Raveena
#TrumpDelaysIranStrike, 以分析和政治评论的风格撰写。它不包含任何外部或非法链接,结构为详细叙述。
特朗普推迟对伊朗的打击:战略决策还是政治计算?
在最近在媒体和网络平台上传播的政治讨论中,“特朗普推迟对伊朗的打击”这一短语成为一个有争议且备受争论的话题。无论被解读为实时政策决定、假设场景还是投机的地缘政治叙事,这一想法都引发了关于军事战略、国际关系、国内政治和全球稳定的重要问题。
这一讨论的核心在于:现代政治中,关于战争与和平的决策是如何形成的,尤其是在美国与伊朗等国家紧张关系中。推迟军事打击的概念从来都不简单。它涉及情报评估、外交压力、军事准备、政府内部辩论以及外部全球反应的多个层面。
军事决策的战略分量
对伊朗的潜在打击不仅是地区问题;它是一个全球性热点。伊朗在中东占据关键的地缘政治位置,邻近重要的能源通道,并影响多个地区冲突。任何涉及伊朗的军事行动都可能扰乱石油市场,破坏邻国稳定,并引发更广泛的地区升级,涉及盟国和对手。
在这种背景下,推迟此类打击的决定具有重要意义。它可能表明谨慎、重新评估情报,或试图避免立即升级。军事打击很少是冲动行为。它们通常经过多层评估,包括潜在的报复场景、平民风险评估和外交后果。
因此,推迟可以根据政治视角以多种方式解读。支持克制的人可能视之为负责任的领导,优先考虑和平与稳定而非立即对抗。而批评者则可能将其解读为在不断升高的紧
查看原文特朗普推迟对伊朗的打击:战略决策还是政治计算?
在最近在媒体和网络平台上传播的政治讨论中,“特朗普推迟对伊朗的打击”这一短语成为一个有争议且备受争论的话题。无论被解读为实时政策决定、假设场景还是投机的地缘政治叙事,这一想法都引发了关于军事战略、国际关系、国内政治和全球稳定的重要问题。
这一讨论的核心在于:现代政治中,关于战争与和平的决策是如何形成的,尤其是在美国与伊朗等国家紧张关系中。推迟军事打击的概念从来都不简单。它涉及情报评估、外交压力、军事准备、政府内部辩论以及外部全球反应的多个层面。
军事决策的战略分量
对伊朗的潜在打击不仅是地区问题;它是一个全球性热点。伊朗在中东占据关键的地缘政治位置,邻近重要的能源通道,并影响多个地区冲突。任何涉及伊朗的军事行动都可能扰乱石油市场,破坏邻国稳定,并引发更广泛的地区升级,涉及盟国和对手。
在这种背景下,推迟此类打击的决定具有重要意义。它可能表明谨慎、重新评估情报,或试图避免立即升级。军事打击很少是冲动行为。它们通常经过多层评估,包括潜在的报复场景、平民风险评估和外交后果。
因此,推迟可以根据政治视角以多种方式解读。支持克制的人可能视之为负责任的领导,优先考虑和平与稳定而非立即对抗。而批评者则可能将其解读为在不断升高的紧
- 赞赏
- 1
- 2
- 转发
- 分享
ybaser:
直达月球 🌕查看更多
包括交易所内我还有一点Form
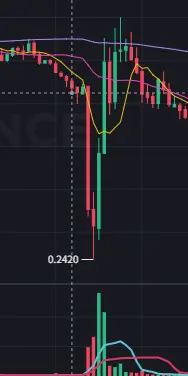
前两天闪崩到0.24
是我直接又买到了0.26
前两天闪崩到0.24
是我直接又买到了0.26
- 赞赏
- 点赞
- 评论
- 转发
- 分享


- 赞赏
- 点赞
- 评论
- 转发
- 分享
黄金以太双管齐下,今日爽吃剧本开启?
