runesleo
用戶暫無簡介
runesleo
一個主戰場約 96% 勝率的 Polymarket 玩家:我把 BipBop 的 1632 筆倉位拆開了
排行榜上這個帳號:BipBop
1632 筆已結算倉位,主戰場勝率約 96%,連續多個月月月都為正。
大多數人第一反應是:抄他。
我們真去抄了「看起來像他」的那一層——把「買 0.85–0.95 高概率盤、拿到結算」做成機械策略,回測 5378 個市場(高概率盤對照組):勝率 88.9%,淨收益 −2.5%。
勝率是幻覺。高勝率可以是虧錢策略。他賺的,不是你以為的那筆錢。
——
我拆了什麼
拉全史公開成交 2414 筆,把 1632 個已結算倉位對上官方結算,再按事件類型 × 入場價格帶切矩陣。
已結算合計:成本約 $30.0 萬,利潤約 +$5.8 萬,ROI 約 +19%。
不給可跟單路徑。只講聚合結果,和一套以後也能用來看別人的讀法。
——
主結論:利潤不在 0.85+
主戰場是 mention / say 類事件。
(圖 1:勝率幻覺對照)
(圖 2:主戰場四價格帶)
讀法只有三句:
1. 別被最高勝率騙。0.85+ 最好看,但不是錢袋。
2. 別被最高 ROI 騙。<0.4 很猛,樣本太少,當不了主引擎。
3. 先找絕對利潤落點,再解釋它為什麼成立。
主戰場裡,0.6–0.85 絕對利潤約 +$28.6K;0.85+ 只有約 +$10.9K。筆數更少的中段,反而搬走了
查看原文排行榜上這個帳號:BipBop
1632 筆已結算倉位,主戰場勝率約 96%,連續多個月月月都為正。
大多數人第一反應是:抄他。
我們真去抄了「看起來像他」的那一層——把「買 0.85–0.95 高概率盤、拿到結算」做成機械策略,回測 5378 個市場(高概率盤對照組):勝率 88.9%,淨收益 −2.5%。
勝率是幻覺。高勝率可以是虧錢策略。他賺的,不是你以為的那筆錢。
——
我拆了什麼
拉全史公開成交 2414 筆,把 1632 個已結算倉位對上官方結算,再按事件類型 × 入場價格帶切矩陣。
已結算合計:成本約 $30.0 萬,利潤約 +$5.8 萬,ROI 約 +19%。
不給可跟單路徑。只講聚合結果,和一套以後也能用來看別人的讀法。
——
主結論:利潤不在 0.85+
主戰場是 mention / say 類事件。
(圖 1:勝率幻覺對照)
(圖 2:主戰場四價格帶)
讀法只有三句:
1. 別被最高勝率騙。0.85+ 最好看,但不是錢袋。
2. 別被最高 ROI 騙。<0.4 很猛,樣本太少,當不了主引擎。
3. 先找絕對利潤落點,再解釋它為什麼成立。
主戰場裡,0.6–0.85 絕對利潤約 +$28.6K;0.85+ 只有約 +$10.9K。筆數更少的中段,反而搬走了

- 打賞
- 按讚
- 回覆
- 轉發
- 分享
Codex 掉線了,恭喜大家即將迎來一波新的額度重置!
查看原文
- 打賞
- 按讚
- 回覆
- 轉發
- 分享
自動交易現在很熱門,大家都在教 Claude 直接下單。
但權限不該這麼綁在一起。
可以拿走的一條規則是:研究權限可以給 Agent,交易權限(錢包、簽名、下單)不能一起交。
正確拆法是:只開公共只讀研究面,執行面永遠單獨、人工放行。
polymarket-toolkit 就是這麼做的。
GitHub runesleo/polymarket-toolkit 開源後,MCP 提供了 10 個只讀工具。
能查 profile、活動、市場掃描、贖回狀態這些研究工作。
工具不帶 key、不連錢包,也完全不能下單。
npm 上的 polymarket-toolkit-mcp 最新版 0.7.2,規則一致。
先把研究面開放出來,錢包簽名和訂單執行走另一道人工門。
查看原文但權限不該這麼綁在一起。
可以拿走的一條規則是:研究權限可以給 Agent,交易權限(錢包、簽名、下單)不能一起交。
正確拆法是:只開公共只讀研究面,執行面永遠單獨、人工放行。
polymarket-toolkit 就是這麼做的。
GitHub runesleo/polymarket-toolkit 開源後,MCP 提供了 10 個只讀工具。
能查 profile、活動、市場掃描、贖回狀態這些研究工作。
工具不帶 key、不連錢包,也完全不能下單。
npm 上的 polymarket-toolkit-mcp 最新版 0.7.2,規則一致。
先把研究面開放出來,錢包簽名和訂單執行走另一道人工門。
- 打賞
- 按讚
- 回覆
- 轉發
- 分享
當你不在家裡長輩身邊,而他們又有很明確的需求時,現在有了 AI,真的可以很方便地做出高度客製的小工具。
