais Recorrentes (RNNs) e suas variantes, como as Long Short-Term Memory (LSTM) e os modelos Transformer, têm ganho ampla atenção pela sua excepcional capacidade de lidar com dados sequenciais, mostrando um potencial crescente na previsão de preços de criptomoedas. Este artigo oferece uma análise detalhada de modelos baseados em aprendizagem automática para previsão de preços de criptomoedas, focando na comparação das aplicações de LSTM e Transformer. Explora também como a integração de diversas fontes de dados pode melhorar o desempenho do modelo e examina o impacto de eventos cisne negro na estabilidade do modelo.
Aplicação de Aprendizado de Máquina na Previsão de Preços de Criptomoedas
A ideia fundamental da aprendizagem automática é permitir que os computadores aprendam a partir de grandes conjuntos de dados e façam previsões com base nos padrões aprendidos. Esses algoritmos analisam alterações de preços históricos, volumes de negociação e outros dados relacionados para descobrir tendências e padrões ocultos. As abordagens comuns incluem análise de regressão, árvores de decisão e redes neurais, todas amplamente utilizadas na construção de modelos de previsão de preços de criptomoedas.
A maioria dos estudos baseava-se em métodos estatísticos tradicionais nas fases iniciais da previsão de preços de criptomoedas. Por exemplo, por volta de 2017, antes da disseminação generalizada do deep learning, muitos estudos utilizaram modelos ARIMA para prever as tendências de preços de criptomoedas como o Bitcoin. Um estudo representativo realizado por Dong, Li e Gong (2017) utilizou o modelo ARIMA para analisar a volatilidade do Bitcoin, demonstrando a estabilidade e confiabilidade dos modelos tradicionais na captura de tendências lineares.
Com avanços tecnológicos, os métodos de aprendizado profundo começaram a mostrar resultados inovadores na previsão de séries temporais financeiras até 2020. Em particular, as redes de Memória de Longo Prazo de Curto Prazo (LSTM) ganharam popularidade devido à sua capacidade de capturar dependências de longo prazo em dados de séries temporais. A estudopor Patel et al. (2019) provaram as vantagens do LSTM na previsão dos preços do Bitcoin, assinalando um avanço significativo na época.
Até 2023, os modelos Transformer - com seus mecanismos exclusivos de autoatenção capazes de capturar relacionamentos em toda a sequência de dados de uma só vez - foram cada vez mais aplicados à previsão de séries temporais financeiras. Por exemplo, o 2023 de Zhao et al. estudo“Atenção! Transformer com Sentimento sobre Previsão de Preço de Criptomoedas” integrou com sucesso modelos de Transformer com dados de sentimento das redes sociais, melhorando significativamente a precisão das previsões de tendência de preços de criptomoedas, marcando um marco importante no campo.

Marcos na Tecnologia de Previsão de Criptomoedas (Fonte: Gate Learn Criador John)
Entre os muitos modelos de aprendizado de máquina, os modelos de aprendizado profundo — particularmente as Redes Neurais Recorrentes (RNNs) e suas versões avançadas, LSTM e Transformer — demonstraram vantagens significativas no tratamento de dados de séries temporais. Os RNNs são projetados especificamente para processar dados sequenciais passando informações de etapas anteriores para etapas posteriores, capturando efetivamente dependências em pontos de tempo. No entanto, os RNNs tradicionais lutam com o problema do "gradiente de desaparecimento" ao lidar com sequências longas, fazendo com que informações mais antigas, mas importantes, sejam gradualmente perdidas. Para resolver isso, o LSTM introduz células de memória e mecanismos de regulação em cima de RNNs, permitindo a retenção de longo prazo de informações-chave e uma melhor modelagem de dependências de longo prazo. Uma vez que os dados financeiros, como os preços históricos das criptomoedas, exibem fortes características temporais, os modelos LSTM são particularmente adequados para prever tais tendências.
