Gate Ventures Research Insights: The Third Browser War: The Entry Battle in the AI Agent Era
TL;DR
The third browser war is quietly unfolding. Looking back at history, from Netscape and Microsoft’s Internet Explorer in the 1990s to the open-source Firefox and Google’s Chrome, the browser war has always been a concentrated manifestation of platform control and technological paradigm shifts. Chrome has secured its dominant position thanks to its rapid update speed and integrated ecosystem, while Google, through its search and browser duopoly, has formed a closed loop of information access.
But today, this landscape is shaking. The rise of large language models (LLMs) is enabling more and more users to complete tasks without clicking on the search results page, while traditional web page clicks are declining. Meanwhile, rumors that Apple intends to replace the default search engine in Safari further threaten Alphabet’s (Google’s parent company) profit base, and the market is beginning to express unease about the “orthodoxy of search.”
The browser itself is also facing a reshaping of its role. It is not just a tool for displaying web pages, but also a container for multiple capabilities, including data input, user behavior, and private identity. While AI agents are powerful, they still rely on the browser’s trust boundary and functional sandbox to complete complex page interactions, access local identity data, and control web page elements. Browsers are evolving from human interfaces to system call platforms for agents.
In this article, we explore whether browsers are still necessary. We believe that what could truly disrupt the current browser market landscape isn’t another “better Chrome,” but a new interaction structure: not just information display, but task invocation. Future browsers must be designed for AI agents—capable not only of reading, but also of writing and executing. Projects like Browser Use are attempting to semanticize page structure, transforming visual interfaces into structured text callable by LLM, mapping pages to commands and significantly reducing interaction costs.
Major projects are already testing the waters: Perplexity is building a native browser, Comet, that replaces traditional search results with AI; Brave is combining privacy protection with local reasoning, using LLM to enhance search and blocking capabilities; and crypto-native projects like Donut are targeting new entry points for AI to interact with on-chain assets. A common trait among these projects is their attempt to reshape the browser’s input layer, rather than beautify its output layer.
For entrepreneurs, opportunities lie within the triangle of input, structure, and agent access. As the interface for the future agent-based world, the browser means that whoever can provide structured, callable, and trustworthy “capabilities” will become a component of the next-generation platform. From SEO to AEO (Agent Engine Optimization), from page traffic to task chain invocation, product form and design thinking are being reshaped. The third browser war is taking place over “input” rather than “display.” Victory is no longer determined by who captures the user’s attention, but by who earns the agent’s trust and gains access.
A Brief History of Browser Development
In the early 1990s, before the internet became a part of everyday life, Netscape Navigator burst onto the scene, like a sailboat that opened the door to the digital world for millions of users. While not the first browser, it was the first to truly reach the masses and shape the internet experience. For the first time, people could browse the web with such ease through a graphical interface, as if the entire world had suddenly become accessible.
However, glory is often short-lived. Microsoft quickly recognized the importance of browsers and decided to forcibly bundle Internet Explorer into the Windows operating system, making it the default browser. This strategy, a true “platform killer,” directly undermined Netscape’s market dominance. Many users didn’t actively choose IE; rather, they simply accepted it as the default. Leveraging Windows’ distribution capabilities, IE quickly became the industry leader, while Netscape fell into decline.

In the midst of adversity, Netscape’s engineers chose a radical and idealistic path — they opened up the browser’s source code and called upon the open-source community. This decision was like a “Macedonian abdication” in the tech world, signaling the end of an old era and the rise of new forces. That code later became the foundation of the Mozilla browser project, first named Phoenix (symbolizing rebirth), but after several trademark disputes, it was finally renamed Firefox.
Firefox was not a mere copy of Netscape. It made breakthroughs in user experience, plugin ecosystems, and security. Its birth marked the victory of open-source spirit and injected fresh vitality into the entire industry. Some described Firefox as the “spiritual successor” to Netscape, akin to how the Ottoman Empire inherited the fading glory of Byzantium. Though exaggerated, the comparison is meaningful.
Yet, before Firefox was officially released, Microsoft had already launched six versions of Internet Explorer. By leveraging its early timing and system-bundling strategy, Firefox was placed in a catch-up position from the very beginning, ensuring that this race was never an equal competition starting from the same line.
At the same time, another early player quietly entered the stage. In 1994, the Opera browser was born in Norway, initially just an experimental project. But starting from version 7.0 in 2003, it introduced its self-developed Presto engine, pioneering support for CSS, adaptive layouts, voice control, and Unicode encoding. Although its user base was limited, it consistently led the industry technologically, becoming a “geek’s favorite.”
That same year, Apple launched the Safari browser — a meaningful turning point. At the time, Microsoft had invested $150 million into a struggling Apple to maintain a semblance of competition and avoid antitrust scrutiny. Although Safari’s default search engine was Google from the very beginning, this entanglement with Microsoft symbolized the complex and subtle relationships among internet giants: cooperation and competition, always intertwined.
In 2007, IE7 was released alongside Windows Vista, but the market response was lukewarm. Firefox, on the other hand, steadily increased its market share to about 20%, thanks to faster update cycles, a more user-friendly extension mechanism, and natural appeal to developers. The dominance of IE began to loosen, and the winds were shifting.
Google, however, took a different approach. Although it had been planning its own browser since 2001, it took six years to convince CEO Eric Schmidt to approve the project. Chrome debuted in 2008, built on the Chromium open-source project and the WebKit engine used by Safari. It was mocked as a “bloated” browser, but with Google’s deep expertise in advertising and brand-building, it rose rapidly.
Chrome’s key weapon was not its features, but its frequent update cycle (every six weeks) and unified cross-platform experience. In November 2011, Chrome surpassed Firefox for the first time, reaching a 27% market share; six months later, it overtook IE, completing its transformation from challenger to dominant leader.
Meanwhile, China’s mobile internet was forming its own ecosystem. Alibaba’s UC Browser surged in popularity in the early 2010s, especially in emerging markets like India, Indonesia, and China. With its lightweight design and data-compression features that saved bandwidth, it won over users on lower-end devices. By 2015, its global mobile browser market share exceeded 17%, and in India it once reached as high as 46%. But this victory was not long-lasting. As the Indian government tightened security reviews of Chinese apps, UC Browser was forced to exit key markets, gradually losing its former glory.