2,768
- 赞赏
- 点赞
- 评论
- 转发
- 分享
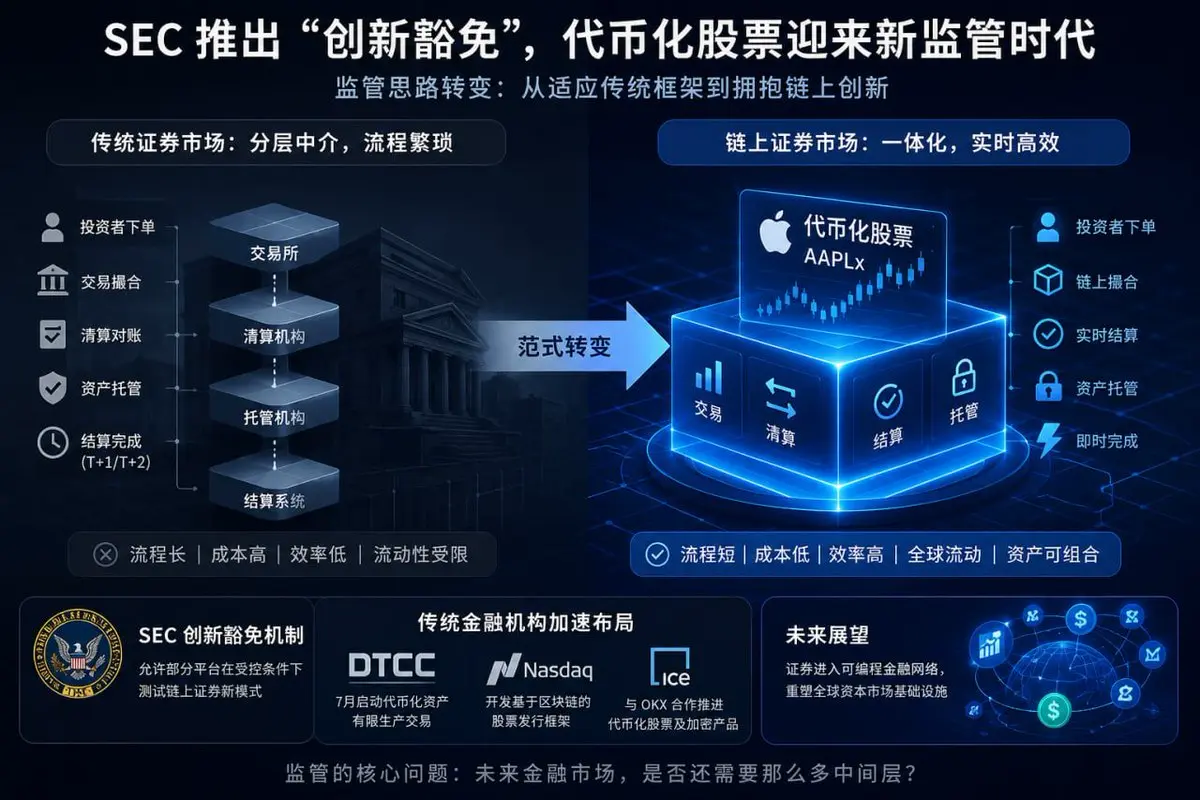
这次SEC准备推出创新豁免机制,表面上是在支持代币化股票,但更深层的变化,其实是美国监管开始承认,链上证券已经很难继续套用传统金融那套框架。
传统证券市场依赖大量中间层。交易、清算、托管、结算彼此分离,因为传统系统里资产确认需要时间,所以才会有 T+1、清算周期和资金冻结这些流程。
但链上不一样。
在区块链里,交易发生的同时,结算和所有权更新其实已经同步完成。也就是说,链上天然就是交易、清算、结算一体化,而这恰恰和现有证券监管逻辑存在冲突。
所以这次SEC的创新豁免,本质上是在允许部分平台暂时跳出旧框架,测试新的链上证券模式。这也是为什么现在不只是Crypto项目在推动代币化,DTCC、纳斯达克、ICE这些传统金融机构也都开始布局。
因为他们真正看中的,并不是Crypto 概念,而是链上带来的资本效率。
未来如果证券全面链上化,最大的变化可能不是24小时交易,而是全球资产开始进入同一套可编程金融网络。股票、稳定币、借贷、衍生品之间的边界会越来越模糊。
而SEC现在真正要面对的问题,其实是未来金融市场,是否还需要那么多中间层。
#SEC #创新豁免
传统证券市场依赖大量中间层。交易、清算、托管、结算彼此分离,因为传统系统里资产确认需要时间,所以才会有 T+1、清算周期和资金冻结这些流程。
但链上不一样。
在区块链里,交易发生的同时,结算和所有权更新其实已经同步完成。也就是说,链上天然就是交易、清算、结算一体化,而这恰恰和现有证券监管逻辑存在冲突。
所以这次SEC的创新豁免,本质上是在允许部分平台暂时跳出旧框架,测试新的链上证券模式。这也是为什么现在不只是Crypto项目在推动代币化,DTCC、纳斯达克、ICE这些传统金融机构也都开始布局。
因为他们真正看中的,并不是Crypto 概念,而是链上带来的资本效率。
未来如果证券全面链上化,最大的变化可能不是24小时交易,而是全球资产开始进入同一套可编程金融网络。股票、稳定币、借贷、衍生品之间的边界会越来越模糊。
而SEC现在真正要面对的问题,其实是未来金融市场,是否还需要那么多中间层。
#SEC #创新豁免
NAS100-0.47%
- 赞赏
- 点赞
- 评论
- 转发
- 分享
突发:🇮🇳
印度的汽油和柴油价格再次上涨近90派士每升,这是一周内的第二次涨价。
查看原文印度的汽油和柴油价格再次上涨近90派士每升,这是一周内的第二次涨价。

- 赞赏
- 点赞
- 评论
- 转发
- 分享
💰 $LIT 突破
🔼 多头
✳️ 进入点:0.9800 – 0.9540 – 0.9280
