Khi nhu cầu về dữ liệu hành vi trong thế giới thực tăng vọt cùng với sự phát triển của Robotics AI và Embodied AI, các mạng dữ liệu phi tập trung đang nổi lên như một trụ cột quan trọng của cơ sở hạ tầng AI.
Caspius và các nền tảng dữ liệu AI truyền thống đều phục vụ cho việc thu thập dữ liệu huấn luyện AI, khiến chúng thường xuyên được đem ra so sánh. Dù cả hai đều hỗ trợ huấn luyện mô hình AI, nhưng chúng có sự khác biệt cơ bản về kiểm soát dữ liệu, logic phân phối giá trị và kiến trúc hệ sinh thái.
Caspius là gì?
Caspius là một giao thức cơ sở hạ tầng dữ liệu được thiết kế riêng cho Robotics AI và Embodied AI. Giao thức này thu thập dữ liệu hành vi trong thế giới thực thông qua một mạng lưới mở, cung cấp nguyên liệu thô cho việc huấn luyện mô hình AI.
Dự án tập trung vào video góc nhìn thứ nhất, quỹ đạo chuyển động và dữ liệu tương tác môi trường cần thiết cho việc huấn luyện robot. Nhờ có nguồn dữ liệu này, các hệ thống robot có thể nắm vững cách thực hiện hành động trong thế giới thực, suy luận không gian và phản hồi vật lý.
Không giống như các nền tảng truyền thống, Caspius tận dụng cơ chế khuyến khích của Blockchain, cho phép người dùng thông thường đóng góp dữ liệu. Khi tải lên dữ liệu huấn luyện hợp lệ, người dùng sẽ nhận được phần thưởng bằng token CAS.
Từ góc độ định vị, Caspius gần gũi hơn với các mạng dữ liệu AI mở và các dự án cơ sở hạ tầng DePIN.
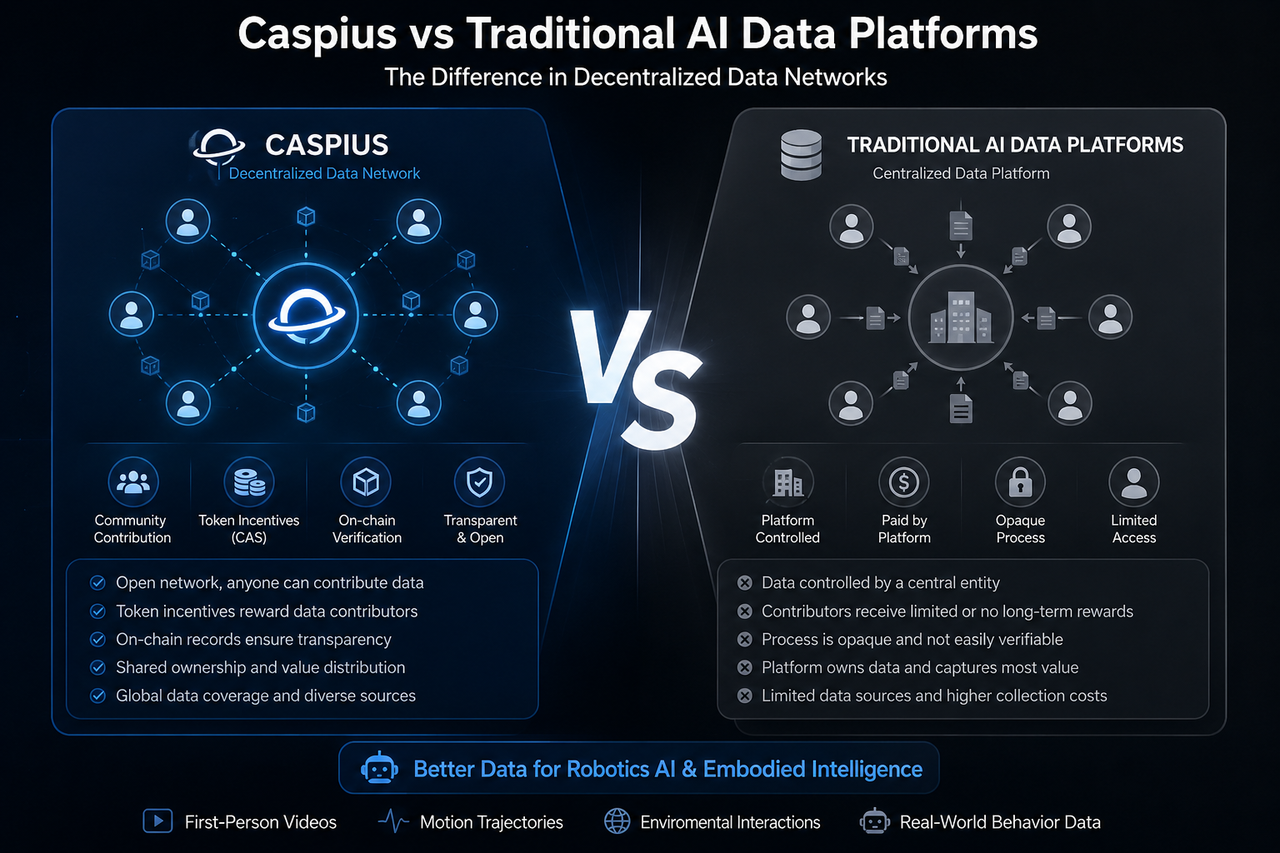
Nền tảng dữ liệu AI truyền thống là gì?