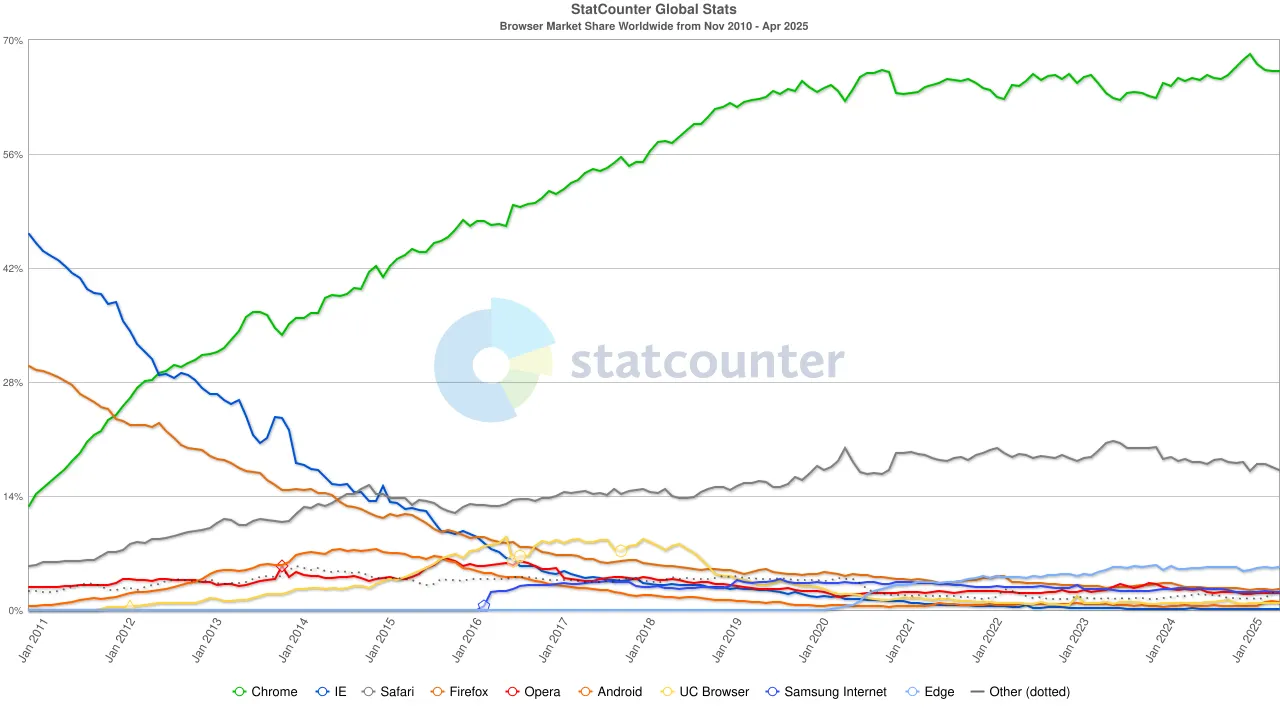
By the 2020s, Chrome’s dominance was firmly established, with its global market share stabilizing at around 65%. Notably, although Google’s search engine and the Chrome browser both belong to Alphabet, from a market perspective they represent two independent hegemonies — the former controlling about 90% of global search traffic, and the latter serving as the “first window” through which most users access the internet.
To maintain this dual-monopoly structure, Google has spared no expense. In 2022, Alphabet paid Apple approximately $20 billion just to keep Google as the default search engine in Safari. Analysts have pointed out that this expense amounted to about 36% of the search advertising revenue Google earned from Safari traffic. In other words, Google was effectively paying a “protection fee” to defend its moat.
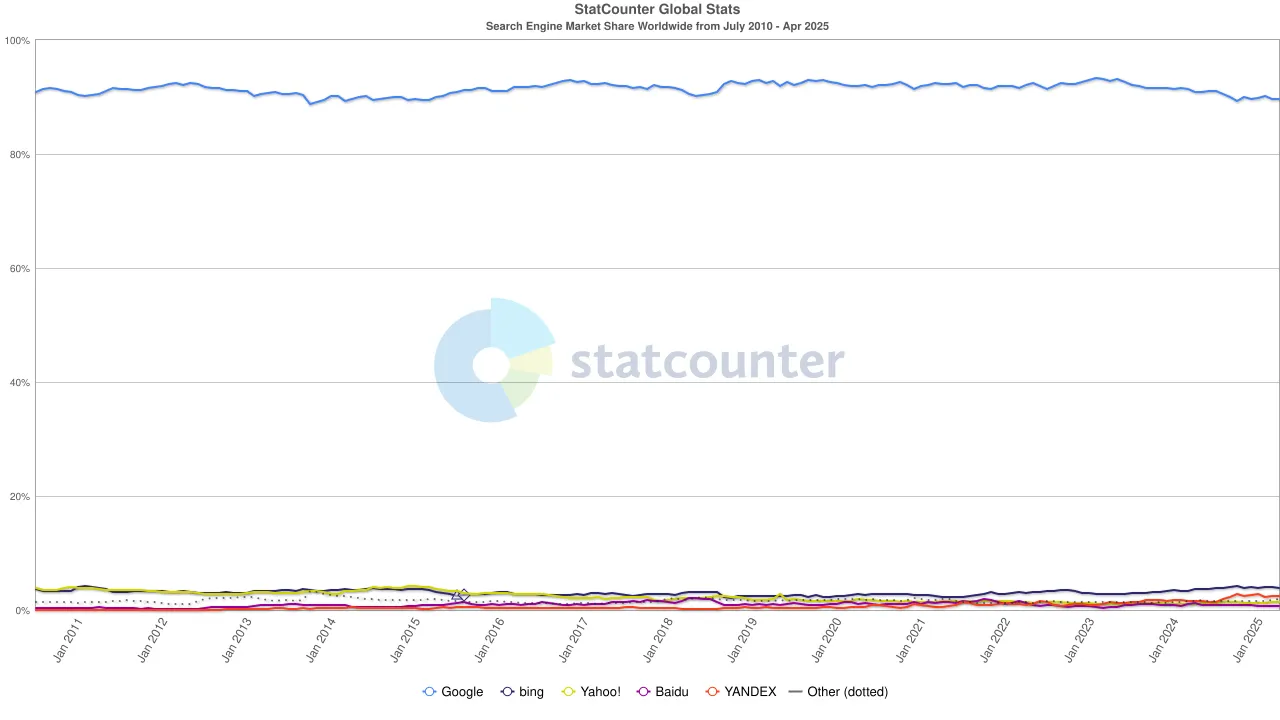
But the tide shifted once again. With the rise of large language models (LLMs), traditional search began to feel the impact. In 2024, Google’s share of the search market fell from 93% to 89%. Though it still dominated, cracks were beginning to show. Even more disruptive were rumors that Apple might launch its own AI-powered search engine. If Safari’s default search were to switch to Apple’s own ecosystem, it would not only reshape the competitive landscape but could also shake the very foundation of Alphabet’s profits. The market reacted swiftly: Alphabet’s stock price dropped from $170 to $140, reflecting not only investor panic but also a deep unease about the future direction of the search era.