例如我家裡有長輩需要做一段時間的肌肉復健訓練。我把已確認過的動作和強度做成一個專門給他使用的網頁:一打開就能看到今天要練什麼,一畫面一項,直接跟著做。後續如果計畫有調整,我也能直接幫他們更新頁面。
以前這種需求太小、太私人,很難專門做出一款軟體。現在借助 AI,可以很快把需求變成真正能使用的東西。
AI 在這裡不是取代復健師,而是把已確認過的計畫,變成長輩和家人真正能夠執行的工具。
接下來先實際用一段時間,再看看能不能抽象成一個可重複使用,甚至開源的家庭訓練跟練工具。
AI 時代,未來的一切都會是高度客製化的。
查看原文例如我家裡有長輩需要做一段時間的肌肉復健訓練。我把已確認過的動作和強度做成一個專門給他使用的網頁:一打開就能看到今天要練什麼,一畫面一項,直接跟著做。後續如果計畫有調整,我也能直接幫他們更新頁面。
以前這種需求太小、太私人,很難專門做出一款軟體。現在借助 AI,可以很快把需求變成真正能使用的東西。
AI 在這裡不是取代復健師,而是把已確認過的計畫,變成長輩和家人真正能夠執行的工具。
接下來先實際用一段時間,再看看能不能抽象成一個可重複使用,甚至開源的家庭訓練跟練工具。
AI 時代,未來的一切都會是高度客製化的。


- 打賞
- 按讚
- 回覆
- 轉發
- 分享
天气市場的錢從哪來?
很多小眾機會,第一眼都像玩具。
天氣市場尤其像。
城市、目標日期、最高溫/最低溫、溫度閾值或區間、是/否合約(YES / NO),以及等官方結算。
但我自己持續跟了一段時間以後,越來越確定一件事:
這類小眾市場真正的 alpha,通常藏在別人懶得結構化的地方。
這裡的 alpha,指的是「市場裡可能存在的超額收益機會」。
這一期 Leo Insider,我把天氣策略拆成四層:
- 市場覆蓋差;
- 資訊更新差;
- 結算理解差;
- 玩家流差。
最有意思的是第四層。
我把排行榜上長期參與天氣市場的公開地址拉出來,當成研究樣本,也當成外部確認層:
- 同向,說明候選更值得觀察;
- 反向,說明候選需要警惕;
- 無確認,說明它可能只是普通雜訊。
完整版會放:
- 天氣市場四層 alpha 線索;
- 我怎麼搭建候選池;
- 為什麼結算源理解很關鍵;
- 玩家流怎麼做外部確認;
- 為什麼有 alpha 線索,仍然要卡在放大前;
- 一張「小眾策略 alpha 驗證表」。
這期真正想講的是:
一個看起來很窄的市場,怎麼從「好像有機會」,變成一套可驗證的研究流程。
我主要研究的市場入口:Polymarket
很多小眾機會,第一眼都像玩具。
天氣市場尤其像。
城市、目標日期、最高溫/最低溫、溫度閾值或區間、是/否合約(YES / NO),以及等官方結算。
但我自己持續跟了一段時間以後,越來越確定一件事:
這類小眾市場真正的 alpha,通常藏在別人懶得結構化的地方。
這裡的 alpha,指的是「市場裡可能存在的超額收益機會」。
這一期 Leo Insider,我把天氣策略拆成四層:
- 市場覆蓋差;
- 資訊更新差;
- 結算理解差;
- 玩家流差。
最有意思的是第四層。
我把排行榜上長期參與天氣市場的公開地址拉出來,當成研究樣本,也當成外部確認層:
- 同向,說明候選更值得觀察;
- 反向,說明候選需要警惕;
- 無確認,說明它可能只是普通雜訊。
完整版會放:
- 天氣市場四層 alpha 線索;
- 我怎麼搭建候選池;
- 為什麼結算源理解很關鍵;
- 玩家流怎麼做外部確認;
- 為什麼有 alpha 線索,仍然要卡在放大前;
- 一張「小眾策略 alpha 驗證表」。
這期真正想講的是:
一個看起來很窄的市場,怎麼從「好像有機會」,變成一套可驗證的研究流程。
我主要研究的市場入口:Polymarket
POLYMARKET4.39%
- 打賞
- 按讚
- 回覆
- 轉發
- 分享
很多人裝 GitHub 專案前,會先刷一下 Star 數。
Star 只是發現訊號。真正決定能不能裝的,是安裝前的四道門。
拿一個目前只有約 1 個 Star 的倉庫做例子:chungty/unjiggle。
命令是 pip install unjiggle。
用 AI + 它,把 iPhone 304 個 App 整理成了 3 頁。
第一次寫回,系統直接把佈局重排了,以為失敗;第二次完整讀寫才真正穩定下來。
走的路徑是備份 → safety-test → suggest/go,再人工確認每一步。
裝 GitHub 工具前,建議過這四道門:
1. 可執行安裝面
安裝命令是否一行就能跑通?相依和步驟是否真正可執行,不用各種折騰?