Por outro lado, os modelos Transformer foram originalmente desenvolvidos para processamento de linguagem. O mecanismo de autoatenção deles permite que o modelo considere as relações em toda a sequência de dados simultaneamente, em vez de processá-las passo a passo. Essa arquitetura confere aos Transformers um potencial imenso na previsão de dados financeiros com dependências temporais complexas.
Comparação de Modelos de Previsão
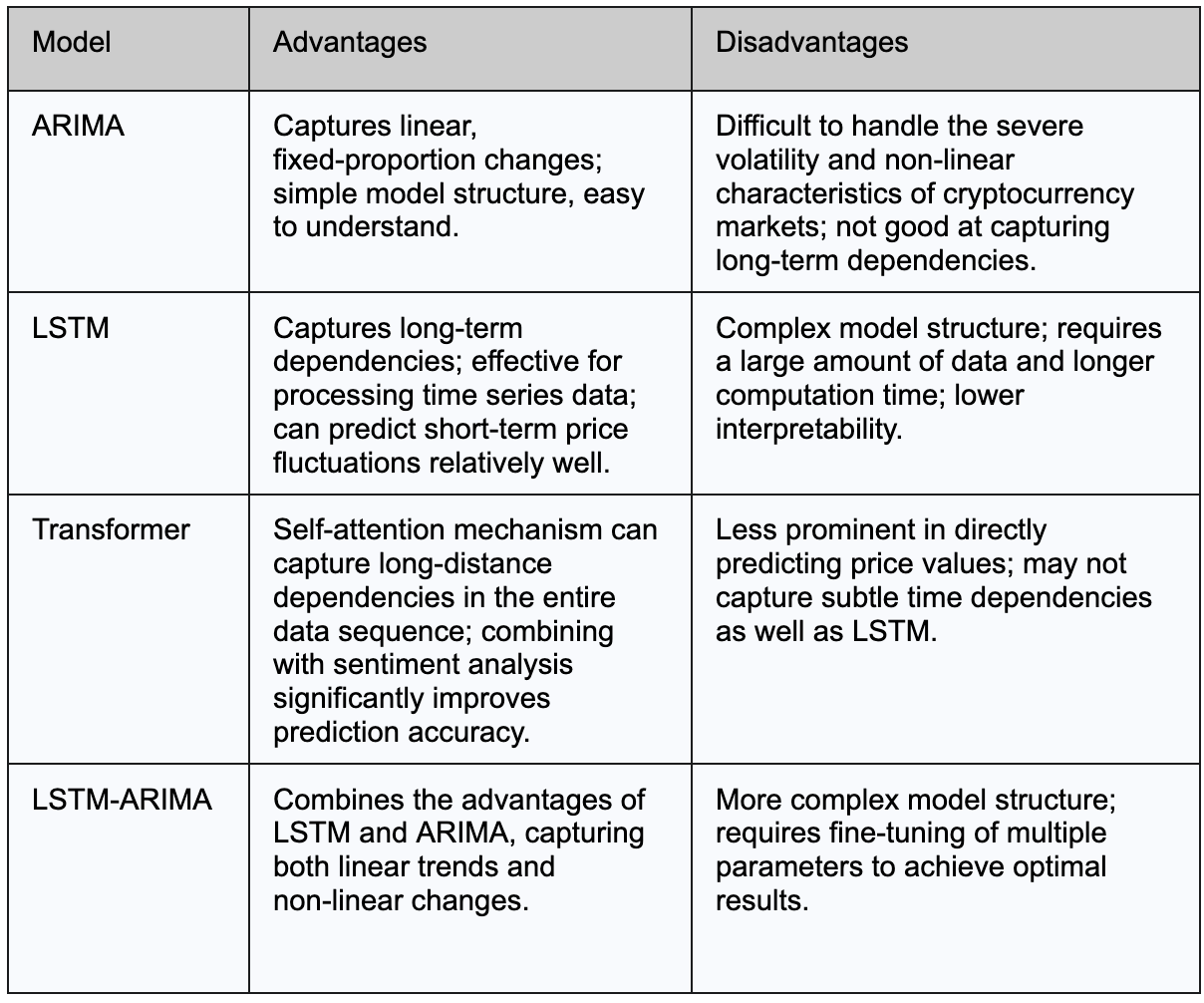
Modelos tradicionais como ARIMA são frequentemente usados como referências ao lado de modelos de aprendizado profundo na previsão de preços de criptomoeda. O ARIMA é projetado para capturar tendências lineares e mudanças proporcionais consistentes nos dados, apresentando bom desempenho em muitas tarefas de previsão. No entanto, devido à natureza altamente volátil e complexa dos preços das criptomoedas, as suposições lineares do ARIMA muitas vezes não são suficientes.Estudos têm mostradoque os modelos de aprendizagem profunda geralmente fornecem previsões mais precisas em mercados não lineares e altamente flutuantes.