From Navigator to Chrome, from open-source ideals to advertising-driven commercialization, from lightweight browsers to AI search assistants, the battle of browsers has always been a war over technology, platforms, content, and control. The battlefield keeps shifting, but the essence has never changed: whoever controls the gateway defines the future.
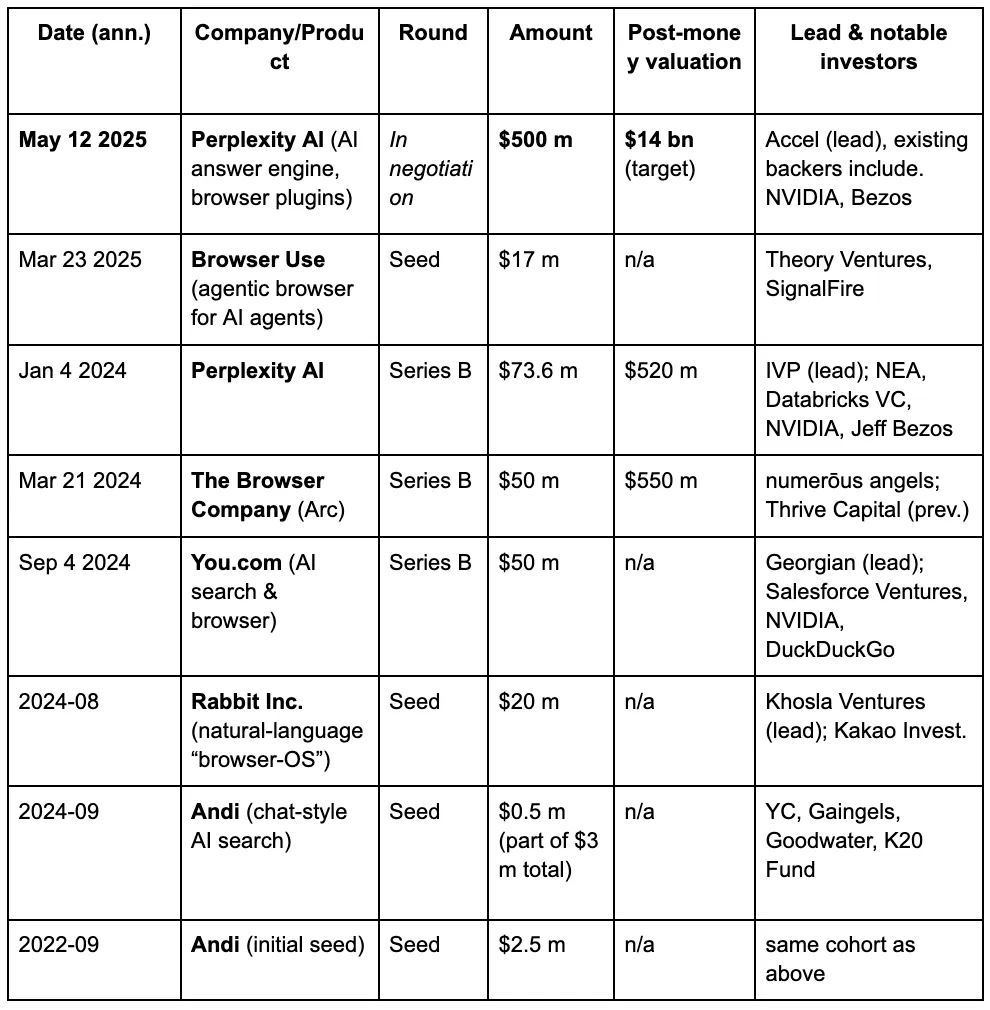
In the eyes of venture capitalists, a third browser war is gradually unfolding, driven by the new demands people place on search engines in the era of LLMs and AI. Below are the funding details of some well-known projects in the AI browser track.