2. 近期維護
最近還有更新嗎?作者是否還在處理 issue 和回饋?
3. 權限
它會申請哪些存取權限?權限範圍是否和功能匹配,會不會過度?
4. 可回滾的安全測試
改動前備份了嗎?有沒有 safety-test 或 suggest 模式先看效果?翻車後能不能乾淨回滾?
Star 幫你發現,不幫你驗收。
把這四條記下來,下次再遇到小眾倉庫時,就知道該怎麼判斷了。
查看原文Star 只是發現訊號。真正決定能不能裝的,是安裝前的四道門。
拿一個目前只有約 1 個 Star 的倉庫做例子:chungty/unjiggle。
命令是 pip install unjiggle。
用 AI + 它,把 iPhone 304 個 App 整理成了 3 頁。
第一次寫回,系統直接把佈局重排了,以為失敗;第二次完整讀寫才真正穩定下來。
走的路徑是備份 → safety-test → suggest/go,再人工確認每一步。
裝 GitHub 工具前,建議過這四道門:
1. 可執行安裝面
安裝命令是否一行就能跑通?相依和步驟是否真正可執行,不用各種折騰?
2. 近期維護
最近還有更新嗎?作者是否還在處理 issue 和回饋?
3. 權限
它會申請哪些存取權限?權限範圍是否和功能匹配,會不會過度?
4. 可回滾的安全測試
改動前備份了嗎?有沒有 safety-test 或 suggest 模式先看效果?翻車後能不能乾淨回滾?
Star 幫你發現,不幫你驗收。
把這四條記下來,下次再遇到小眾倉庫時,就知道該怎麼判斷了。
- 打賞
- 按讚
- 回覆
- 轉發
- 分享
現在人人都在讓 AI 寫程式碼,但我今天幹了件更刺激的事——讓它寫了一段會自動花錢、完全無人值守下單的程式碼。