🎯 目标:1.010 – 1.040 – 1.095 – 1.155 – 1.205 – 1.250 – 1.300
🀄️ 杠杆:10倍
🔴 止损:0.9040
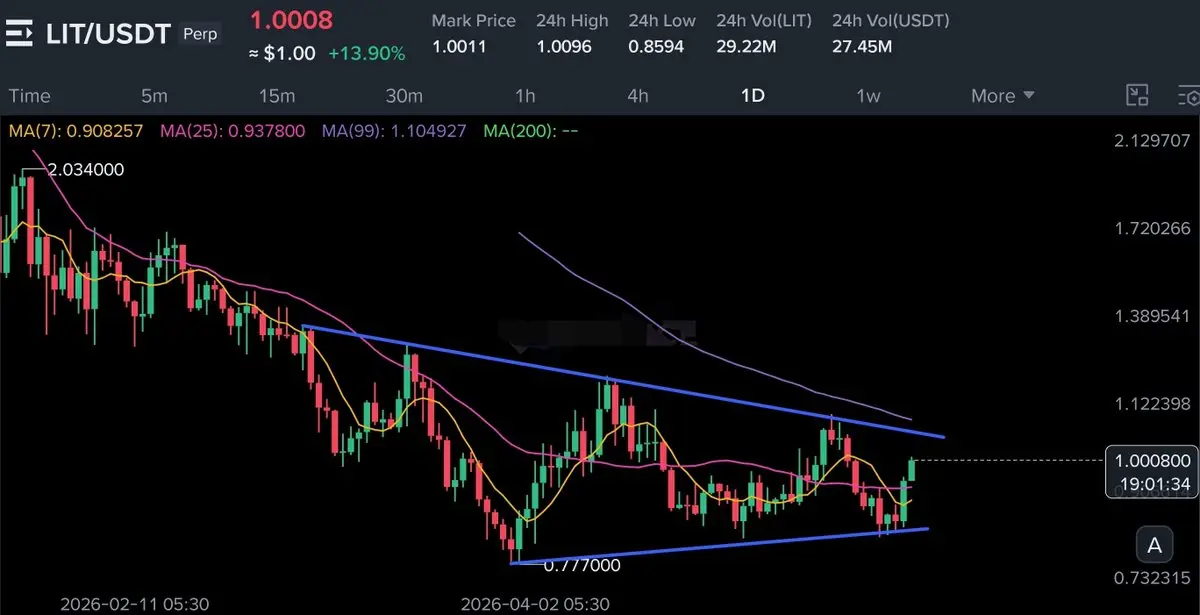
#LIT 正在以强劲的成交量突破多月的下降趋势线,确认市场结构的看涨转变。价格已收复MA7和MA25(现在都向上倾斜),而MA99位于上方,作为下一个主要阻力位。RSI在恢复,展现出看涨的动能和更高的低点,而MACD显示出早期的看涨交叉信号,柱状图在扩大。我们看到在0.95–0.98区域出现经典的阻力转支撑的反转,买家在近期回调中积极防守,形成了清晰的更高低点。这次由成交量支撑的突破,经过长时间的压缩,为高概率的趋势反转和持续向上奠定基础。在任何健康的回调中,分批在三个均匀间隔的点进行DCA,逐步在每个目标获利,剩余部分跟踪止盈。强烈的反转布局,风险回报极佳——让我们乘着这股动能浪前行。
🔼 多头
✳️ 进入点:0.9800 – 0.9540 – 0.9280
🎯 目标:1.010 – 1.040 – 1.095 – 1.155 – 1.205 – 1.250 – 1.300
🀄️ 杠杆:10倍
🔴 止损:0.9040
#LIT 正在以强劲的成交量突破多月的下降趋势线,确认市场结构的看涨转变。价格已收复MA7和MA25(现在都向上倾斜),而MA99位于上方,作为下一个主要阻力位。RSI在恢复,展现出看涨的动能和更高的低点,而MACD显示出早期的看涨交叉信号,柱状图在扩大。我们看到在0.95–0.98区域出现经典的阻力转支撑的反转,买家在近期回调中积极防守,形成了清晰的更高低点。这次由成交量支撑的突破,经过长时间的压缩,为高概率的趋势反转和持续向上奠定基础。在任何健康的回调中,分批在三个均匀间隔的点进行DCA,逐步在每个目标获利,剩余部分跟踪止盈。强烈的反转布局,风险回报极佳——让我们乘着这股动能浪前行。
LIT15.25%
- 赞赏
- 点赞
- 评论
- 转发
- 分享
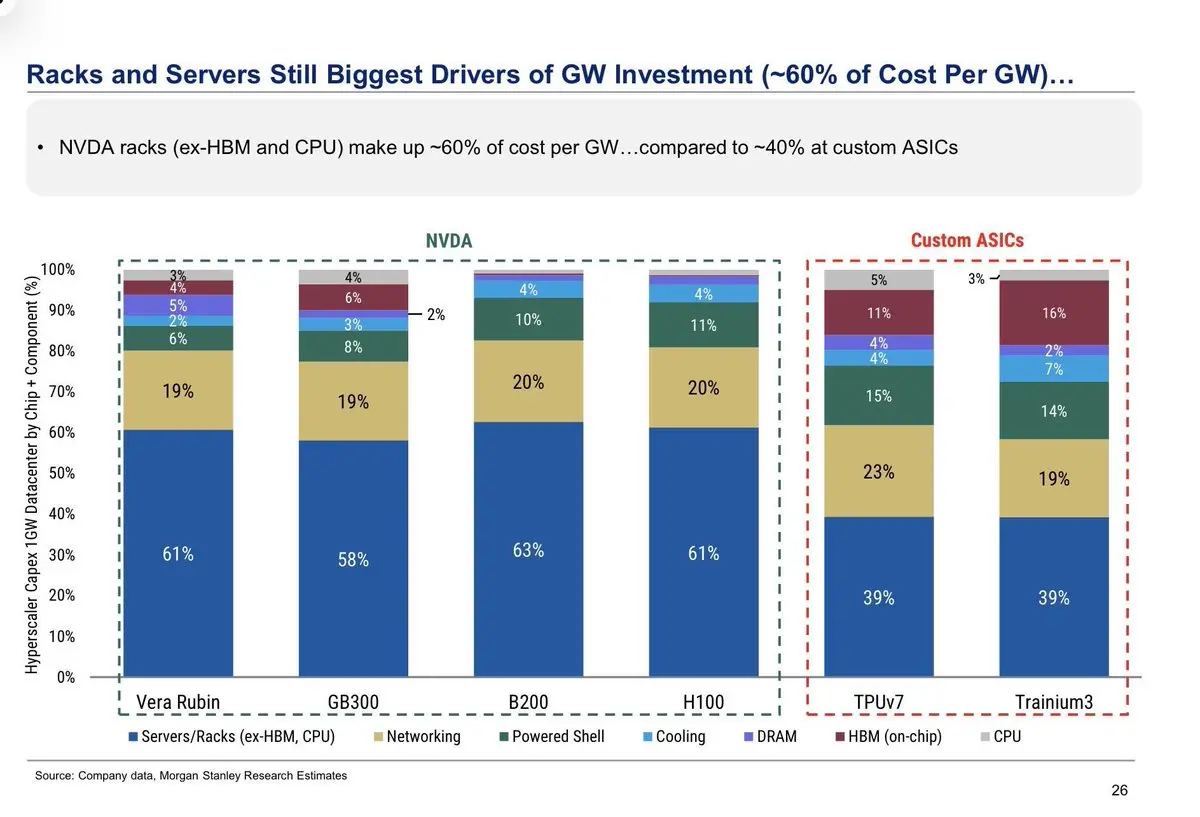
摩根士丹利大中华区半导体研究于2026年5月8日发布了一份新报告。
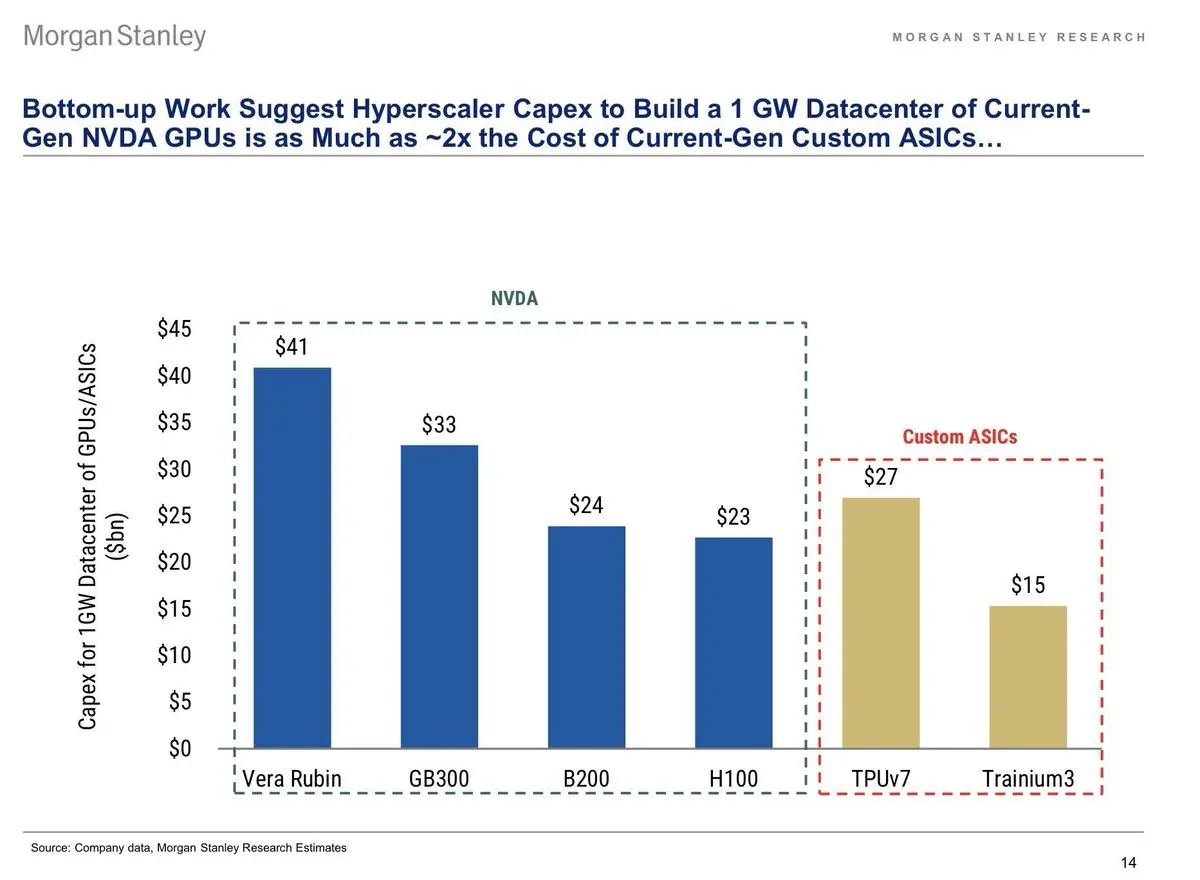
-> 机架和服务器仍然是最大的资本支出(capex)驱动因素,约占1GW数据中心总成本的58–63%(不包括HBM和CPU)。
-> 对于定制ASIC而言,机架和服务器的占比要低得多,约为总成本的39%。这也是超大规模云服务提供商持续推动内部硅片的最清晰原因。