The Outdated Architecture of Modern Browsers
When it comes to browser architecture, the classic traditional structure is shown in the diagram below:
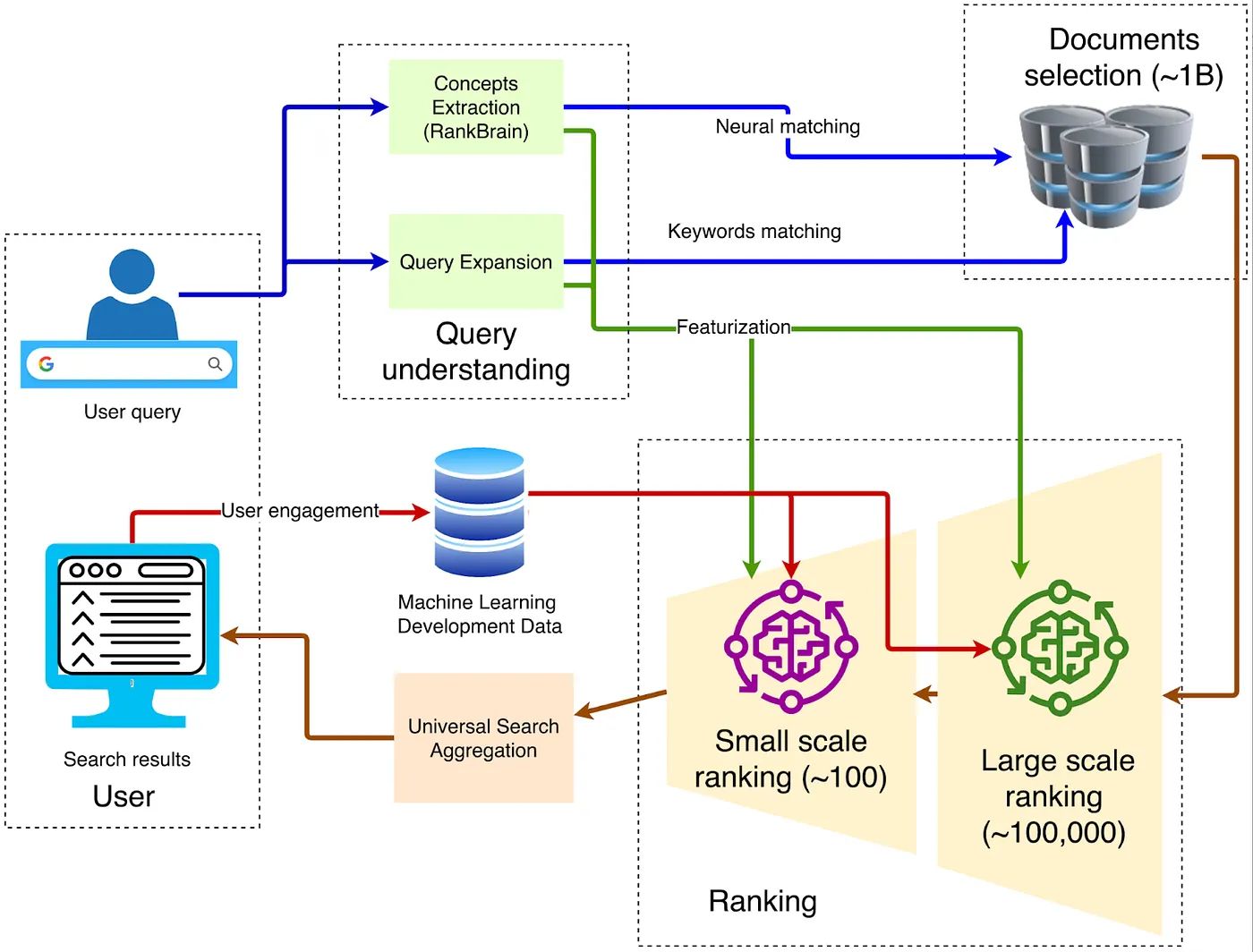
1. Client — Front-End Entry
The query is sent via HTTPS to the nearest Google Front End, where TLS decryption, QoS sampling, and geographic routing are performed. If abnormal traffic is detected (such as DDoS attacks or automated scraping), rate limiting or challenges can be applied at this layer.
2. Query Understanding
The front end needs to understand the meaning of the words typed by the user. This involves three steps:
Neural spell correction, such as turning “recpie” into “recipe”.
Synonym expansion, for example expanding “how to fix bike” to include “repair bicycle”.
Intent parsing, which determines whether the query is informational, navigational, or transactional, and then assigns the appropriate vertical request.
3. Candidate Retrieval
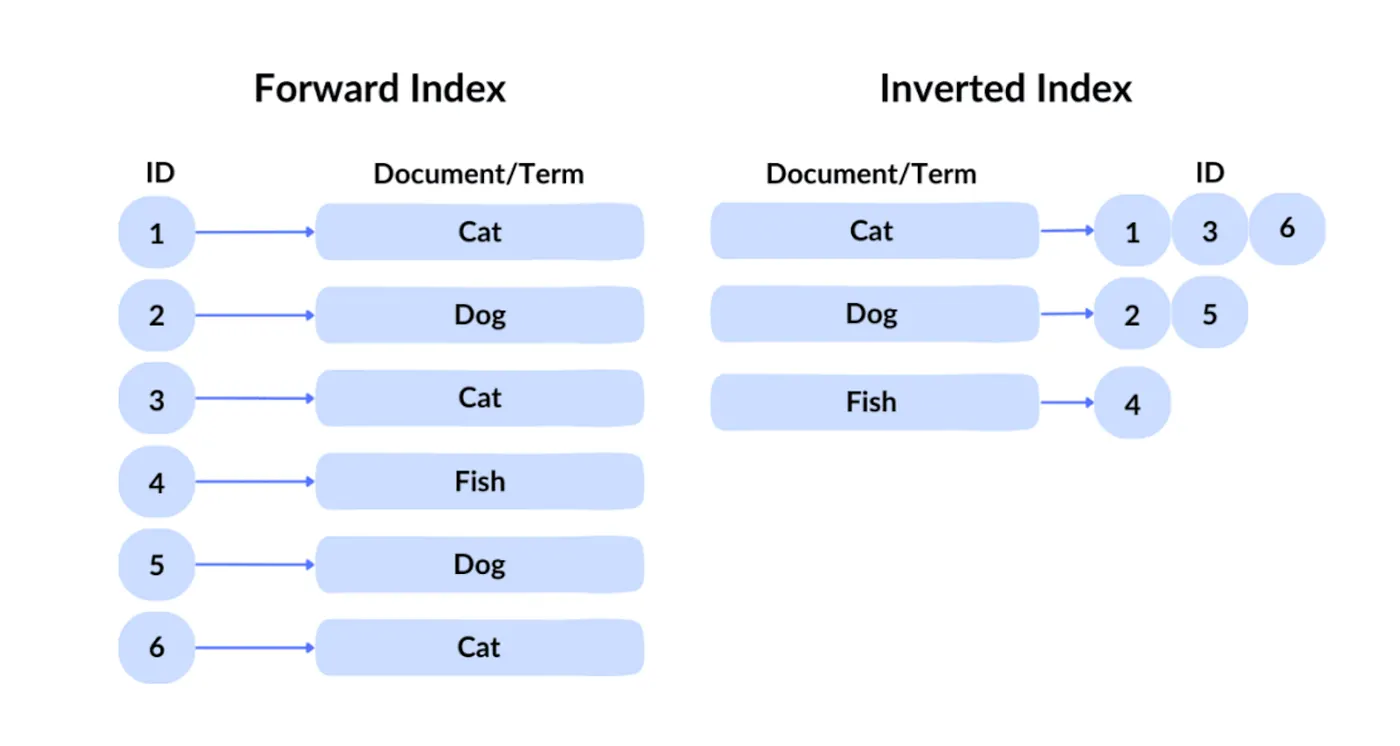
Google’s query technology is known as an inverted index. In a forward index, you retrieve a file given its ID. But since users cannot possibly know the identifiers of desired content across hundreds of billions of files, Google uses the traditional inverted index, which queries by content to identify which files contain the corresponding keywords.