先把決策邏輯寫好,把邊界、最壞情況、kill 條件全想清楚才敢動手。原本想讓 Codex 自己搭執行器,結果派發通道全天不穩,改成我自己主執行緒一點點自建。
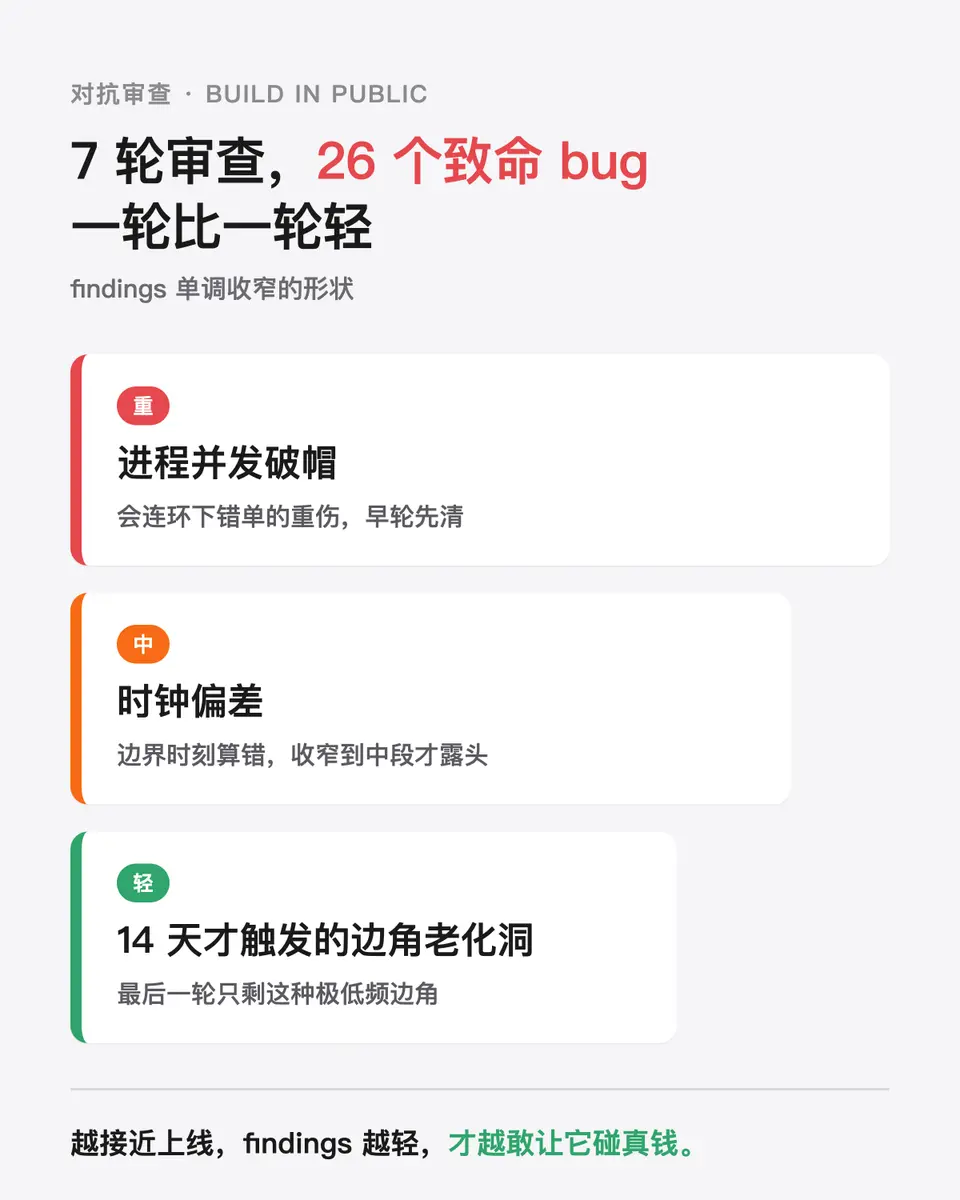
上線前跑了 7 輪對抗式 code review,硬把出 26 個 P0 等級致命 bug。從那種會連環下錯單的程序併發破帽,一輪輪收窄到時鐘偏差,最後只剩 14 天才觸發的邊角老化洞。
部署到 VPS 之後,一個傍晚的真實 canary 又抓到一個白天測全綠、晚上才露面的 bug。
今晚 21:30,首單終於真的放出去了。
說實話,這只是個微額學習實驗。單日曝險大概 10u 左右,設了 30u 硬 kill 線。拿小錢換真實數據和踩坑經驗,不是來搞規模化盈利的。
現在還沒有任何結果,只能說:程式碼上線了,今晚等著驗證。
AI 寫這種會花錢的系統,審查這道坎到底能扛到哪?
查看原文先把決策邏輯寫好,把邊界、最壞情況、kill 條件全想清楚才敢動手。原本想讓 Codex 自己搭執行器,結果派發通道全天不穩,改成我自己主執行緒一點點自建。
上線前跑了 7 輪對抗式 code review,硬把出 26 個 P0 等級致命 bug。從那種會連環下錯單的程序併發破帽,一輪輪收窄到時鐘偏差,最後只剩 14 天才觸發的邊角老化洞。
部署到 VPS 之後,一個傍晚的真實 canary 又抓到一個白天測全綠、晚上才露面的 bug。
今晚 21:30,首單終於真的放出去了。
說實話,這只是個微額學習實驗。單日曝險大概 10u 左右,設了 30u 硬 kill 線。拿小錢換真實數據和踩坑經驗,不是來搞規模化盈利的。
現在還沒有任何結果,只能說:程式碼上線了,今晚等著驗證。
AI 寫這種會花錢的系統,審查這道坎到底能扛到哪?