-> 摩根士丹利估算,1GW NVIDIA GPU数据中心的成本为:
Vera Rubin:~$NVDA
GB300:~$41B
B200:~$33B
H100:~$24B
相比定制ASIC:
TPUv7:~$23B
Trainium3:~$27B
-> 当前一代NVIDIA系统的每GW成本可能比定制ASIC高出多达~2倍。以这一估算来看,Vera Rubin几乎是Trainium3的3倍。
-> 这并不意味着定制ASIC会自动更优。NVIDIA依然拥有最强的全栈生态系统、软件、网络、可用性和模型支持。但这也说明了为什么超大规模云服务提供商在扩大ASIC规模方面具有巨大的经济激励。
-> 第二大成本类别是网络,约占大多数系统的19–23%。
-> Power shell、冷却、DRAM、HBM和CPU都很重要,但相较于机架、服务器和网络而言,它们是次要因素。
-> 这对机架规模基础设施供
查看原文-> 机架和服务器仍然是最大的资本支出(capex)驱动因素,约占1GW数据中心总成本的58–63%(不包括HBM和CPU)。
-> 对于定制ASIC而言,机架和服务器的占比要低得多,约为总成本的39%。这也是超大规模云服务提供商持续推动内部硅片的最清晰原因。
-> 摩根士丹利估算,1GW NVIDIA GPU数据中心的成本为:
Vera Rubin:~$NVDA
GB300:~$41B
B200:~$33B
H100:~$24B
相比定制ASIC:
TPUv7:~$23B
Trainium3:~$27B
-> 当前一代NVIDIA系统的每GW成本可能比定制ASIC高出多达~2倍。以这一估算来看,Vera Rubin几乎是Trainium3的3倍。
-> 这并不意味着定制ASIC会自动更优。NVIDIA依然拥有最强的全栈生态系统、软件、网络、可用性和模型支持。但这也说明了为什么超大规模云服务提供商在扩大ASIC规模方面具有巨大的经济激励。
-> 第二大成本类别是网络,约占大多数系统的19–23%。
-> Power shell、冷却、DRAM、HBM和CPU都很重要,但相较于机架、服务器和网络而言,它们是次要因素。
-> 这对机架规模基础设施供
- 赞赏
- 点赞
- 评论
- 转发
- 分享
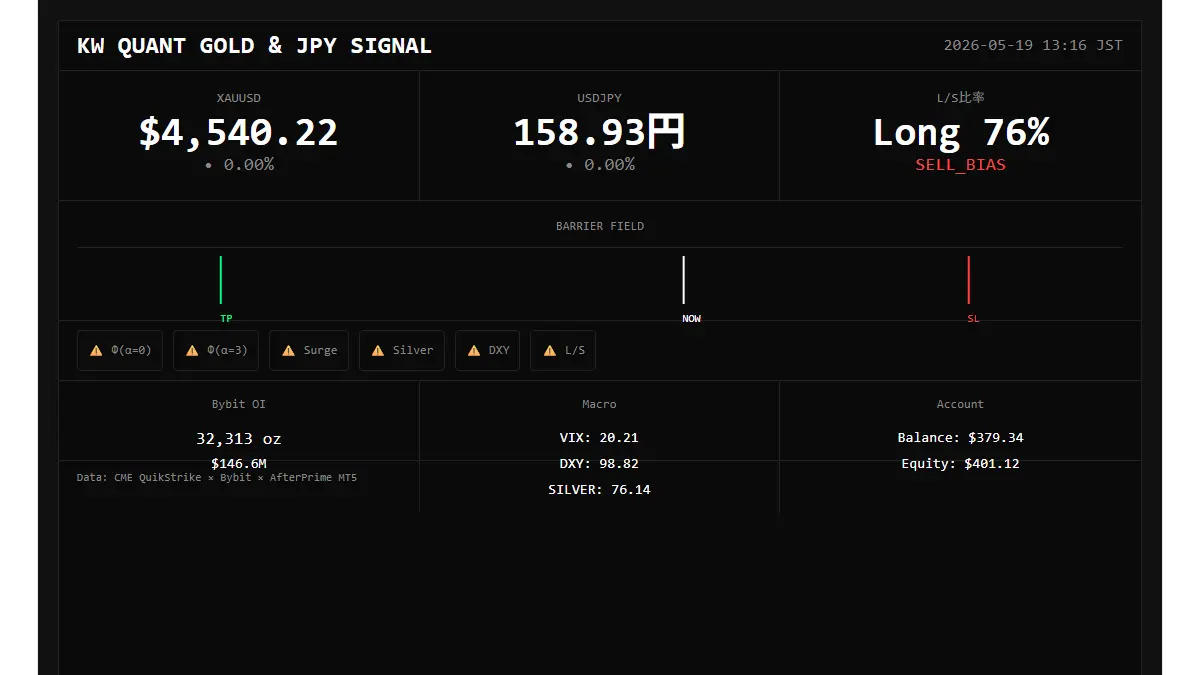
🔴 KW QUANT 信号提醒
卖出 #XAUUSD
止损:4572.68 | 目标:4486.70
评分:ko-20260519041601-Call-4630
障碍期权磁场理论 × Kyle(1985)
05/19 04:16 UTC
#Gold #XAUUSD #SystemTrading