Next, Google applies vector indexing to handle semantic search—that is, finding content similar in meaning to the query. It converts text, images, and other content into high-dimensional vectors (embeddings), then searches based on the similarity between those vectors. For example, if a user searches “how to make pizza dough”, the search engine can return results related to “pizza dough preparation guide”, because the two are semantically similar.
Through inverted indexing and vector indexing, roughly on the order of hundreds of thousands of webpages are filtered out in the initial screening stage.
4. Multi-Stage Ranking
The system typically uses thousands of lightweight features such as BM25, TF-IDF, and page quality scores to filter the hundreds of thousands of candidate pages down to about 1,000, forming an initial candidate set. Such systems are collectively referred to as recommendation engines. They rely on massive features generated from various entities, including user behavior, page attributes, query intent, and contextual signals. For example, Google combines user history, feedback from other users, page semantics, and query meaning, while also considering contextual elements such as time (time of day, day of the week) and external events like breaking news.
5. Deep Learning for Primary Ranking
At the initial retrieval stage, Google uses technologies like RankBrain and Neural Matching to understand the semantics of queries and filter out the most relevant results from massive document collections.
RankBrain, introduced by Google in 2015, is a machine learning system designed to better understand the meaning of user queries, especially queries never seen before. It transforms queries and documents into vector representations and calculates their similarity to find the most relevant results. For instance, for the query “how to make pizza dough”, even if no document contains an exact keyword match, RankBrain can identify content related to “pizza basics” or “dough preparation.”
Neural Matching, launched in 2018, was designed to further capture the semantic relationship between queries and documents. Using neural network models, it identifies fuzzy relationships between words to better match queries with web content. For example, for the query “why is my laptop fan so loud,” Neural Matching can understand that the user might be seeking troubleshooting information about overheating, dust buildup, or high CPU usage—even if those terms don’t explicitly appear in the query.
6. Deep Re-Ranking: The Application of BERT
After the initial filtering of relevant documents, Google applies BERT (Bidirectional Encoder Representations from Transformers) to refine the ranking and ensure that the most relevant results appear at the top. BERT is a pre-trained language model based on Transformers that can understand the contextual relationships of words within sentences.
In search, BERT is used to re-rank the documents retrieved in earlier stages. It jointly encodes queries and documents, computes their relevance scores, and then reorders the documents. For example, for the query “parking on a hill without a curb,” BERT can correctly interpret the meaning of “without a curb” and return results advising drivers to turn their wheels toward the roadside, rather than misinterpreting it as a situation with a curb.
For SEO engineers, this means they must carefully study Google’s ranking and machine learning recommendation algorithms in order to optimize web content in a targeted way, thereby gaining higher visibility in search rankings.
Why AI Will Reshape Browsers
First, we need to clarify: why does the browser as a form still need to exist? Is there a third paradigm beyond AI agents and browsers?
We believe that existence implies irreplaceability. Why can artificial intelligence use browsers but not completely replace them? Because the browser is a universal platform. It is not only an entry point for reading data but also a general entry point for inputting data. The world cannot only consume information—it must also produce data and interact with websites. Therefore, browsers that integrate personalized user information will continue to exist widely.
Here’s the key point: as a universal gateway, the browser is not just for reading data; users often need to interact with data. The browser itself is an excellent repository for storing user fingerprints. More complex user behaviors and automated actions must be carried out through the browser. The browser can store all user behavioral fingerprints, credentials, and other private information, enabling trustless invocation during automation. Interaction with data may evolve into this pattern:
User → calls AI Agent → Browser.
In other words, the only part that could be replaced lies in the natural trend of the world—toward greater intelligence, personalization, and automation. To be sure, this part can be handled by AI agents. But AI agents themselves are not well-suited to carry personalized user content, because they face multiple challenges regarding data security and usability. Specifically:
The browser is the repository for personalized content:
Most large models are hosted in the cloud, with session contexts dependent on server storage, making it difficult to directly access local passwords, wallets, cookies, and other sensitive data.
Sending all browsing and payment data to third-party models requires renewed user authorization; the EU’s DMA and U.S. state-level privacy laws both demand data minimization across borders.
Automatically filling in two-factor authentication codes, invoking cameras, or using GPUs for WebGPU inference must all be done within the browser sandbox.
Data context is highly dependent on the browser. Tabs, cookies, IndexedDB, Service Worker Cache, passkey credentials, and extension data are all stored within the browser.
Profound Changes in Interaction Forms
Returning to the topic from the beginning, our behavior when using browsers can generally be divided into three categories: reading data, inputting data, and interacting with data. Large language models (LLMs) have already profoundly changed the efficiency and methods by which we read data. The old practice of users searching webpages through keywords now appears outdated and inefficient.
When it comes to the evolution of user search behavior—whether the goal is to obtain summarized answers or to click through to webpages—many studies have already analyzed this shift.
In terms of user behavior patterns, a 2024 study showed that in the U.S., out of every 1,000 Google queries, only 374 ended in an open webpage click. In other words, nearly 63% were “zero-click” behaviors. Users have grown accustomed to obtaining information such as weather, exchange rates, and knowledge cards directly from the search results page.