- 打賞
- 1
- 1
- 轉發
- 分享
scarletxanin:
非常感謝這個X 上那些看起来最夸张的截图和数字,反而是 AI 时代最容易验证的东西。
把原帖和截图交给 AI 深入分析一下,数字口径、证据缺口和前后矛盾,很快就会浮出来。
哪些靠谱,哪些不靠谱,已经没有以前那么难查了。
查看原文把原帖和截图交给 AI 深入分析一下,数字口径、证据缺口和前后矛盾,很快就会浮出来。
哪些靠谱,哪些不靠谱,已经没有以前那么难查了。
- 打賞
- 按讚
- 回覆
- 轉發
- 分享
最近我把多模型路由重新梳理了一遍,加上显式降级回执和人工动作 gate。目标是让系统在模型出问题的时候还能保持可控。
Hugging Face 2026-07-16 官方披露攻击日志超过 17,000 条记录那天,我却发现自托管分析路线在事故当天到底能不能用,根本没检查过。
Hugging Face 团队先用商业 API 的前沿模型来处理这些日志。结果真实攻击命令、漏洞利用载荷和 C2 产物都被安全护栏挡住了。
之后他们切换到自有基础设施上,跑开放权重的 GLM 5.2 才把取证完成。攻击者数据和日志涉及的凭据没有离开环境。
这不是在说要取消安全护栏。护栏继续发挥作用,防守方仍需要一条能在自家环境里走的分析路径。
自托管 forensic canary 目前还没跑通,我只是在准备新增这条能力。
下一步准备做的是:在事故发生前,用安全的惰性样例先把自托管分析路线验证一遍。分析完成,不等于就能获得执行动作的权限。动作始终要继续走人工 gate。
真正有准备的系统,不是事后才发现哪条路走不通,而是在需要它之前就确认每一条都能用。只有提前测过,才能在关键时刻顶上。
查看原文Hugging Face 2026-07-16 官方披露攻击日志超过 17,000 条记录那天,我却发现自托管分析路线在事故当天到底能不能用,根本没检查过。
Hugging Face 团队先用商业 API 的前沿模型来处理这些日志。结果真实攻击命令、漏洞利用载荷和 C2 产物都被安全护栏挡住了。
之后他们切换到自有基础设施上,跑开放权重的 GLM 5.2 才把取证完成。攻击者数据和日志涉及的凭据没有离开环境。
这不是在说要取消安全护栏。护栏继续发挥作用,防守方仍需要一条能在自家环境里走的分析路径。
自托管 forensic canary 目前还没跑通,我只是在准备新增这条能力。
下一步准备做的是:在事故发生前,用安全的惰性样例先把自托管分析路线验证一遍。分析完成,不等于就能获得执行动作的权限。动作始终要继续走人工 gate。
真正有准备的系统,不是事后才发现哪条路走不通,而是在需要它之前就确认每一条都能用。只有提前测过,才能在关键时刻顶上。
- 打賞
- 按讚
- 回覆
- 轉發
- 分享
五天前我把 Claude、Codex、Cursor、Grok 四條 lane 全鎖到最強模型加最高推理檔。想法是既然付了錢,就該把最好的用滿。
五天后發現根本扛不住。額度掉得太快,最強模型拿去做重複的檢查和格式工作,純屬浪費。
現在改了,按判斷密度來分。出錯會虧錢或污染資料的審查、交叉驗證、資金策略這些任務,繼續保留最強席位。日常實作和開發走中檔模型。機械活和摘要,能寫腳本的就先寫腳本。
模型分配只看判斷密度,不看訂閱價格。
你們是怎麼挑不同任務給不同模型的?