卖出 #XAUUSD
止损:4572.68 | 目标:4486.70
评分:ko-20260519041601-Call-4630
障碍期权磁场理论 × Kyle(1985)
05/19 04:16 UTC
#Gold #XAUUSD #SystemTrading
XAU-0.06%
- 赞赏
- 点赞
- 评论
- 转发
- 分享
#GateAprilTransparencyReport
全球市场环境与结构转变
2026年4月标志着全球加密生态系统的决定性转型阶段,市场结构逐渐从短期投机周期转向长期基础设施估值模型。在此期间,资金轮动变得日益明显,投资者优先考虑提供多层次实用性的平台,包括交易基础设施、人工智能集成、实体资产连接和机构级执行系统。
数字资产市场的整体情绪仍然复杂,宏观不确定性、流动性波动和周期性杠杆平仓事件推动了波动的交替。尽管如此,具有强大生态系统深度和多元化产品结构的中心化交易所仍然表现出韧性,用户参与度和资金留存持续增长。
在所有主要平台中,Gate脱颖而出,成为一个高性能生态系统,交易活动、生态参与和机构资金流入在多个垂直领域同步扩大,反映出从孤立交易行为向一体化金融生态系统使用的结构性转变。
用户基础增长与全球普及扩展
2026年4月,Gate在全球注册用户数突破5300万,达到了一个重要里程碑,代表了集中交易所行业中增长最快的采用曲线之一。
最大增长贡献来自亚洲、中东、欧洲和拉丁美洲,这些地区的金融数字化、监管明晰、改善以及对替代资产敞口需求的增加,持续推动加密货币的规模化采用。
目前,Gate支持超过4600种数字资产,使其成为全球市场中资产多样性最高的流动性生态系统之一。这一广泛的资产覆盖使用户能够在统一的交易环境中访问多个市场板块,包括大型市值加密货币、中型代币、新兴叙事和
查看原文全球市场环境与结构转变
2026年4月标志着全球加密生态系统的决定性转型阶段,市场结构逐渐从短期投机周期转向长期基础设施估值模型。在此期间,资金轮动变得日益明显,投资者优先考虑提供多层次实用性的平台,包括交易基础设施、人工智能集成、实体资产连接和机构级执行系统。
数字资产市场的整体情绪仍然复杂,宏观不确定性、流动性波动和周期性杠杆平仓事件推动了波动的交替。尽管如此,具有强大生态系统深度和多元化产品结构的中心化交易所仍然表现出韧性,用户参与度和资金留存持续增长。
在所有主要平台中,Gate脱颖而出,成为一个高性能生态系统,交易活动、生态参与和机构资金流入在多个垂直领域同步扩大,反映出从孤立交易行为向一体化金融生态系统使用的结构性转变。
用户基础增长与全球普及扩展
2026年4月,Gate在全球注册用户数突破5300万,达到了一个重要里程碑,代表了集中交易所行业中增长最快的采用曲线之一。