What could truly trigger a massive transformation of browsers, however, is the data interaction layer. In the past, people interacted with browsers mainly by entering keywords—the maximum level of understanding the browser itself could handle. Now, users increasingly prefer to use full natural language to describe complex tasks, such as:
“Find me direct flights from New York to Los Angeles during a certain period.”
“Find me a flight from New York to Shanghai and then to Los Angeles.”
Even for humans, such tasks require a lot of time to visit multiple websites, gather information, and compare results. But these Agentic Tasks are gradually being taken over by AI agents.
This also aligns with the trajectory of history: automation and intelligence. People desire to free their hands, and AI agents will inevitably be deeply embedded into browsers. Future browsers must be designed with full automation in mind, especially considering:
How to balance the reading experience for humans with machine interpretability for AI agents.
How to ensure a single webpage serves both the end-user and the agent model.
Only by meeting both of these design requirements can browsers truly become stable carriers for AI agents to execute tasks.
Next, we will focus on five prominent projects—Browser Use, Arc (The Browser Company), Perplexity, Brave, and Donut. These projects represent future directions for AI browser evolution, as well as their potential for native integration within Web3 and crypto contexts.
From the perspective of user psychology, a 2023 survey showed that 44% of respondents considered regular organic results more trustworthy than featured snippets. Academic research has also found that in cases of controversy or lack of a single authoritative truth, users prefer results pages containing links from multiple sources.
In other words, while a portion of users do not fully trust AI-generated summaries, a significant percentage of behavior has already shifted to “zero-click.” Therefore, AI browsers still need to explore the right interaction paradigm—especially in the area of data reading. Because the hallucination problem in large models has not yet been fully solved, many users still struggle to completely trust automatically generated content summaries. In this respect, embedding large models into browsers does not necessarily require disruptive transformation. Instead, it simply requires incremental improvements in accuracy and controllability—a process that is already underway.
Browser Use
This is precisely the core logic behind the massive funding received by Perplexity and Browser Use. In particular, Browser Use has emerged as the second most promising innovation opportunity of early 2025, with both certainty and strong growth potential.

Browser Use has built a true semantic layer, with its core focus on creating a semantic recognition architecture for the next generation of browsers.
Browser Use reinterprets the traditional “DOM = a node tree for humans to see” into a “Semantic DOM = an instruction tree for LLMs to read.” This allows agents to precisely click, fill in, and upload without relying on “pixel coordinates.” Instead of using visual OCR or coordinate-based Selenium, this approach takes the route of “structured text → function calls,” making execution faster, saving tokens, and reducing errors. TechCrunch described it as “the glue layer that allows AI to truly understand web pages.” In March, Browser Use closed a $17 million seed round, betting on this foundational innovation.
Here’s how it works:
After HTML is rendered, it forms a standard DOM tree. The browser then derives an accessibility tree, which provides richer “roles” and “states” labels for screen readers.
Each interactive element (button, input, etc.) is abstracted into a JSON snippet with metadata such as role, visibility, coordinates, and executable actions.
The entire page is translated into a flattened list of semantic nodes, which the LLM can read in a single system prompt.
The LLM outputs high-level instructions (for example, click(node_id=”btn-Checkout”)), which are then replayed in the real browser.
The official blog describes this process as “turning website interfaces into structured text that LLMs can parse.”
Furthermore, if this standard is ever adopted by the W3C, it could greatly solve the browser input problem. Next, we will look at the open letter and case studies from The Browser Company to further explain why their approach is flawed.
Arc
The Browser Company (the parent company of Arc) stated in its open letter that the Arc browser will enter regular maintenance mode, while the team will shift its focus to developing DIA, a browser fully oriented toward AI. In the letter, they also admitted that the specific implementation path for DIA has not yet been determined. At the same time, the team outlined several predictions about the future of the browser market.
Based on these predictions, we further believe that if the current browser landscape is truly to be disrupted, the key lies in changing the output side of interaction.
Below are three of the predictions about the future browser market shared by the Arc team.
https://browsercompany.substack.com/p/letter-to-arc-members-2025
First, the Arc team believes that webpages will no longer be the primary interface for interaction. Admittedly, this is a bold and challenging claim, and it is also the main reason we remain skeptical of their founder’s reflections. In our view, this perspective significantly underestimates the role of the browser, and it highlights the key issue that the team overlooked when exploring the AI browser path.
Large models perform excellently at capturing intent—for example, understanding instructions like “help me book a flight.” However, they remain insufficient when it comes to carrying information density. When a user needs something like a dashboard, a Bloomberg Terminal–style notebook, or a visual canvas like Figma, nothing can surpass a finely tuned webpage with pixel-level precision. The ergonomics of each product—charts, drag-and-drop functionality, hotkeys—are not superficial decoration, but essential affordances that compress cognition. These capabilities cannot be replicated by simple conversational interactions. Taking Gate.com as an example: if a user wants to execute an investment action, relying solely on AI conversation is far from enough, since users heavily depend on structured input, accuracy, and clear presentation of information.
The Arc team’s roadmap contains a fundamental flaw: it fails to clearly distinguish that “interaction” is composed of two dimensions—input and output. On the input side, their view holds some validity in certain scenarios, as AI can indeed improve the efficiency of command-style interactions. But on the output side, their assumption is clearly unbalanced, overlooking the browser’s core role in information presentation and personalized experiences. For instance, Reddit has its own unique layout and information architecture, while AAVE has a completely different interface and structure. As a platform that simultaneously stores highly private data and renders diverse product interfaces, the browser has limited substitutability on the input side, while its complexity and non-standardized nature on the output side make it even harder to disrupt.
By contrast, current AI browsers mostly concentrate on the “output summarization” layer: summarizing pages, extracting information, generating conclusions. This is not enough to pose a fundamental challenge to mainstream browsers or search systems like Google—it merely chips away at the market share for search summaries.