查看原文五天后發現根本扛不住。額度掉得太快,最強模型拿去做重複的檢查和格式工作,純屬浪費。
現在改了,按判斷密度來分。出錯會虧錢或污染資料的審查、交叉驗證、資金策略這些任務,繼續保留最強席位。日常實作和開發走中檔模型。機械活和摘要,能寫腳本的就先寫腳本。
模型分配只看判斷密度,不看訂閱價格。
你們是怎麼挑不同任務給不同模型的?

- 打賞
- 按讚
- 回覆
- 轉發
- 分享
很多人看到現實事件已經結束,市場標題寫得一清二楚,甚至價格顯示接近 0 或 1,就以為 Polymarket 這個市場已經最終結算了。
這些訊號本身,其實不能證明市場已經最終敲定。標題只是問題描述,顯示價格也只是當前市場的一種價格反映。
我的判斷門只留一句:先過這六問。任何一項說不清,就跳過這個市場。
1. Rules 到底問什麼。
標題只描述問題,Rules 才決定如何結算。官方明確 Rules 規定 resolution source、end date 與 edge cases。很多人只看標題就覺得結果已經確定,其實 Rules 裡可能還有需要額外確認的邊界條件。
2. 指定 resolution source 是什麼。
市場會明確寫出用哪個來源來判定最終結果。只能用這個指定的來源,不能拿其他新聞報導、社交媒體貼文或者第三方總結來替代。即使其他地方已經到處說結果出來了,也要確認指定源有沒有正式輸出。
3. 截止時間、時區和結束條件是什麼。
End date 只是市場具備提出結算資格的時間點,不等於已經最終結算。具體截止、時區和結束條件以該市場 Rules 為準。最終狀態還要看後續的 proposal、challenge 和 finalization 流程。
4. 取消、延遲、平局、數據修訂等例外怎麼處理。
Rules 裡通常會提前寫明這些
這些訊號本身,其實不能證明市場已經最終敲定。標題只是問題描述,顯示價格也只是當前市場的一種價格反映。
我的判斷門只留一句:先過這六問。任何一項說不清,就跳過這個市場。
1. Rules 到底問什麼。
標題只描述問題,Rules 才決定如何結算。官方明確 Rules 規定 resolution source、end date 與 edge cases。很多人只看標題就覺得結果已經確定,其實 Rules 裡可能還有需要額外確認的邊界條件。
2. 指定 resolution source 是什麼。
市場會明確寫出用哪個來源來判定最終結果。只能用這個指定的來源,不能拿其他新聞報導、社交媒體貼文或者第三方總結來替代。即使其他地方已經到處說結果出來了,也要確認指定源有沒有正式輸出。
3. 截止時間、時區和結束條件是什麼。
End date 只是市場具備提出結算資格的時間點,不等於已經最終結算。具體截止、時區和結束條件以該市場 Rules 為準。最終狀態還要看後續的 proposal、challenge 和 finalization 流程。
4. 取消、延遲、平局、數據修訂等例外怎麼處理。
Rules 裡通常會提前寫明這些
POLYMARKET4.39%
- 打賞
- 按讚
- 回覆
- 轉發
- 分享
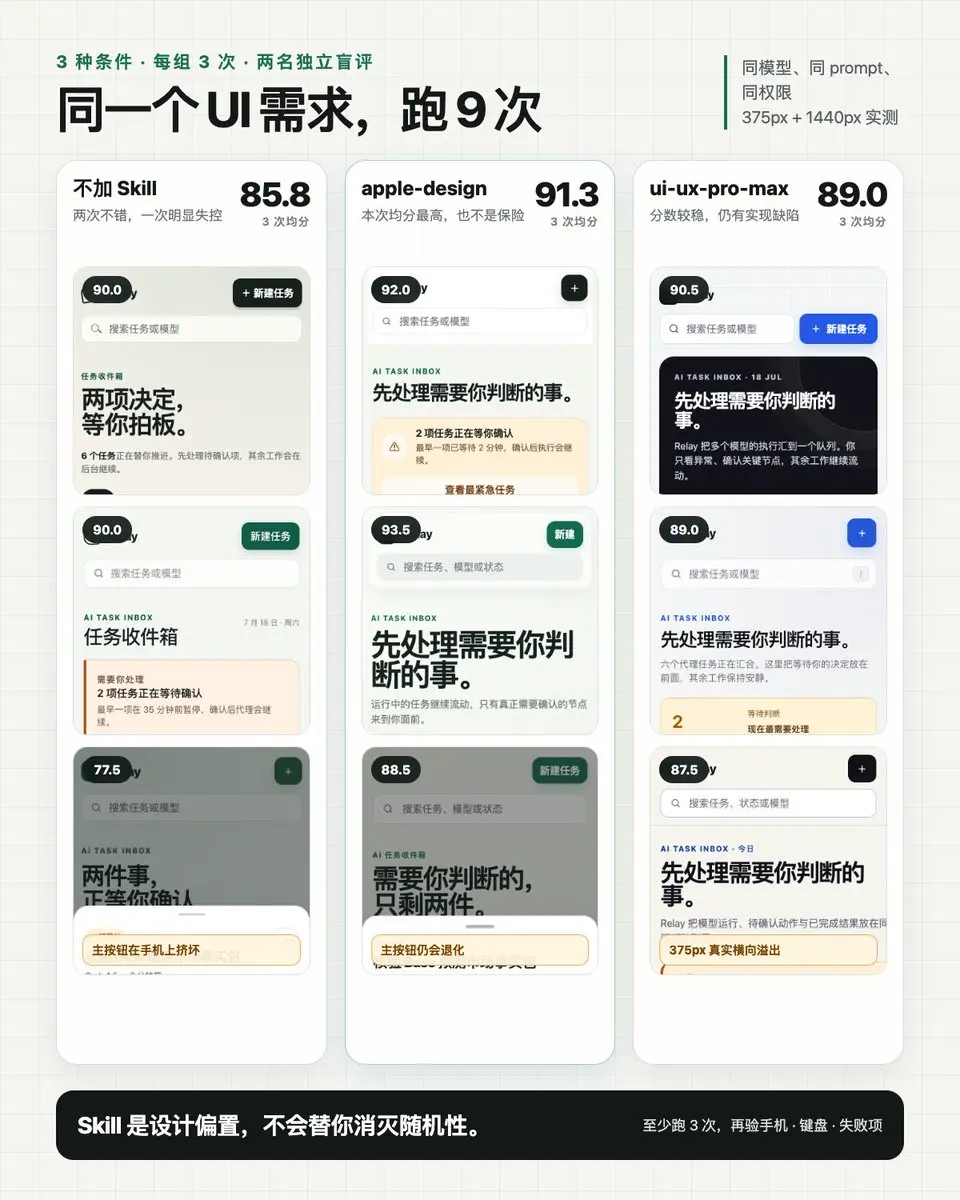
我把同一個 UI 需求交給同一個模型跑了 9 次:不加 Skill、apple-design、ui-ux-pro-max 各 3 次。