最大增长贡献来自亚洲、中东、欧洲和拉丁美洲,这些地区的金融数字化、监管明晰、改善以及对替代资产敞口需求的增加,持续推动加密货币的规模化采用。
目前,Gate支持超过4600种数字资产,使其成为全球市场中资产多样性最高的流动性生态系统之一。这一广泛的资产覆盖使用户能够在统一的交易环境中访问多个市场板块,包括大型市值加密货币、中型代币、新兴叙事和

- 赞赏
- 1
- 评论
- 转发
- 分享
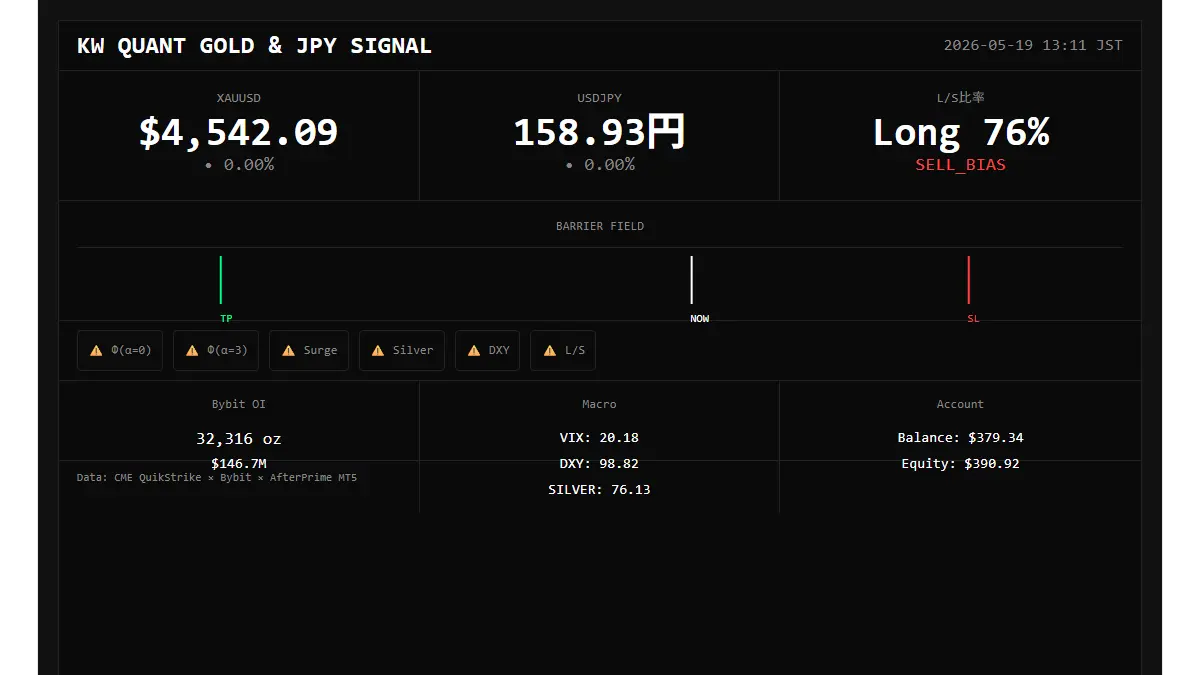
🔴 KW QUANT 信号提醒
卖出 #XAUUSD
止损:4573.28 | 止盈:4488.21
评分:ko-20260519041106-看涨-4630
屏障期权磁场理论 × Kyle(1985)
05/19 04:11 UTC
#Gold #XAUUSD #系统交易
卖出 #XAUUSD
止损:4573.28 | 止盈:4488.21
评分:ko-20260519041106-看涨-4630
屏障期权磁场理论 × Kyle(1985)
05/19 04:11 UTC
#Gold #XAUUSD #系统交易
XAUUSD-0.55%
- 赞赏
- 点赞
- 评论
- 转发
- 分享
剩下的粉丝不活跃是干什么去了
- 赞赏
- 点赞
- 评论
- 转发
- 分享
$ETH 信号:反弹高空策略,1H多头动能遇4H压制
$ETH 1H MACD多头柱持续扩大,价格站上布林中轨2121。4H级别EMA20/50空头排列,上方抛压密集。资金费率0.0079%中性,深度偏卖-5.35%。反弹至高位后再布局空单更稳妥。
🎯方向:做空(挂单)
⚡入场/挂单:2226.48
🛑止损:2244.29
🚀目标1:2190.86
🚀目标2:2173.04
🛡️交易管理:
- 执行策略:到达目标1后减仓50%,并将止损下移至保本位。若价格反弹到入场位附近受阻,可考虑提前离场。
深度逻辑:4H RSI 36.5处于弱势区间,反弹幅度受限于EMA20(2161)与EMA50(2215)的压制。1H虽现金叉,但上方卖盘厚度压制反弹空间,盈亏比在挂单位置有吸引力。
查看实时行情 👇 $ETH
---
关注我:获取更多加密市场实时分析与洞察!
#TradFi交易分享挑战 #PYTH今日解锁21.3亿枚代币 $BTC $ETH $SOL
$ETH 1H MACD多头柱持续扩大,价格站上布林中轨2121。4H级别EMA20/50空头排列,上方抛压密集。资金费率0.0079%中性,深度偏卖-5.35%。反弹至高位后再布局空单更稳妥。
🎯方向:做空(挂单)