Các nền tảng dữ liệu AI truyền thống thường được vận hành bởi các doanh nghiệp tập trung, đảm nhận việc thu thập, chú thích, tổ chức và bán dữ liệu.
Trong mô hình thông thường, nền tảng sẽ chuẩn hóa quy trình thu thập dữ liệu. Các nhóm chú thích sau đó phân loại và xử lý dữ liệu, cuối cùng cung cấp dịch vụ dữ liệu huấn luyện cho các công ty AI. Ngày nay, nhiều mô hình ngôn ngữ lớn, hệ thống nhận dạng hình ảnh và mô hình lái xe tự động đều dựa vào dữ liệu từ các nền tảng này.
Cách tiếp cận này đã trở thành tiêu chuẩn trong ngành AI suốt nhiều năm, được đánh giá cao nhờ hiệu quả vận hành và quy trình xác thực dữ liệu trưởng thành. Tuy nhiên, quyền kiểm soát dữ liệu và phân phối doanh thu thường tập trung vào nền tảng.
Quyền sở hữu dữ liệu khác nhau thế nào giữa Caspius và nền tảng dữ liệu AI truyền thống?
Quyền sở hữu dữ liệu là một trong những điểm khác biệt chính giữa Caspius và các nền tảng dữ liệu AI truyền thống.
Các nền tảng truyền thống thường tuân theo mô hình tập trung: họ thu thập, lưu trữ và kiếm tiền từ dữ liệu, trong khi người đóng góp hầu như không có vai trò gì trong quá trình phân phối giá trị về sau.
Ngược lại, Caspius đề cao sự hợp tác mở và logic khuyến khích trên chuỗi. Về mặt lý thuyết, người đóng góp dữ liệu không chỉ có thể tải lên dữ liệu huấn luyện mà còn tham gia vào các luồng giá trị của hệ sinh thái thông qua cơ chế token.
Bảng dưới đây nêu bật sự khác biệt về cấu trúc trong dữ liệu:
| Khía cạnh so sánh |
Caspius |
Nền tảng dữ liệu AI truyền thống |
| Phương thức kiểm soát dữ liệu |
Mạng mở |
Kiểm soát tập trung bởi nền tảng |
| Mô hình đóng góp dữ liệu |
Hợp tác cộng đồng |
Doanh nghiệp thu thập |
| Phân phối doanh thu |
Cơ chế khuyến khích trên chuỗi |
Do nền tảng dẫn dắt |
| Minh bạch dữ liệu |
Cơ chế có thể xác minh |
Quy trình không minh bạch |
| Cấu trúc mạng |
Phi tập trung |
Tập trung |
Những khác biệt này đưa Caspius đến gần hơn với nền kinh tế dữ liệu Web3.
Cơ chế khuyến khích khác nhau thế nào giữa Caspius và nền tảng dữ liệu AI truyền thống?
Các nền tảng dữ liệu AI truyền thống thường vận hành theo mô hình thanh toán cố định. Ví dụ, họ trả tiền cho người thu thập dữ liệu hoặc nhóm chú thích, sau đó bán dữ liệu đã xử lý cho các công ty AI.
Trong khi đó, Caspius sử dụng khuyến khích token để mở rộng nguồn cung dữ liệu. Người dùng tải lên dữ liệu huấn luyện hợp lệ sẽ nhận được token CAS, và mạng lưới thu hút thêm nhiều người đóng góp thông qua phần thưởng kinh tế.
Lợi thế cốt lõi của mô hình này là sự tham gia mở. Không giống như các nền tảng truyền thống dựa vào việc thu thập dữ liệu do doanh nghiệp quản lý, Caspius ưu tiên hợp tác cộng đồng và khai thác dữ liệu trên phạm vi toàn cầu.
Tuy nhiên, mô hình khuyến khích token có thể chịu tác động từ chu kỳ thị trường, biến động giá token và tốc độ phát triển hệ sinh thái, vì vậy tính khả thi lâu dài của nó vẫn còn là một câu hỏi chưa có lời giải.