Therefore, the only technology that could truly shake Chrome’s 66% market share is destined not to be “the next Chrome.” To achieve real disruption, the rendering model of browsers must be fundamentally restructured to adapt to the interaction needs of the AI Agent era, especially in terms of input-side architecture design. That is why we find the technical path taken by Browser Use far more convincing—it focuses on structural changes at the underlying mechanism of browsers. Once any system achieves “atomic” or “modular” design, the programmability and composability derived from it unlock disruptive potential. This is exactly the direction Browser Use is pursuing today.
In summary, the operation of AI agents still heavily depends on the existence of browsers. Browsers are not only the main repositories for complex personalized data, but also the universal rendering interfaces for diverse applications, and thus will continue to serve as the core gateway for interaction in the future. As AI agents become deeply embedded in browsers to complete fixed tasks, they will interact with user data and specific applications mainly through the input side. For this reason, the current rendering model of browsers must be innovated to achieve maximum compatibility and adaptability with AI agents—ultimately allowing them to capture applications more effectively.
Perplexity
Perplexity is an AI search engine renowned for its recommendation system. Its latest valuation has soared to $14 billion, nearly a fivefold increase from $3 billion in June 2024. It now handles more than 400 million search queries per month. In September 2024 alone, it processed around 250 million queries, marking an eightfold year-over-year increase in user search volume, with over 30 million monthly active users.
Its main feature is the ability to summarize pages in real time, giving it a strong advantage in accessing up-to-date information. Earlier this year, Perplexity began building its own native browser, Comet. The company describes Comet as a browser that not only “displays” webpages but also “thinks” about them. Officially, they claim it will embed Perplexity’s answer engine deep inside the browser itself, following a “whole machine” approach reminiscent of Steve Jobs’ philosophy: deeply integrating AI tasks at the foundational browser level, rather than merely building sidebar plugins.
With concise answers backed by citations, Comet aims to replace the traditional “ten blue links” and compete directly with Chrome.
But Perplexity still needs to solve two core problems: high search costs and low profit margins from marginal users. Although Perplexity currently leads in the AI search field, Google announced at its 2025 I/O conference a large-scale intelligent overhaul of its core products. For browsers, Google launched a new browser tab experience called AI Model, which integrates Overview, Deep Research, and future Agentic capabilities. The entire initiative is referred to as “Project Mariner.”
Google is actively advancing its AI transformation, which means that superficial feature imitation—such as Overview, Deep Research, or Agentics—will hardly pose a real threat. What could truly establish a new order amidst the chaos is rebuilding browser architecture from the ground up, deeply embedding large language models (LLMs) into the browser kernel, and fundamentally transforming interaction methods.
Brave
Brave is one of the earliest and most successful browsers within the crypto industry. Built on the Chromium architecture, it is compatible with extensions from the Google Store. Brave attracts users with a model based on privacy and earning tokens through browsing. Its development path demonstrates a certain growth potential. However, from a product perspective, while privacy is indeed important, demand remains concentrated within specific user groups. For the broader public, privacy awareness has not yet become a mainstream decision-making factor. Therefore, attempting to rely on this feature alone to disrupt existing giants is unlikely to succeed.
As of now, Brave has reached 82.7 million monthly active users (MAU) and 35.6 million daily active users (DAU), holding a market share of about 1%–1.5%. Its user base has shown steady growth: from 6 million in July 2019, to 25 million in January 2021, to 57 million in January 2023, and by February 2025, it surpassed 82 million. Its compound annual growth rate remains in the double digits.
Brave handles approximately 1.34 billion search queries per month, which is about 0.3% of Google’s volume.
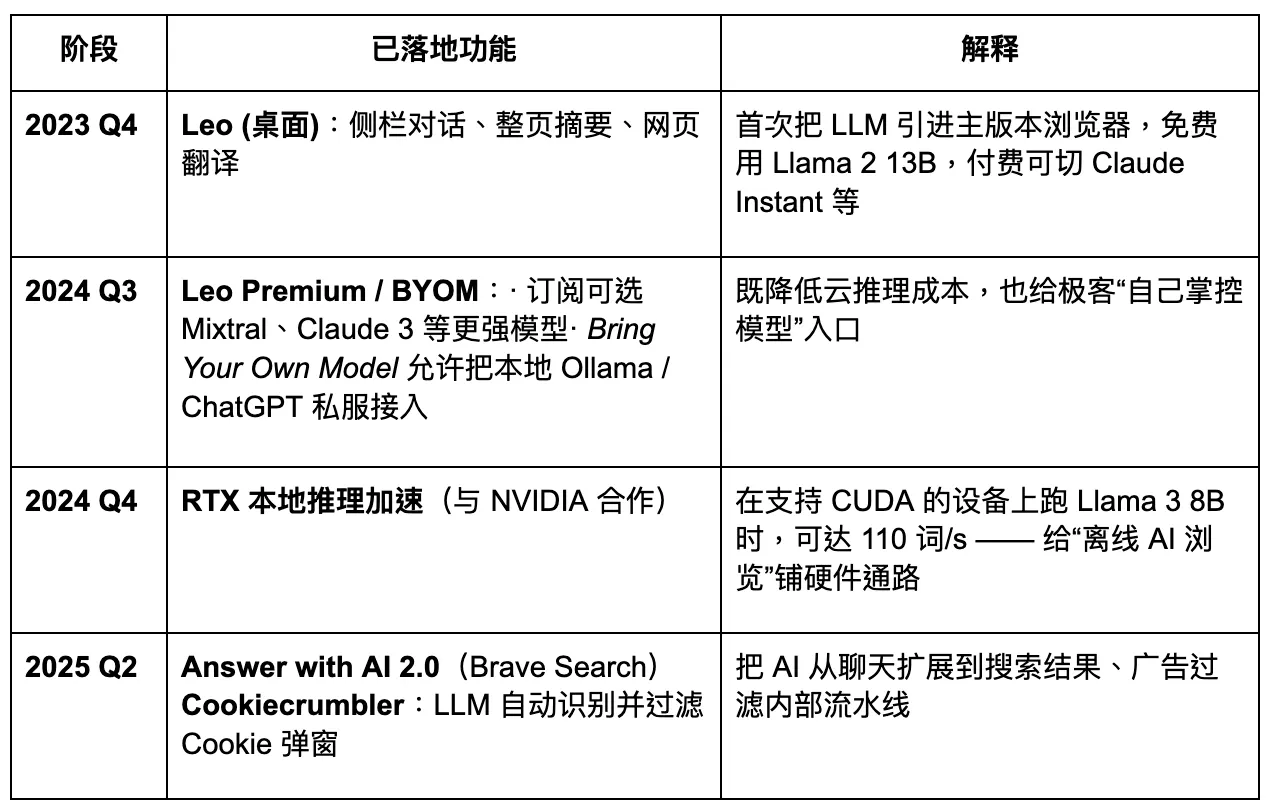
Brave is planning to upgrade into a privacy-first AI browser. However, its limited access to user data reduces the level of customization possible for large models, which in turn hinders fast and precise product iteration. In the coming Agentic Browser era, Brave may maintain a stable share among specific privacy-focused user groups, but it will be difficult for it to become a dominant player. Its AI assistant, Leo, functions more like a plugin enhancement—offering some content summarization capabilities, but lacking a clear strategy for a full shift toward AI agents. Innovation in interaction remains insufficient.