Entre as abordagens de aprendizado profundo, a pesquisa que compara os modelos LSTM e Transformers na previsão dos preços do Bitcoin descobriu que o LSTM tem um desempenho melhor ao capturar os detalhes mais finos das mudanças de preço a curto prazo. Essa vantagem se deve principalmente ao mecanismo de memória do LSTM, que permite modelar as dependências de curto prazo de forma mais eficaz e estável. Embora o LSTM possa superar na precisão da previsão a curto prazo, os modelos Transformers permanecem altamente competitivos. Quando aprimorados com dados contextuais adicionais, como análise de sentimento do Twitter, os Transformers podem oferecer uma compreensão de mercado mais ampla, melhorando significativamente o desempenho preditivo.
Além disso, alguns estudos exploraram modelos híbridos que combinam aprendizado profundo com abordagens estatísticas tradicionais, como LSTM-ARIMA. Esses modelos híbridos têm como objetivo capturar padrões lineares e não lineares nos dados, melhorando ainda mais a precisão das previsões e a robustez do modelo.
A tabela abaixo resume as principais vantagens e desvantagens dos modelos ARIMA, LSTM e Transformer na previsão de preços do Bitcoin:
Melhorando a Precisão da Previsão com Engenharia de Recursos
Ao prever os preços das criptomoedas, não nos baseamos apenas em dados de preços históricos - também incorporamos informações adicionais valiosas para ajudar os modelos a fazer previsões mais precisas. Este processo é chamado de engenharia de características, que envolve organizar e construir dados "características" que melhoram o desempenho da previsão.
Fontes de Dados de Recursos Comuns
Dados on-chain
Dados on-chainrefere-se a todas as informações transacionais e de atividade registadas na blockchain, incluindo o volume de negociação, número de endereços ativos, dificuldade de mineração, e taxa de hash. Essas métricas refletem diretamente a dinâmica de oferta e demanda do mercado e a atividade geral da rede, tornando-as altamente valiosas para previsões de preços. Por exemplo, um aumento significativo no volume de negociação pode sinalizar uma mudança no sentimento de mercado, enquanto um aumento nos endereços ativos poderia indicar uma adoção mais ampla, potencialmente impulsionando os preços para cima.
Tais dados são tipicamente acessados via APIs de explorador de blockchain ou provedores de dados especializados como Glassnode e Coin Metrics. Pode utilizar a biblioteca requests do Python para chamar APIs ou descarregar diretamente ficheiros CSV para análise.
Indicadores de Sentimento nas Redes Sociais
Plataformas como Santimentanalisar o conteúdo de texto de fontes como Twitter e Reddit para avaliar o sentimento dos participantes do mercado em relação às criptomoedas. Eles aplicam ainda técnicas de processamento de linguagem natural (NLP), como análise de sentimento, para converter este texto em indicadores de sentimento. Estes indicadores refletem as opiniões e expectativas dos investidores, oferecendo uma contribuição valiosa para a previsão de preços. Por exemplo, um sentimento predominantemente positivo nas redes sociais pode atrair mais investidores e impulsionar os preços, enquanto um sentimento negativo poderia desencadear pressão de venda. Plataformas como a Santiment também fornecem APIs e ferramentas para ajudar os desenvolvedores a integrar dados de sentimento em modelos de previsão.Estudos têm mostradoque a incorporação da análise de sentimento das redes sociais pode melhorar significativamente o desempenho dos modelos de previsão de preços de criptomoedas, especialmente para previsões de curto prazo.