結果讓我改變判斷方式:同一套 Skill 也會一次做得很好、一次翻車。
9 份結果匿名後交給兩個人獨立打分,三組的平均分是:
apple-design 91.3
ui-ux-pro-max 89.0
不加 Skill 85.8
但三組都沒做到 3/3 零缺陷。
apple-design 和不加 Skill 各有一次手機詳情頁主按鈕擠壞;ui-ux-pro-max 有一次在 375px 窄螢幕橫向溢出,右側內容被截斷。每組也都漏過無障礙細節:有的是表單沒標籤,有的是圖示按鈕沒名稱。
這次 apple-design 平均分最高,ui-ux-pro-max 波動最小。我會複用的是後面的驗收方法。
以後我不會再拿一張漂亮截圖判斷 Skill:先跑 3 次,再驗手機、鍵盤、減少動態效果和失敗項。對我來說,Skill 更像是設計偏置,不是穩定性保證。
查看原文結果讓我改變判斷方式:同一套 Skill 也會一次做得很好、一次翻車。
9 份結果匿名後交給兩個人獨立打分,三組的平均分是:
apple-design 91.3
ui-ux-pro-max 89.0
不加 Skill 85.8
但三組都沒做到 3/3 零缺陷。
apple-design 和不加 Skill 各有一次手機詳情頁主按鈕擠壞;ui-ux-pro-max 有一次在 375px 窄螢幕橫向溢出,右側內容被截斷。每組也都漏過無障礙細節:有的是表單沒標籤,有的是圖示按鈕沒名稱。
這次 apple-design 平均分最高,ui-ux-pro-max 波動最小。我會複用的是後面的驗收方法。
以後我不會再拿一張漂亮截圖判斷 Skill:先跑 3 次,再驗手機、鍵盤、減少動態效果和失敗項。對我來說,Skill 更像是設計偏置,不是穩定性保證。
- 打賞
- 按讚
- 回覆
- 轉發
- 分享
AI 工作流程最危險的失敗,不是直接報錯。
是主模型掛了,後備也沒成,
系統卻仍吐出一段看起來完整的結果,讓人誤以為已經做完了。
我踩過一次:每日資訊處理時,主模型跑到 60 秒被掐斷,後備也沒成功,最後仍拿到一份像模像樣的抽取文字。問題不在「換一條路繼續試」,而在換路之後沒人把該說清楚的講清楚。
後來我給每次完成加了三項回執,缺一只能標待核驗,不能標完成:
1. 最終實際使用的:____(哪個模型 / 哪條服務)
2. 每次嘗試結果:____(成功 / 超時 / 錯誤)
3. 目前輸出狀態:____(正常生成 / 明確降級 / 失敗)
換路可以,但必須寫進結果、能夠復查。靜默完成,比報錯更危險。
查看原文是主模型掛了,後備也沒成,
系統卻仍吐出一段看起來完整的結果,讓人誤以為已經做完了。
我踩過一次:每日資訊處理時,主模型跑到 60 秒被掐斷,後備也沒成功,最後仍拿到一份像模像樣的抽取文字。問題不在「換一條路繼續試」,而在換路之後沒人把該說清楚的講清楚。
後來我給每次完成加了三項回執,缺一只能標待核驗,不能標完成:
1. 最終實際使用的:____(哪個模型 / 哪條服務)
2. 每次嘗試結果:____(成功 / 超時 / 錯誤)
3. 目前輸出狀態:____(正常生成 / 明確降級 / 失敗)
換路可以,但必須寫進結果、能夠復查。靜默完成,比報錯更危險。

- 打賞
- 按讚
- 回覆
- 轉發
- 分享
如何公開製作(build in public)?