⚡入场/挂单:2226.48
🛑止损:2244.29
🚀目标1:2190.86
🚀目标2:2173.04
🛡️交易管理:
- 执行策略:到达目标1后减仓50%,并将止损下移至保本位。若价格反弹到入场位附近受阻,可考虑提前离场。
深度逻辑:4H RSI 36.5处于弱势区间,反弹幅度受限于EMA20(2161)与EMA50(2215)的压制。1H虽现金叉,但上方卖盘厚度压制反弹空间,盈亏比在挂单位置有吸引力。
查看实时行情 👇 $ETH
---
关注我:获取更多加密市场实时分析与洞察!
#TradFi交易分享挑战 #PYTH今日解锁21.3亿枚代币 $BTC $ETH $SOL
- 赞赏
- 点赞
- 评论
- 转发
- 分享
由于我这两天有事,没开直播,我这两天给的位置都是我周日的,2160空单,完美第二止盈2100,2080-2090的多单给了两次 第一次2150完美止盈,第二次也吃上了,行情目前也属于一种震荡行情,我从高位2290就开始做空,2230也是空2216也是空,2160也是空,都有空单在,群里也一直都有说,跟上的都吃爽了,虽然中间有两次10几个点打损 但是吃上的不知道有多少,这个月初的3号开始连续3天多空双杀也都吃爽了,昨天也是多空双杀,其中2-30个点的小肉就不说了,每天看我直播 位置的知道,有些人不会做单的 仓位控制不好的还给爆仓了,我也有些无语,位置都给的这么好了,仓都不知道翻了多少倍了,你们不会的多学学,白白交给市场,天天送,看了我也是觉得可惜,我希望你们跟上我脚步的人 不说天天能吃多少 但是起码别给我亏就行,稳住脚步慢慢前行,心急吃不了热豆腐,有合适点位就开,保险一定要上好,吃上的恭喜了,没吃上甚至还亏的那不好意思了,给的位置只有那么好了$ETH
ETH0.72%

- 赞赏
- 1
- 评论
- 转发
- 分享
- 赞赏
- 1
- 1
- 转发
- 分享
sinan3551:
$skyai ?【$DYM 信号】1H回调接多,4H多头结构未破
$DYM RSI 1H 60.89,4H MACD柱线仍在扩张,但1H MACD快慢线粘合,短期动能衰竭。卖盘深度占比略高,资金费率0.005%偏低,多头杠杆不拥挤。当前价0.02483已高于建议区间,等待回踩挂单更合理。
🎯方向:做多(挂单)
⚡入场/挂单:0.02471
🛑止损:0.02338
🚀目标1:0.02485
🚀目标2:0.02494
🛡️交易管理:- 到达目标1减仓50%,止损移至入场价。若价格跌破0.02471,立即离场。
利润空间狭窄,盈亏比不理想,但止损极近,适合小仓位博弈反弹延续。
查看实时行情 👇 $DYM
---
关注我:获取更多加密市场实时分析与洞察!