O Santiment pode fornecer dados de sentimento sobre as opiniões dos participantes do mercado em relação às criptomoedas (Fonte: Santiment)
Fatores Macroeconômicos
Indicadores macroeconómicos como as taxas de juro, as taxas de inflação, o crescimento do PIB e as taxas de desemprego também influenciam os preços das criptomoedas. Estes fatores afetam as preferências de risco dos investidores e os fluxos de capital. Por exemplo, os investidores podem transferir fundos de ativos de alto risco como as criptomoedas para alternativas mais seguras quando as taxas de juro sobem, levando a quedas de preço. Por outro lado, quando a inflação aumenta, os investidores podem procurar ativos que preservem valor—o Bitcoin é por vezes visto como um hedge contra a inflação.
Os dados sobre as taxas de juros, inflação, crescimento do PIB e desemprego podem normalmente ser obtidos dos governos nacionais ou de organizações internacionais como o Banco Mundial ou o FMI. Esses conjuntos de dados geralmente estão disponíveis em formato CSV ou JSON e podem ser acessados através de bibliotecas Python como pandas_datareader.
A tabela seguinte resume os dados comuns utilizados na cadeia, os indicadores de sentimento nas redes sociais e os fatores macroeconómicos, bem como a forma como podem influenciar os preços das criptomoedas:

Como Integrar Dados de Recurso
Geralmente, este processo pode ser dividido em algumas etapas:
1. Limpeza e Padronização de Dados
Os dados de diferentes fontes podem ter formatos diferentes, alguns podem estar em falta ou inconsistentes. Nesses casos, a limpeza de dados é necessária. Por exemplo, converter todos os dados para o mesmo formato de data, preencher dados em falta e padronizar os dados para que possam ser mais facilmente comparados.
2. Integração de Dados
Após a limpeza, os dados de diferentes fontes são fundidos com base nas datas, criando um conjunto de dados completo que mostra as condições de mercado para cada dia.
3. Construção da Entrada do Modelo
Finalmente, estes dados integrados são transformados num formato que o modelo pode compreender. Por exemplo, se quisermos que o modelo preveja o preço de hoje com base em dados dos últimos 60 dias, organizaríamos os dados desses 60 dias numa lista (ou matriz) para servir de entrada para o modelo. O modelo aprende as relações dentro destes dados para prever tendências futuras de preços.
O modelo pode aproveitar informações mais abrangentes para melhorar a precisão da previsão através deste processo de engenharia de características.
Exemplos de Projetos de Código Aberto
Existem muitos projetos populares de previsão de preço de criptomoeda de código aberto no GitHub. Esses projetos usam vários modelos de aprendizado de máquina e aprendizado profundo para prever as tendências de preço de diferentes criptomoedas.
A maioria dos projetos utiliza frameworks populares de deep learning como TensorFlowouKerasconstruir e treinar modelos, aprendendo padrões a partir de dados de preços históricos e prever movimentos de preços futuros. O processo inteiro normalmente inclui pré-processamento de dados (como organizar e padronizar dados de preços históricos), construção de modelos (definir camadas LSTM e outras camadas necessárias), treinamento de modelos (ajustar parâmetros do modelo através de um grande conjunto de dados para reduzir erros de previsão) e avaliação final e visualização dos resultados de previsão.
Um projeto desses que usa técnicas de aprendizado profundo para prever os preços das criptomoedas é Dat-TG/Predição de Preço de Criptomoeda.