今天讓 AI 從早忙到晚,把任務、研究、腳本和佇列推進了不少,結果在 X 上還是沒什麼可發的。內容系統就像完全沒有在選題一樣。
16 號發了 8 則內容,17 號做了更多實際工作,可見供給卻明顯掉下來了。
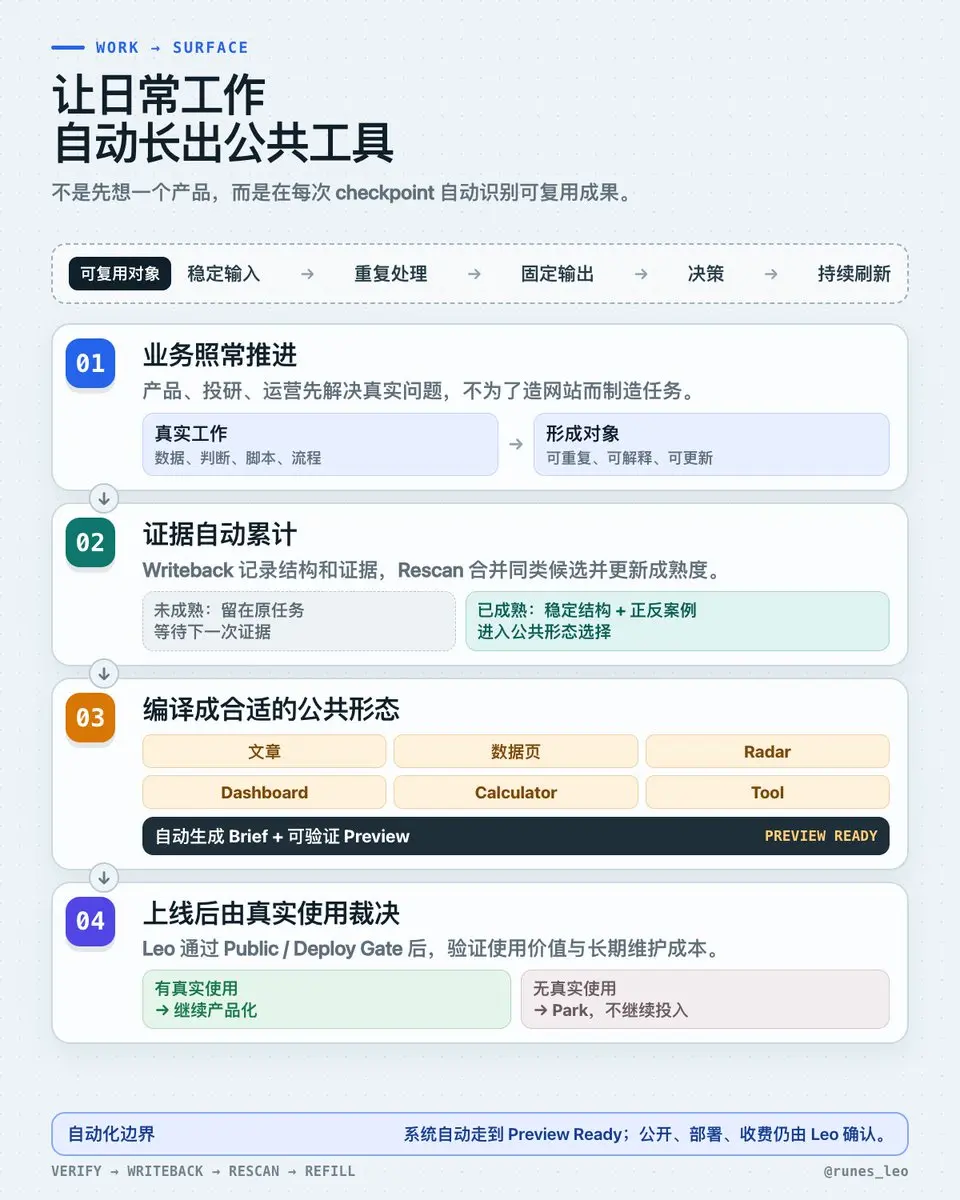
因此我做了 Work → Surface v1。
它通過了 19/19 測試,並且讀取並驗證了 99 張 live task card。目前只有一個成熟的 reusable object,能自動派生出 2 個 preview-ready packet。
系統不會自動公開、部署或收費,這些環節仍然需要我手動確認。
內部任務全綠、外部完全看不見,仍然是內容系統的失敗。真正缺的不是再去找更多外部選題,而是讓已經驗證過的工作繼續走到可見的 surface 上。之前這些工作都停在內部流程裡,看不見就等於沒發生過。不是從日誌自動猜內容,而是在 verify writeback 時必須明確寫好 reusable objects,後面的自動化才會生效。
查看原文今天讓 AI 從早忙到晚,把任務、研究、腳本和佇列推進了不少,結果在 X 上還是沒什麼可發的。內容系統就像完全沒有在選題一樣。
16 號發了 8 則內容,17 號做了更多實際工作,可見供給卻明顯掉下來了。
因此我做了 Work → Surface v1。
它通過了 19/19 測試,並且讀取並驗證了 99 張 live task card。目前只有一個成熟的 reusable object,能自動派生出 2 個 preview-ready packet。
系統不會自動公開、部署或收費,這些環節仍然需要我手動確認。
內部任務全綠、外部完全看不見,仍然是內容系統的失敗。真正缺的不是再去找更多外部選題,而是讓已經驗證過的工作繼續走到可見的 surface 上。之前這些工作都停在內部流程裡,看不見就等於沒發生過。不是從日誌自動猜內容,而是在 verify writeback 時必須明確寫好 reusable objects,後面的自動化才會生效。
- 打賞
- 按讚
- 回覆
- 轉發
- 分享