#TradFi交易分享挑战 #PYTH今日解锁21.3亿枚代币 $BTC $ETH $SOL
$DYM RSI 1H 60.89,4H MACD柱线仍在扩张,但1H MACD快慢线粘合,短期动能衰竭。卖盘深度占比略高,资金费率0.005%偏低,多头杠杆不拥挤。当前价0.02483已高于建议区间,等待回踩挂单更合理。
🎯方向:做多(挂单)
⚡入场/挂单:0.02471
🛑止损:0.02338
🚀目标1:0.02485
🚀目标2:0.02494
🛡️交易管理:- 到达目标1减仓50%,止损移至入场价。若价格跌破0.02471,立即离场。
利润空间狭窄,盈亏比不理想,但止损极近,适合小仓位博弈反弹延续。
查看实时行情 👇 $DYM
---
关注我:获取更多加密市场实时分析与洞察!
#TradFi交易分享挑战 #PYTH今日解锁21.3亿枚代币 $BTC $ETH $SOL
- 赞赏
- 点赞
- 评论
- 转发
- 分享
追求一生的东西在刚出生就拥有了
好像什么都有了,怎么就是不开心呢?
好像什么都有了,怎么就是不开心呢?

- 赞赏
- 点赞
- 评论
- 转发
- 分享
加载更多
加入 4000 万人汇聚的头部社区
⚡️ 与 4000 万 人一起参与加密货币热潮讨论
💬 与喜爱的头部博主互动
👍 查看感兴趣的内容
热门话题
查看更多13.1万 热度
92.35万 热度
100.61万 热度
1608.18万 热度
165.64万 热度
快讯
查看更多置顶
📢 Gate 广场 TradFi 交易分享挑战上线!
晒单瓜分 $30,000 奖池,新人首帖 100% 中奖!
📌 参与方式:
带 #TradFi交易分享挑战 发帖,满足以下任一即可:
🔹 带今日指定 TradFi 币种标签发帖交流。
🔹 完成单笔大于 $10U 的 TradFi CFD 交易并挂载交易卡片。
🏷️ 今日指定标签:USDJPY、AUDUSD、US30、TSLA、JPN225
🎁 宠粉福利:
1️⃣ 卡片分享奖: 抽 50 人,每人送 $100 仓位体验券!
2️⃣ 发帖榜单奖: 冲排行榜,赢 WCTC 限定 T 恤!
3️⃣ 新粉见面礼: 新人首次发帖,100% 领 $10 体验券!
详情:https://www.gate.com/announcements/article/51221🍕 Gate 广场披萨节正式开启!
14 年前,有人用 10,000 BTC 买下了两个披萨。
今天,这两个披萨已经价值数十亿美元。
值此 BTC Pizza Day 之际,Gate 广场邀请整个社区一起分享 BTC 故事、Meme、脑洞与交易观点!
🎁 活动奖励:
✅ Gate Pizza Day 周边礼盒 ×10
✅ 每日 5 份 10 USDT 幸运披萨奖励
📌 在 Gate 广场发帖,并同步分享至 X:
Meme、BTC 故事、Pizza 创意图、BTC 晒单等内容均可参与
立即发布你的 BTC 故事👇
👉️ https://www.gate.com/post
📅 活动时间:5 月 18 日 - 5 月 24 日
详情:https://www.gate.com/zh/announcements/article/51210
#Gate广场披萨节 #BTC10,000 USDT 悬赏,寻找Gate广场跟单金牌星探!🕵️♀️
挖掘顶级带单员,赢取高额跟单体验金!
立即参与:https://www.gate.com/campaigns/4624
🎁 三大活动,奖金叠满:
1️⃣ 慧眼识英:发帖推荐带单员,分享跟单体验,抽 100 位送 30 USDT!
2️⃣ 强力应援:晒出你的跟单截图,为大神打 Call,抽 120 位送 50 USDT!
3️⃣ 社交达人:同步至 X/Twitter,凭流量赢取 100 USDT!
📍 标签: #跟单金牌星探 #GateCopyTrading
⏰ 限时: 4/22 16:00 - 5/10 16:00 (UTC+8)
详情:https://www.gate.com/announcements/article/50848✍️ Gate 广场「创作者认证激励计划」持续招募中!
广场发帖创作,即可瓜分每月 $10,000+ 奖励!
豪华代币奖池、Gate 周边、专属推广与千万级流量曝光等你拿!
广场认证创作者、其他平台优质创作者均可报名
立即填写表单报名 👉 https://www.gate.com/questionnaire/7159
让优质内容被更多人看到,一起共建创作者社区!
活动详情:https://www.gate.com/announcements/article/47889
创作者认证申请详情:https://www.gate.com/help/community-center/moments/47731/gate-square-creator-certification-guidelines