O principal objetivo deste projeto é usar um modelo LSTM para prever os preços de fechamento do Bitcoin (BTC-USD), Ethereum (ETH-USD) e Cardano (ADA-USD) para ajudar os investidores a entender melhor as tendências do mercado. Os utilizadores podem clonar o repositório do GitHub e executar a aplicação localmente, seguindo as instruções fornecidas.

Resultados da previsão BTC para o Projeto (Fonte: Painel de Preços de Criptomoedas)
A estrutura do código deste projeto é clara, com scripts separados e Jupyter Notebooks para obtenção de dados, treino do modelo e execução da aplicação web. Com base na estrutura do diretório do projeto e interna código, o processo de construção do modelo de previsão é o seguinte:
- Os dados são descarregados do Yahoo Finance e depois limpos e organizados utilizando o Pandas, incluindo tarefas como padronizar o formato da data e preencher valores em falta.
- Os dados processados geram uma “janela deslizante” — utilizando os últimos 60 dias de dados para prever o preço para o 61º dia.
- Os dados são então introduzidos num modelo construído utilizando LSTM (Memória de Longo Prazo e Curto Prazo). LSTM lembra eficazmente as alterações de preço a curto e longo prazo, tornando-o adequado para prever tendências de preço.
- Os resultados da previsão e os preços reais são exibidos usando vários gráficos através do Plotly Dash, com um menu suspenso que permite aos utilizadores selecionar diferentes criptomoedas ou indicadores técnicos, atualizando os gráficos em tempo real.

Estrutura do Diretório do Projeto (Fonte: Previsão de Preço de Criptomoeda)
Análise de Risco do Modelo de Previsão de Preços de Criptomoedas
Impacto dos Eventos Cisne Negro na Estabilidade do Modelo
Um evento Cisne Negro é extremamente raro e imprevisível, com um impacto massivo. Estes eventos estão tipicamente para além das expectativas dos modelos preditivos convencionais e podem causar perturbações significativas no mercado. Um exemplo típico é o Luna crashem maio de 2022.
Luna, como projeto de stablecoin algorítmica, contava com um mecanismo complexo com sua criptomoeda irmã LUNA para estabilidade. No início de maio de 2022, a stablecoin UST da Luna começou a se desvincular do dólar americano, levando a vendas de pânico por parte dos investidores. Devido às falhas do mecanismo algorítmico, o colapso da UST fez com que o fornecimento de LUNA aumentasse drasticamente. Em poucos dias, o preço da LUNA despencou de quase $80 para quase zero, evitando centenas de bilhões de dólares em valor de mercado. Isso causou perdas significativas para os investidores envolvidos e suscitou preocupações generalizadas sobre os riscos sistêmicos no mercado de criptomoedas.
Assim, quando ocorre um evento Cisne Negro, os modelos tradicionais de aprendizado de máquina treinados em dados históricos provavelmente nunca terão encontrado situações tão extremas, levando os modelos a falhar na realização de previsões precisas ou até mesmo a produzir resultados enganosos.
Riscos Intrínsecos do Modelo
Para além dos eventos Black Swan, também devemos estar cientes de alguns riscos inerentes ao próprio modelo, que podem gradualmente acumular-se e afetar a precisão da previsão no uso diário.
(1) Dados distorcidos e valores atípicos
Em séries temporais financeiras, os dados frequentemente apresentam assimetria ou contêm outliers. Se o pré-processamento adequado dos dados não for realizado, o processo de treino do modelo pode ser interrompido pelo ruído, afetando a precisão das previsões.
(2) Modelos simplificados e validação insuficiente
Alguns estudos podem depender muito de uma única estrutura matemática ao construir modelos, como usar apenas o modelo ARIMA para capturar tendências lineares, ignorando fatores não lineares no mercado. Isso pode levar à simplificação excessiva do modelo. Além disso, uma validação insuficiente do modelo pode resultar em um desempenho excessivamente otimista nos testes retrospetivos, mas em resultados de previsão pobres em aplicações reais (por exemplo, overfitting conduz a um excelente desempenho em dados históricos, mas a um desvio significativo na utilização no mundo real).