Minh bạch dữ liệu và khả năng xác minh khác nhau thế nào giữa Caspius và nền tảng dữ liệu AI truyền thống?
Các nền tảng dữ liệu AI truyền thống thường hoạt động như những hệ thống khép kín, khiến người bên ngoài khó truy vết nguồn gốc dữ liệu, tiêu chí lọc hoặc chuẩn mực kiểm toán.
Caspius hướng đến việc tăng cường minh bạch thông qua các cơ chế trên chuỗi. Chẳng hạn, một số quy trình dữ liệu có thể bao gồm hồ sơ trên chuỗi, các đóng góp có thể xác minh và kiểm toán cộng đồng, qua đó thúc đẩy sự hợp tác mở.
Minh bạch đang ngày càng quan trọng đối với các mạng dữ liệu AI. Khi các mô hình AI mở rộng quy mô, thị trường đang chú ý nhiều hơn đến nguồn gốc dữ liệu huấn luyện và kiểm soát chất lượng.
Tuy nhiên, đối với dữ liệu huấn luyện robot, chỉ riêng hồ sơ trên chuỗi khó có thể đảm bảo chất lượng, do đó các cơ chế xác thực dữ liệu mạnh mẽ là điều bắt buộc.
Caspius phải đối mặt với những thách thức nào?
Bất chấp tiềm năng tăng trưởng của các mạng dữ liệu AI phi tập trung, Caspius cần vượt qua một số rào cản.
Đầu tiên là tính xác thực. Dữ liệu huấn luyện robot đòi hỏi độ chính xác cao; dữ liệu chất lượng thấp hoặc giả mạo có thể phá hỏng quá trình huấn luyện mô hình. Vì thế, cơ chế xác minh chặt chẽ là vô cùng quan trọng.
Thứ hai là các vấn đề về quyền riêng tư và quy định. Dữ liệu video và hành vi trong thế giới thực có thể liên quan đến quyền riêng tư của người dùng, vị trí địa lý và các quy định khác nhau giữa các khu vực.
Hơn nữa, các công ty AI lớn đã sở hữu khả năng thu thập dữ liệu nội bộ mạnh mẽ. Liệu các mạng dữ liệu mở có thể duy trì lợi thế cạnh tranh về lâu dài hay không vẫn còn phải chờ thử thách.
Là một tài sản tiền điện tử, hiệu suất thị trường của CAS cũng chịu tác động từ chu kỳ ngành và biến động thị trường.
Kết luận
Mặc dù cả Caspius và nền tảng dữ liệu AI truyền thống đều hỗ trợ huấn luyện mô hình AI, nhưng chúng khác biệt rõ rệt về cấu trúc mạng dữ liệu, logic phân phối giá trị và thiết kế hệ sinh thái.
Các nền tảng truyền thống dựa vào quản lý tập trung, trong khi Caspius đề cao sự hợp tác mở, đóng góp cộng đồng và khuyến khích trên chuỗi. Với sự phát triển nhanh chóng của Robotics AI và Embodied AI, nhu cầu về dữ liệu huấn luyện trong thế giới thực ngày càng tăng, và các mạng dữ liệu phi tập trung đang trở thành một thành phần quan trọng của cơ sở hạ tầng AI.
Tuy nhiên, thị trường dữ liệu AI vẫn đang phát triển với tốc độ chóng mặt. Các vấn đề xoay quanh chất lượng dữ liệu, tuân thủ quy định và tính bền vững của hệ sinh thái sẽ tiếp tục định hình quỹ đạo dài hạn của ngành.
Câu hỏi thường gặp
Nền tảng dữ liệu AI truyền thống là gì?
Các nền tảng dữ liệu AI truyền thống thường được vận hành bởi các doanh nghiệp tập trung, chịu trách nhiệm thu thập, chú thích, quản lý và phân phối thương mại dữ liệu.
Sự khác biệt lớn nhất giữa Caspius và nền tảng dữ liệu AI truyền thống là gì?
Sự khác biệt chính nằm ở cấu trúc mạng dữ liệu. Caspius đề cao sự hợp tác mở và khuyến khích trên chuỗi, trong khi các nền tảng truyền thống dựa vào quản lý tập trung.
Tại sao robotics AI lại cần nhiều dữ liệu thế giới thực đến vậy?
Hệ thống robot cần học cách thực hiện hành động, hiểu mối quan hệ không gian và tương tác với môi trường. Chỉ riêng dữ liệu văn bản là không đủ để huấn luyện các hành vi phức tạp.
Các mạng dữ liệu AI phi tập trung có những rủi ro gì?
Các mạng dữ liệu phi tập trung có thể gặp những thách thức liên quan đến tính xác thực của dữ liệu, tuân thủ quyền riêng tư, chất lượng dữ liệu và tính bền vững của hệ sinh thái.