Donut
Recently, the crypto industry has also made progress in the field of Agentic Browsers. Early-stage project Donut raised $7 million in a pre-seed round, led by Hongshan (Sequoia China), HackVC, and Bitkraft Ventures. The project is still in its early conceptual stage, with a vision of achieving “Discovery – Decision-making – and Crypto-native Execution” as an integrated capability.
The core direction is to combine crypto-native automation execution paths. As a16z has predicted, agents may replace search engines as the main traffic gateway in the future. Entrepreneurs will no longer compete around Google’s ranking algorithms, but rather fight for the traffic and conversions that come from agent execution. The industry has already named this trend “AEO” (Answer / Agent Engine Optimization), or even further, “ATF” (Agentic Task Fulfillment)—where the goal is no longer to optimize search rankings, but to directly serve intelligent models that can complete tasks for users, such as placing orders, booking tickets, or writing letters.
For Entrepreneurs
First, it must be acknowledged: the browser itself remains the largest unreconstructed “gateway” in the internet world. With around 2.1 billion desktop users and over 4.3 billion mobile users globally, it serves as the common carrier for data input, interactive behavior, and personalized fingerprint storage. The reason for its persistence is not inertia, but the browser’s inherent dual nature: it is both the entry point for reading data and the exit point for writing actions.
Therefore, for entrepreneurs, the true disruptive potential does not lie in optimizing the “page output” layer. Even if one could replicate Google-like AI overview functions in a new tab, that would still be just an iteration at the plugin layer, not a fundamental paradigm shift. The real breakthrough lies on the “input side”—how to make AI agents actively call your product to complete specific tasks. This will determine whether a product can embed into the agent ecosystem, capture traffic, and share in the value distribution.
In the search era, the competition was about clicks; in the agent era, it is about calls.
If you are an entrepreneur, you should reimagine your product as an API component—something an intelligent agent can not only understand but also invoke. This requires you to consider three dimensions right from the start of product design:
1. Interface Structure Standardization: Is your product callable?
The ability of an agent to invoke a product depends on whether its information structure can be standardized and abstracted into a clear schema. For example, can key actions such as user registration, order placement, or comment submission be described through a semantic DOM structure or JSON mapping? Does the system provide a state machine so the agent can reliably replicate user workflows? Can user interactions on the page be scripted? Does the product offer stable webhooks or API endpoints?
This is precisely why Browser Use succeeded in raising funds—it transformed the browser from a flat HTML renderer into a semantic tree callable by LLMs. For entrepreneurs, adopting a similar design philosophy in web products means preparing for structured adaptation in the AI agent era.
2. Identity and Access: Can you help agents “cross the trust barrier”?
For agents to complete transactions or call payment and asset functions, they require a trusted intermediary—could you become that intermediary? Browsers naturally have the ability to read local storage, access wallets, handle CAPTCHAs, and integrate two-factor authentication. This makes them more suitable than cloud-hosted models for executing tasks. This is especially true in Web3, where asset interaction interfaces are not standardized. Without “identity” or “signing ability,” an agent cannot move forward.
For crypto entrepreneurs, this opens a highly imaginative white space: the “MCP (Multi Capability Platform) of the blockchain world.” This could take the form of a universal command layer (allowing agents to call Dapps), a standardized contract interface set, or even a lightweight local wallet + identity hub.
3. Rethinking Traffic Mechanisms: The future is not SEO, but AEO / ATF.
In the past, you had to win Google’s algorithm; now you need to be embedded in the task chains of AI agents. This means your product must have clear task granularity: not a “page,” but a series of callable capability units. It also means starting to optimize for Agent Engine Optimization (AEO) or adapt to Agentic Task Fulfillment (ATF). For example, can the registration process be simplified into structured steps? Can pricing be pulled through an API? Is inventory accessible in real time?
You may even need to adapt to different calling syntaxes across LLM frameworks—since OpenAI and Claude, for example, have different preferences for function calls and tool usage. Chrome is the terminal of the old world, not the gateway to the new one. The projects of the future will not rebuild browsers, but rather make browsers serve agents—building bridges for the new generation of “instruction flows.”
What you need to build is the “interface language” through which agents call your world.
What you need to earn is a place in the trust chain of intelligent systems.
What you need to construct is an “API castle” in the next search paradigm.
If Web2 captured user attention through UI, then the Web3 + AI Agent era will capture agent execution intent through call chains.
Disclaimer
This content does not constitute an offer, solicitation, or recommendation. You should always seek independent professional advice before making any investment decision. Please note that Gate and/or Gate Ventures may restrict or prohibit some or all services in restricted regions. Please read the applicable user agreement for more details.
About Gate Ventures
Gate Ventures is the venture capital arm of Gate, focusing on investments in decentralized infrastructure, ecosystems, and applications—technologies that will reshape the world in the Web 3.0 era. Gate Ventures works with global industry leaders to empower teams and startups with innovative thinking and capabilities to redefine the way society and finance interact.
Website: https://www.gate.com/ventures
Share
Content