(3) Risco de Latência de Dados da API
Na negociação ao vivo, se o modelo depender de APIs para dados em tempo real, qualquer atraso na API ou falha em atualizar os dados a tempo pode afetar diretamente a operação do modelo e os resultados da previsão, levando ao fracasso na negociação ao vivo.
Medidas para Melhorar a Estabilidade do Modelo de Previsão
Perante os riscos mencionados acima, é necessário tomar medidas correspondentes para melhorar a estabilidade do modelo. As seguintes estratégias são particularmente importantes:
(1) Fontes de Dados Diversificadas e Pré-processamento de Dados
Combinar várias fontes de dados (como preços históricos, volume de negociação, dados de sentimento social, etc.) pode compensar as deficiências de um único modelo, enquanto a limpeza, transformação e divisão rigorosas dos dados devem ser realizadas. Esta abordagem melhora a capacidade de generalização do modelo e reduz os riscos apresentados pelo viés e valores atípicos dos dados.
(2) Seleção de Métricas Adequadas para Avaliação de Modelos
Durante o processo de construção do modelo, é essencial selecionar as métricas de avaliação apropriadas com base nas características dos dados (como MAPE, RMSE, AIC, BIC, etc.) para avaliar o desempenho do modelo e evitar o ajuste excessivo de forma abrangente. A validação cruzada regular e a previsão contínua são também passos críticos para melhorar a robustez do modelo.
(3) Validação do Modelo e Iteração
Uma vez estabelecido o modelo, este deve passar por uma validação rigorosa utilizando análise residual e mecanismos de deteção de anomalias. A estratégia de previsão deve ser ajustada continuamente com base nas mudanças de mercado. Por exemplo, introduzir aprendizagem sensível ao contexto para ajustar os parâmetros do modelo de acordo com as condições de mercado atuais dinamicamente é uma abordagem. Além disso, combinar modelos tradicionais com modelos de deep learning para formar um modelo híbrido é um método eficaz para melhorar a precisão e estabilidade das previsões.
Atenção aos Riscos de Conformidade
Finalmente, além dos riscos técnicos, devem ser considerados os riscos de privacidade de dados e conformidade ao utilizar fontes de dados não tradicionais, como dados de sentimento. Por exemplo, a Comissão de Valores Mobiliários dos EUA (SEC)SEC) tem requisitos rigorosos de revisão relativos à recolha e utilização de dados de sentimentos para prevenir riscos legais decorrentes de questões de privacidade.
Isto significa que durante o processo de recolha de dados, informações pessoalmente identificáveis (como nomes de utilizador, detalhes pessoais, etc.) devem ser anonimizadas. Isto tem como objetivo evitar que a privacidade pessoal seja exposta, ao mesmo tempo que se evita o uso indevido dos dados. Além disso, é essencial garantir que as fontes de dados recolhidos sejam legítimas e não obtidas através de meios impróprios (como raspagem de web não autorizada). Também é necessário divulgar publicamente os métodos de recolha e utilização de dados, permitindo que investidores e entidades reguladoras compreendam como os dados são processados e aplicados. Esta transparência ajuda a evitar que os dados sejam usados para manipular o sentimento do mercado.
Conclusão e Perspectivas Futuras
Em conclusão, os modelos de previsão de preços de criptomoedas baseados em aprendizado de máquina mostram grande potencial para lidar com a volatilidade e complexidade do mercado. Integrar estratégias de gestão de risco e explorar continuamente novas arquiteturas de modelos e métodos de integração de dados serão direções importantes para o futuro desenvolvimento da previsão de preços de criptomoedas. Com o avanço da tecnologia de aprendizado de máquina, acreditamos que surgirão modelos de previsão de preços de criptomoedas mais precisos e estáveis, proporcionando aos investidores um suporte de tomada de decisão mais robusto.











